In MARS3, the sort key is a critical design element that determines whether the storage engine can achieve optimal scan efficiency and maintain long-term stability. Ordered data combined with reliable block-level metadata significantly enhances scan performance.
The core benefits of sort keys can be categorized into five areas:
WHERE clauses align closely with the sort key (e.g., time ranges, device ID ranges), data exhibits stronger clustering at the storage layer. Queries can skip irrelevant data blocks earlier and more precisely, reducing I/O and CPU consumption.Organize data using the query dimensions that are most common and provide the strongest filtering effect. In practice, sort key selection typically combines two dimensions:
Columns frequently used in filter conditions should appear earlier in the sort key.
WHERE clauses as the leftmost prefix of the sort key.In short, ensure that the most common query conditions can narrow the scan range to contiguous, clustered intervals.
Consider a real-world customer case in a time-series scenario with the following query:
SELECT time_bucket_gapfill ('5 min', time) AS bucket_time,
locf (LAST (value, time)) AS last_value,
locf (LAST (quality, time)) AS last_quality,
locf (LAST (flags, time)) AS last_flags
FROM
xxx
WHERE
id = '116812373032966284'
AND type = 'ANA'
AND time >= '2025-11-16 00:00:00.000'
AND time <= '2025-11-16 23:59:59.000'
GROUP BY
bucket_time;Results indicate that different sort keys significantly impact index scan performance, functioning similarly to composite indexes.
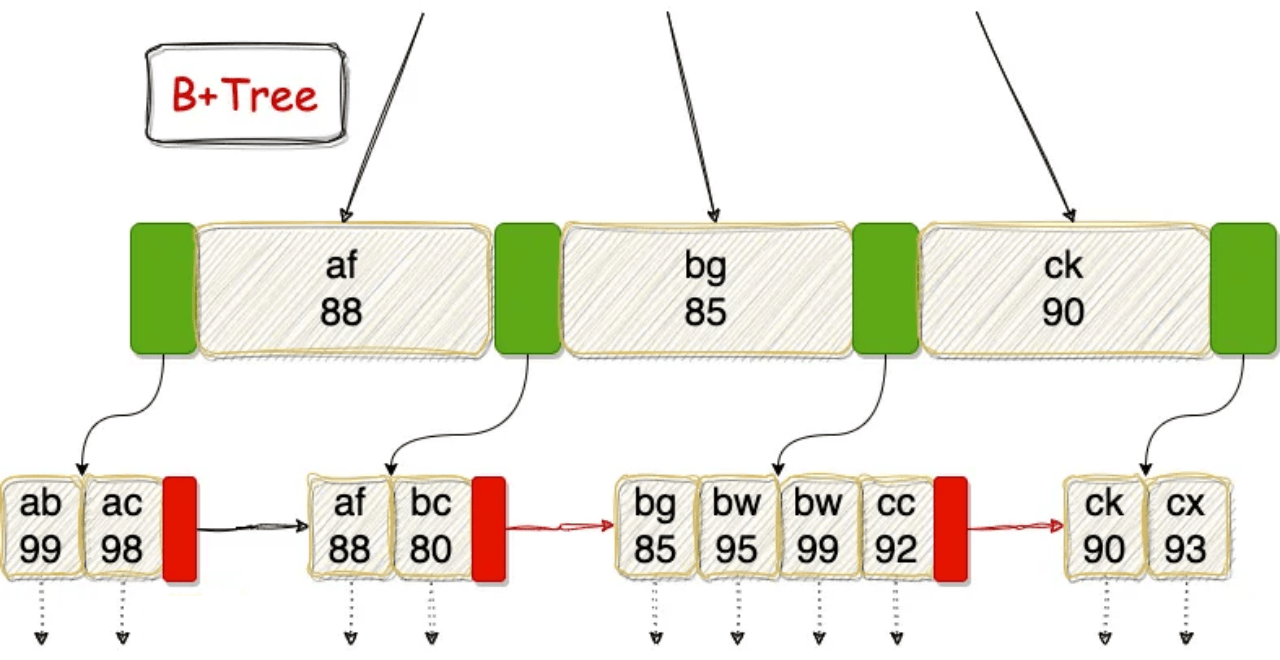
When the time field is placed first, tuples with the same ID are scattered across the storage space over time. Consequently, index scans must perform numerous random reads to retrieve the corresponding data blocks. However, when the ID is placed first, all tuples belonging to the same ID are stored in adjacent locations. This drastically reduces random I/O, as the index scan only needs to read a few contiguous blocks.
Data is sorted during the conversion from Rowstore to Columnstore. The Rowstore itself is unsorted; however, if a B-Tree index exists on the Rowstore, that index remains ordered. Specifying a sort key incurs the following overhead:
Not specifying a sort key avoids this overhead, often resulting in lighter write operations. However, sort keys also affect the natural organization of data on disk:
CREATE TABLE t_w0_nosort (
id bigint NOT NULL,
k1 bigint NOT NULL, -- High cardinality
k2 smallint NOT NULL, -- Low cardinality
k3 bigint NOT NULL, -- Monotonic column (simulating increment with bigint)
v1 double precision NOT NULL,
v2 double precision NOT NULL,
payload text NOT NULL -- Controls write volume: recommend 256B/1024B
) USING mars3;
CREATE TABLE t_w1_1key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k3);
CREATE TABLE t_w3a_3key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k1, k3, k2);
CREATE TABLE t_w3b_3key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k3, k1, k2);Construct intermediate dataset:
DROP TABLE IF EXISTS t_src_s;
CREATE TABLE t_src_s USING MARS3 AS
SELECT
g AS id,
(hashint8(g)::bigint) AS k1,
(g % 64)::smallint AS k2,
g AS k3,
(g % 1000) * 0.01 AS v1,
(g % 10000) * 0.001 AS v2,
repeat('x', 256) AS payload
FROM generate_series(1, 200000000) g;
TRUNCATE t_w0_nosort;
\timing on
INSERT INTO t_w0_nosort SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w1_1key;
\timing on
INSERT INTO t_w1_1key SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w3a_3key;
\timing on
INSERT INTO t_w3a_3key SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w3b_3key;
\timing on
INSERT INTO t_w3b_3key SELECT * FROM t_src_s;
\timing offRestart the database after each test to compare write times:
adw=# TRUNCATE t_w0_nosort;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w0_nosort SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 76859.371 ms (01:16.859)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w1_1key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w1_1key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 82864.008 ms (01:22.864)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w3a_3key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w3a_3key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 106929.500 ms (01:46.930)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w3b_3key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w3b_3key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 83456.346 ms (01:23.456)
adw=# \timing off Write Times:
t_w0_nosort (No Sort): 76.859 st_w1_1key (ORDER BY k3): 82.864 st_w3a_3key (ORDER BY k1,k3,k2): 106.930 st_w3b_3key (ORDER BY k3,k1,k2): 83.456 sThroughput:
t_w0_nosort: 200,000,000 / 76.859 ≈ 2.60M rows/st_w1_1key: 200,000,000 / 82.864 ≈ 2.41M rows/st_w3a_3key: 200,000,000 / 106.930 ≈ 1.87M rows/st_w3b_3key: 200,000,000 / 83.456 ≈ 2.40M rows/sOverhead Relative to No Sort:
Placing the monotonic column k3 as the first sort key reduces the write cost of multi-column sorting to nearly that of single-column sorting.
Placing the high-cardinality random column k1 first significantly increases write costs.
Why is "No Sort" the fastest?
Avoiding sorting, comparison, and ordered maintenance minimizes foreground write overhead, establishing the baseline throughput (2.60M rows/s).
Why is ORDER BY (k3) only slightly slower?
The input stream is already incremental by k3. Since the sort key matches the input order, the system mostly performs sequential writes with minimal additional metadata maintenance overhead, resulting in only ~8% slowdown.
Why is ORDER BY (k1,k3,k2) significantly slower?
Sorting prioritizes k1, which is a high-cardinality, near-random column. This scatters the entire write stream across the key space:
Why is ORDER BY (k3,k1,k2) comparable to single-column sort performance?
The first sort key k3 aligns with the input stream, allowing the system to maximize natural ordering:
k3.k1 and k2 are only involved in deeper comparisons when k3 values are identical or very close, significantly reducing comparison and re-sorting pressure.
Consequently, its performance is nearly identical to ORDER BY (k3) (2.40M vs 2.41M rows/s).adw=# \dt+
List of relations
Schema | Name | Type | Owner | Storage | Size | Description
--------+-------------+-------+---------+---------+---------+-------------
public | t_default | table | mxadmin | mars3 | 160 kB |
public | t_sort_bad | table | mxadmin | mars3 | 103 MB |
public | t_sort_good | table | mxadmin | mars3 | 35 MB |
public | t_src_s | table | mxadmin | mars3 | 3040 MB |
public | t_w0_nosort | table | mxadmin | mars3 | 2769 MB |
public | t_w1_1key | table | mxadmin | mars3 | 2764 MB |
public | t_w3a_3key | table | mxadmin | mars3 | 3453 MB |
public | t_w3b_3key | table | mxadmin | mars3 | 2764 MB |
public | testmars3 | table | mxadmin | mars3 | 160 kB |
(9 rows)Return to previous section: Storage Engine Principles