YMatrix
Quick Start
Connecting
Benchmarks
Deployment
Data Usage
Data Ingestion
Data Migration
Data Query
Manage Clusters
Upgrade
Global Maintenance
Expansion
Monitoring
Security
Best Practice
Technical Principles
Data Type
Storage Engine
Execution Engine
Streaming Engine(Domino)
MARS3 Index
Extension
Advanced Features
Advanced Query
Federal Query
Grafana
Backup and Restore
Disaster Recovery
Graph Database
Introduction
Clauses
Functions
Advanced
Guide
Performance Tuning
Troubleshooting
Tools
Configuration Parameters
SQL Reference
Unique Mode is a specialized writing model in MARS3 designed to transform "update a record" operations into "insert a new record with the same unique key." The storage engine automatically handles the replacement of old versions with new versions for the same key value.
The core value of this mode is enabling applications to express update semantics using a simpler, unified write path (INSERT) in high-frequency write scenarios. This reduces the overhead and complexity of explicit UPDATE statements while maintaining better control over data organization during continuous writes.
Applicable Scenarios:
DELETE operations (or can express invalidity/expiry through other means).In Unique Mode, the unique key is defined by the table's sort key (ORDER BY (...)). When a new record is inserted with a Unique Key matching an existing record, the engine treats this as an update to that key. No explicit UPDATE statement is required; a direct INSERT achieves the update semantics.
Unlike traditional UPSERT (INSERT ... ON CONFLICT), Unique Mode performs merging at read time.
COMPACT process.Consequently, the write efficiency of Unique Mode is significantly higher than traditional UPSERT. Benchmarks indicate that Unique Mode performance is approximately 1.5 times faster than traditional UPSERT.
In Unique Mode scenarios involving re-writing the same key:
new_jsonb = jsonb_concat(old_jsonb, incoming_jsonb). The database internally calls jsonb_concat to perform the merge.Examples:
postgres=# SELECT jsonb_concat('[1,2]'::jsonb, '[2,3]'::jsonb);
jsonb_concat
--------------
[1, 2, 2, 3]
(1 row)
postgres=# SELECT jsonb_concat('{"k":1,"x":2}'::jsonb, '{"k":null}'::jsonb);
jsonb_concat
---------------------
{"k": null, "x": 2}
(1 row)
postgres=# SELECT jsonb_concat('{"a":1,"b":2}'::jsonb, '{"b":99,"c":3}'::jsonb);
jsonb_concat
---------------------------
{"a": 1, "b": 99, "c": 3}
(1 row)This allows applications using JSONB for dynamic attributes, extension fields, or tags to write only incremental changes. The engine handles the merging, avoiding the complexity and concurrency conflicts associated with reading old values, merging them at the application layer, and writing them back.
event_id and ensure uniqueness at the application layer, or use an object/map structure to overwrite by key.null (e.g., {"k": null}) updates the value to null; it does not remove the key.Why UpdateChain? To ensure correctness during concurrent updates to the same row.
In standard PostgreSQL Heap tables, an update is not an in-place modification. Instead, the old tuple is marked as deleted, and a new tuple is inserted. The ctid links the old version to the new one, forming an update chain.
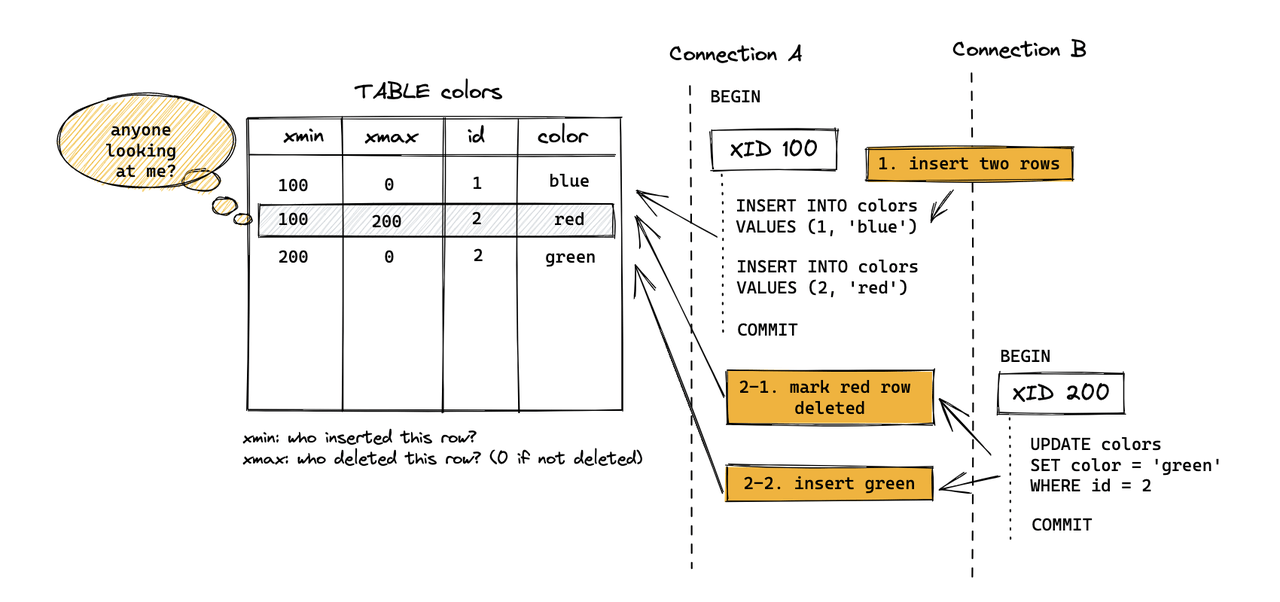
In MARS3, delete/update markers are not stored in the tuple header (like xmax in Heap). Instead, they are recorded in Delta files. To ensure this information persists after compaction or flushing, Link files are used.
ctid links (version pointers are embedded in the data itself).Early versions of MARS3 would error out during concurrent updates to the same row due to the lack of UpdateChain support. With the introduction of UpdateChain, MARS3 now uses TupleLock to lock logical rows and traverses the update chain to locate the latest version. This ensures concurrent updates proceed sequentially, guaranteeing correct UPDATE semantics.
Similar to PostgreSQL, YMatrix implements updates and deletes via Multiversion Concurrency Control (MVCC) rather than modifying data in place:
DELETE operation records the deletion in the Delta file of the corresponding Run. The data is physically removed only during Run merging.UPDATE operation effectively deletes the original data and inserts a new record.Dead tuples (invisible runs) generated during updates and deletes are cleaned up by the background autovacuum process. Manual VACUUM can also be executed. Additionally, during the COMPACT process, as smaller Runs merge into larger ones, invisible runs are removed.
VACUUM FULL goes further by merging multiple small Runs into a single large Run. If no new writes occur, running VACUUM FULL will aggressively merge batches until no further merges are possible. Ultimately, the size of each remaining batch will approximate the configured max_runsize value. Note that VACUUM FULL itself may generate some invisible runs during the process.
Summary:
VACUUM: Flushes data, removes invisible runs, and writes down rowstore data.VACUUM FULL: Performs all actions of VACUUM plus aggressive merging of Runs.Return to previous section: Storage Engine Principles