YMatrix
Quick Start
Connecting
Benchmarks
Deployment
Data Usage
Data Ingestion
Data Migration
Data Query
Manage Clusters
Upgrade
Global Maintenance
Expansion
Monitoring
Security
Best Practice
Technical Principles
Data Type
Storage Engine
Execution Engine
Streaming Engine(Domino)
MARS3 Index
Extension
Advanced Features
Advanced Query
Federal Query
Grafana
Backup and Restore
Disaster Recovery
Graph Database
Introduction
Clauses
Functions
Advanced
Guide
Performance Tuning
Troubleshooting
Tools
Configuration Parameters
SQL Reference
MARS3 Bucket is a storage-layer parallel execution optimization mechanism designed by YMatrix for parallel scan scenarios in MPP architectures. By organizing data into multiple logical buckets based on hash values of the distribution key during the write phase, it ensures that data sharing the same distribution key is processed by the same worker during parallel scans. This preserves data distribution semantics (locus), eliminates unnecessary data redistribution (Motion), and achieves a performance leap from "scanning faster" to "computing more locally."
Bucket is mainly suitable for large tables that benefit from parallel scans, especially hash-distributed tables where aggregations or joins use the distribution key and unnecessary Motion should be avoided. For small tables, temporary tables, or tables that are rarely scanned in parallel, Bucket usually provides limited benefit and can add file, metadata, and background governance overhead.
Follow these guidelines when configuring nbuckets:
nbuckets value should not exceed the number of CPU cores per node divided by the number of Segments per node.rowstore_size and table size, and avoid buckets smaller than 2 MB.nbuckets at table creation whenever possible. Changing nbuckets later rewrites the entire table and is not recommended as a routine tuning method.nbuckets for them has no effect.The goal of MARS3 Bucket is to maintain strong data locality after parallel scanning, enabling more computations to complete locally.
Building upon traditional distribution—which determines which data node stores specific data—MARS3 Bucket further organizes data within each node into structured buckets. This ensures that data belonging to the same bucket is output by a single worker.
The fundamental difference between the MARS3 Bucket approach and standard page-preemptive parallel scanning is that internal segment processing becomes organized. Parallel scanning evolves from simply having multiple workers read data concurrently to collaboratively reading data according to distribution semantics.
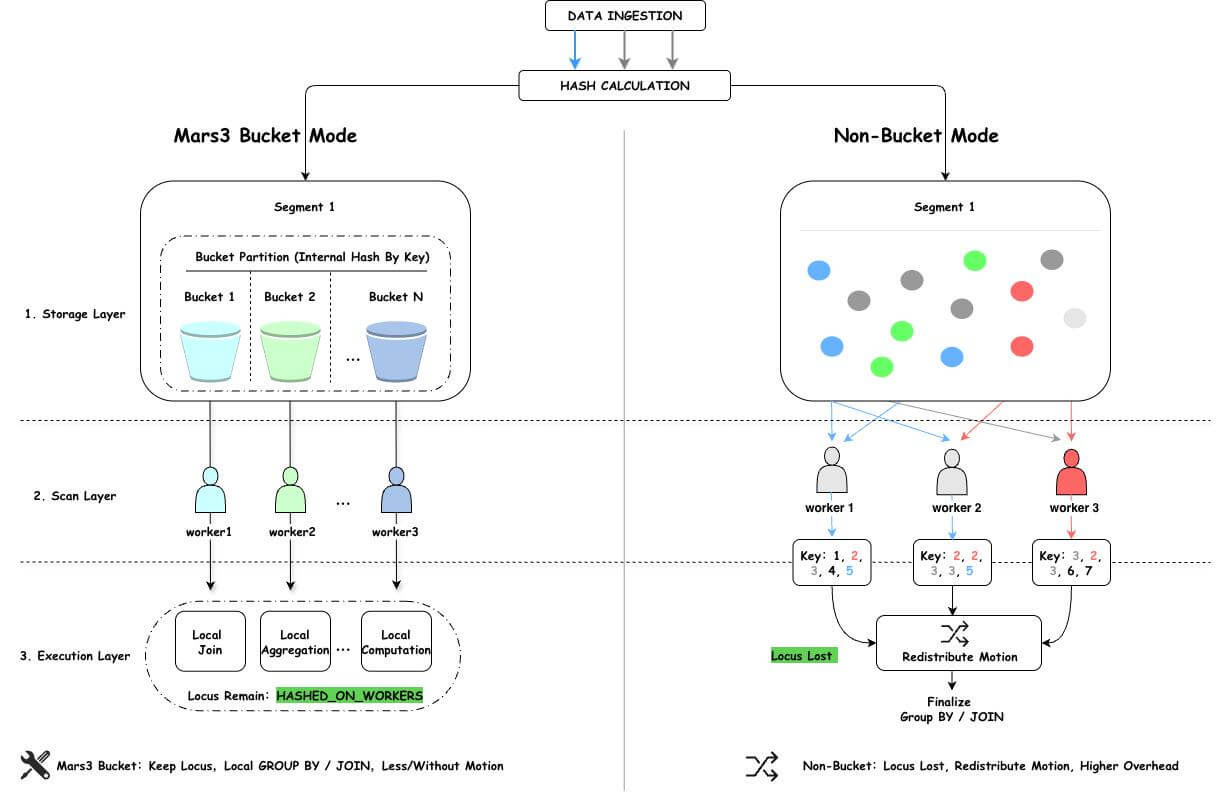
Consider a table t_sales with distribution key c1. The following SQL is executed: select c1, count(*) from t_sales group by c1;
In a standard parallel scenario (without Bucket mode), the execution plan is as follows:
Gather Motion 12:1
-> Finalize HashAggregate
Group Key: c1
-> Redistribute Motion 12:12
Hash Key: c1
-> Partial HashAggregate
Group Key: c1
-> Parallel Seq Scan on t_salesc1 value is processed by a single worker.c1 value may still be scattered across multiple workers after partial aggregation, data must be redistributed based on c1 to ensure correct final aggregation results.Simply put: The issue is not the table's distribution method itself, but rather that parallel scanning disrupts the original data distribution rules required for direct aggregation. To correct this, the optimizer must add an extra data redistribution step, directly diminishing the performance benefits expected from parallel execution.
With MARS3 Bucket, the execution plan is simplified:
Gather Motion 12:1
-> HashAggregate
Group Key: c1
-> Parallel Custom Scan (MxVScan) In the YMatrix database, data is distributed and stored across various data nodes (Segments) according to specific rules. All data across these nodes collectively forms the complete dataset. When defining a table, a distribution key must be specified. During insertion, the system calculates a hash value based on this key and maps the result to a specific data node. Therefore, when tables share the same distribution key, identical data is guaranteed to reside on the same node. This allows operations such as joins and aggregations based on the distribution key to perform the vast majority of work locally without data movement. We refer to this phenomenon as data co-locality.
From the perspective of the entire table, YMatrix employs an MPP architecture where processes scan data on each Segment. This level of parallelism refers to instance-wide parallelism.
From the perspective of a specific table within a particular Segment, multiple processes can participate in scanning the data simultaneously. This level of parallelism refers to intra-node parallelism.