

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
部署数据库
使用数据库
管理集群
最佳实践
高级功能
高级查询
联邦查询
Grafana 监控
备份恢复
灾难恢复
图数据库
管理手册
性能调优
故障诊断
工具指南
系统配置参数
SQL 参考
Apache Kafka 是一个开源分布式事件流平台,它可以被当作是一个消息系统,读写流式数据,帮助发布、订阅消息;也可以用于编写可扩展的流处理应用程序,来应付实时响应的场景;还可以与数据库对接,安全的将流式数据存储在一个分布式,有副本备份,可容错的集群中。可以说,它所生产的“事件流”是信息数据传输的“中枢神经”。
如果你正打算用 Kafka 将数据写入 YMatrix 集群,请不要错过这篇文档。YMatrix 数据库支持 Kafka 无缝连接功能,可将 Kafka 数据持续自动导入到 YMatrix 表中,并支持图形化界面操作。 目前接入的数据格式可以是 CSV 和 JSON。我们将以一个最简单的例子,来介绍如何用 YMatrix 管理平台接入 Kafka 数据。
首先你需要搭建一个健康的 Kafka 环境,参照官方指南 Kafka Quickstart 即可。
现在,你已经在服务器上搭建好了 Kafka 环境,你可以通过以下命令或其他方式进入。
$ cd packages/kafka_2.13-3.2.0然后启动 Kafka 服务并创建一个测试主题(Topic),端口号默认为 9092。
$ bin/kafka-topics.sh --create --topic csv_test --bootstrap-server localhost:9092然后分条写入几个测试数据,以 ctrl-c 结束:
$ bin/kafka-console-producer.sh --topic csv_test --bootstrap-server localhost:9092
>1,Beijing,123.05,true,1651043583,1651043583123,1651043583123456
>2,Shanghai,112.95,true,1651043583,1651043583123,1651043583123456
>3,Shenzhen,100.0,false,1651043583,1651043583123,1651043583123456
>4,Guangxi,88.5,false,1651043583,1651043583123,1651043583123456
>^C通过上面命令向新创建的 csv_test 写入了4条数据,分别为 4 条逗号分割的 CSV 行。 准备工作完毕,下面将介绍如何创建 Kafka 数据流来导入数据。
在浏览器里输入 MatrixGate 所在机器的 IP(默认是主节点的 IP)、端口号:
http://<IP>:8240成功登录之后进入主界面,界面分为进程视图和任务视图,进程视图是指已开启的 MatrixGate 进程,任务视图是指所有导入数据的任务。其中,一个 MatrixGate 进程可以包含多个任务。
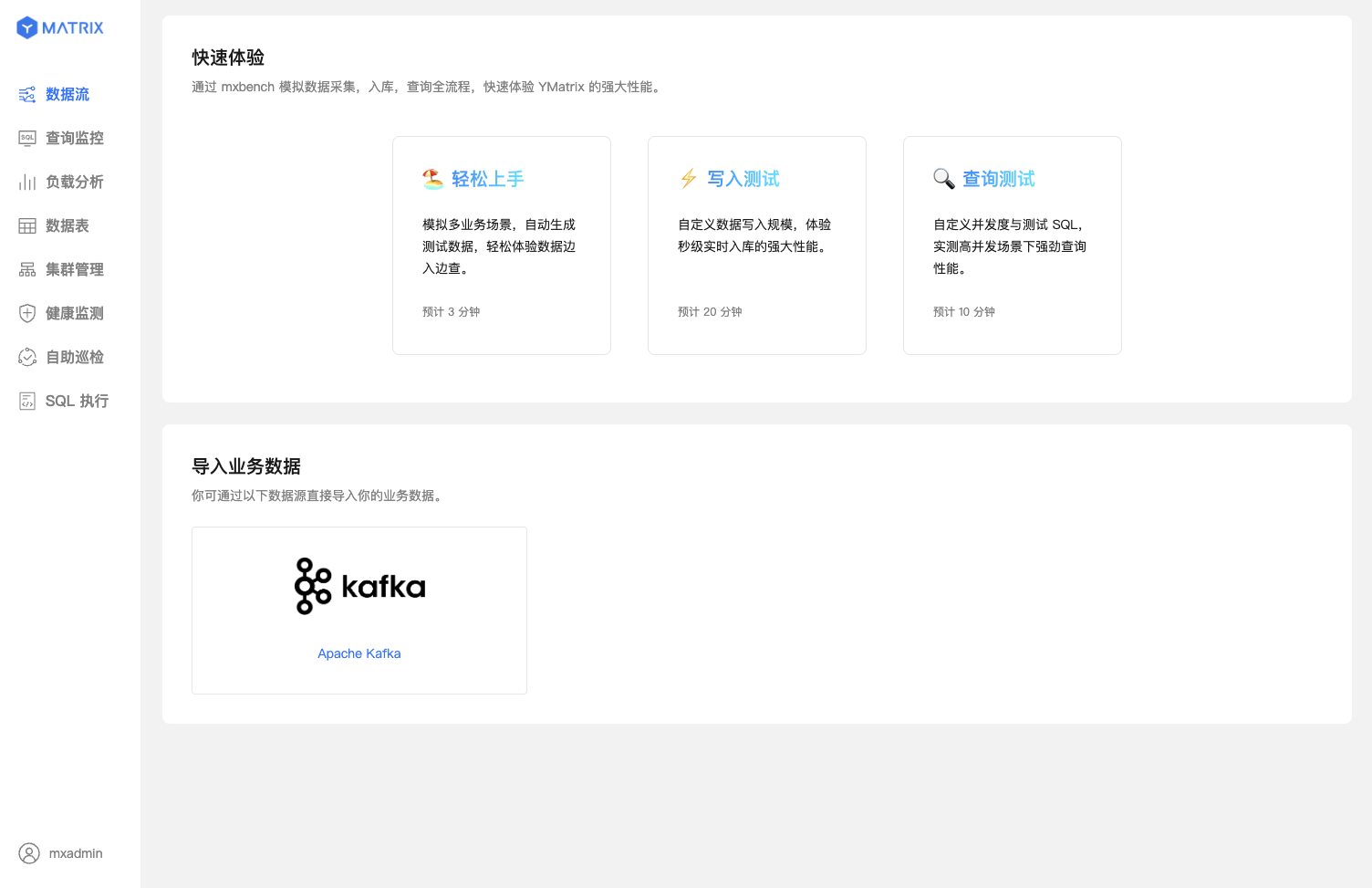
点击“从 Kafka 中导入数据”。
选择 Kafka 数据源。首先以 CSV 文件为例说明步骤。
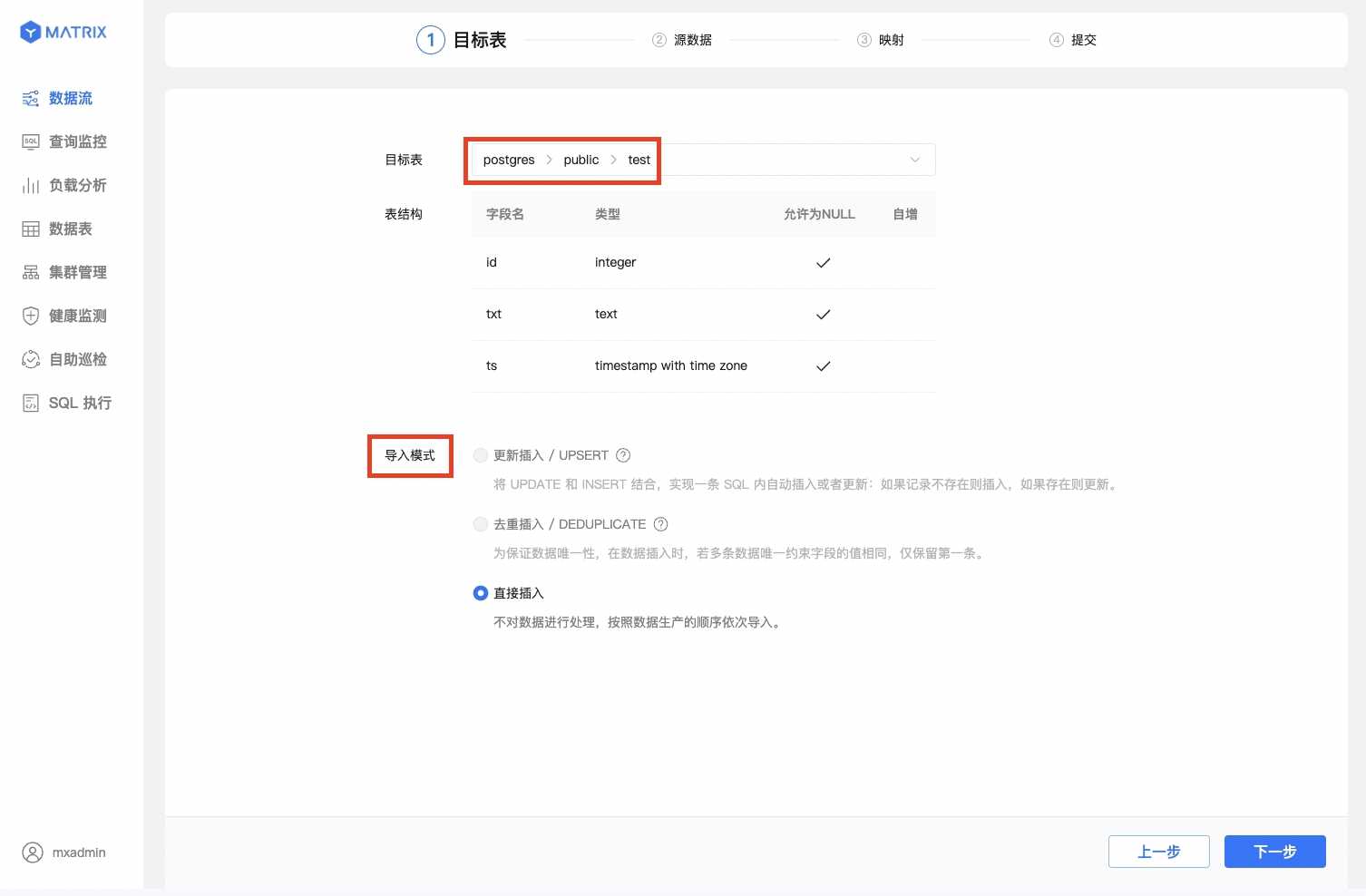
首先,你可以选择已有表或新建表来作为接收 Kafka 数据的目标表。
在目标表栏选择已有表与数据导入模式。这里假设选择的表为 postgres 数据库 public 模式下的 test。
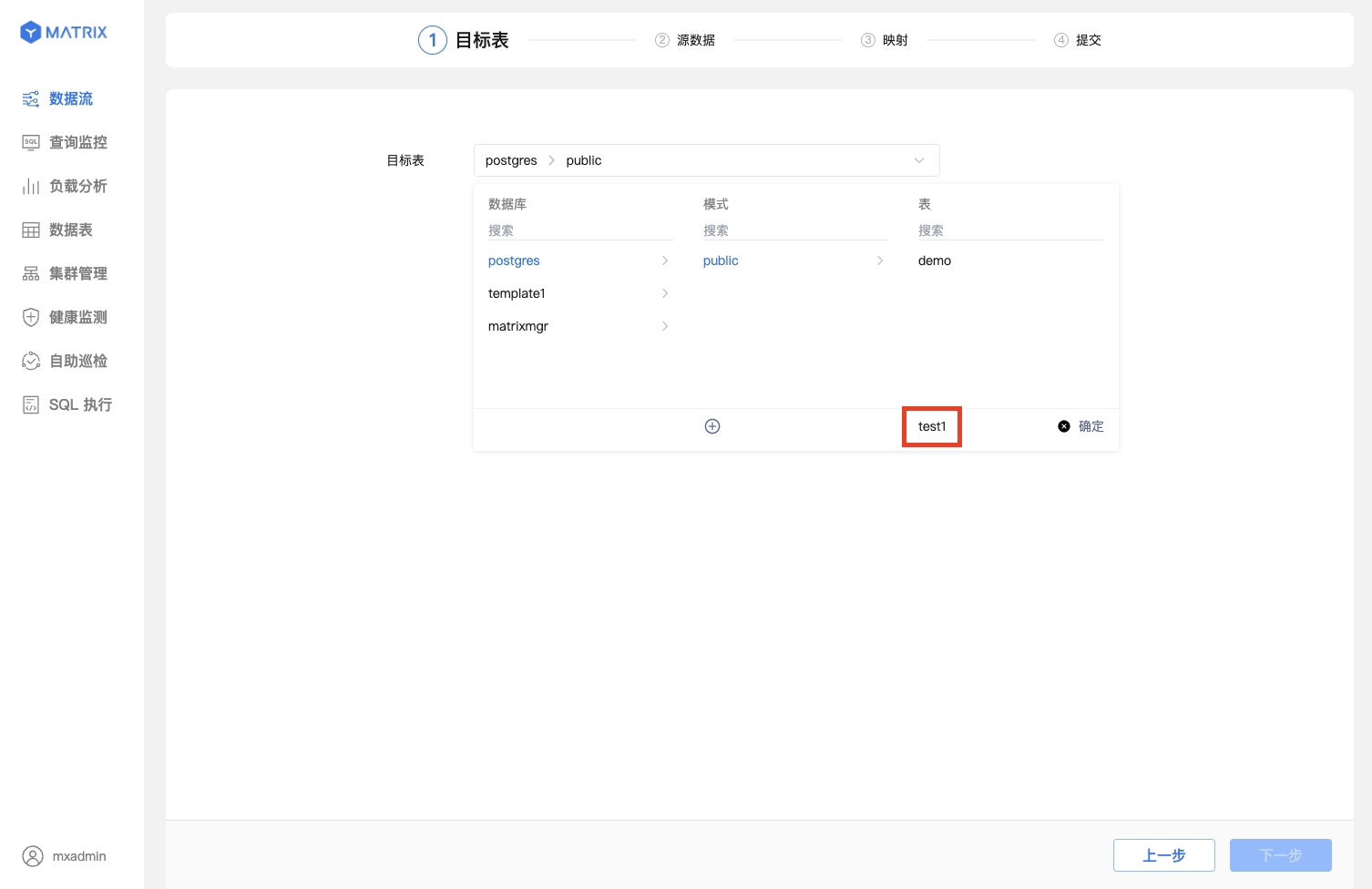
新建表,这里假设模式为 public,表名为 test1。
建表成功,出现红色的新建标识。
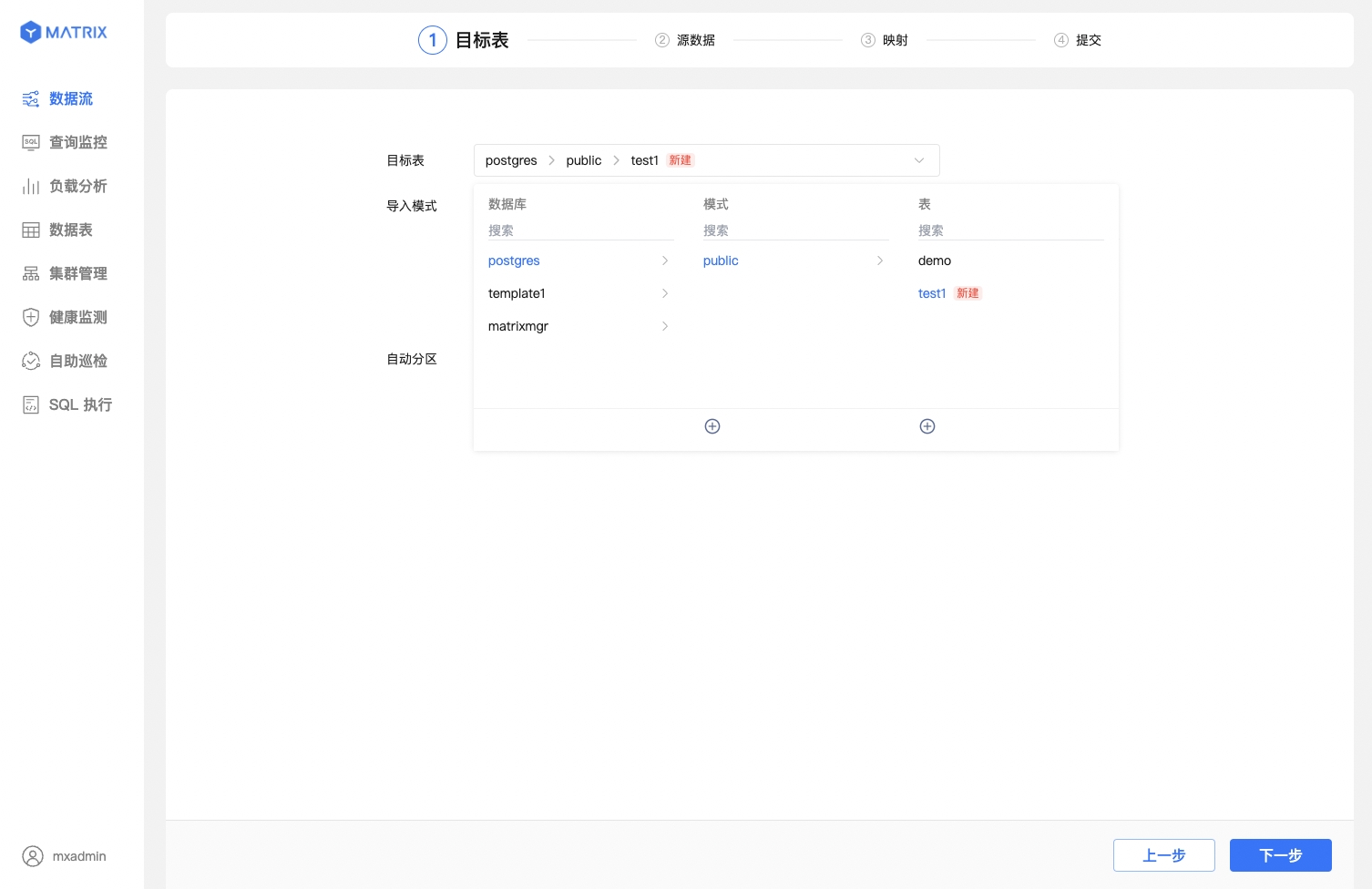
为其选择数据导入模式及自动分区策略。此处分区策略默认采用 auto_partitioning。

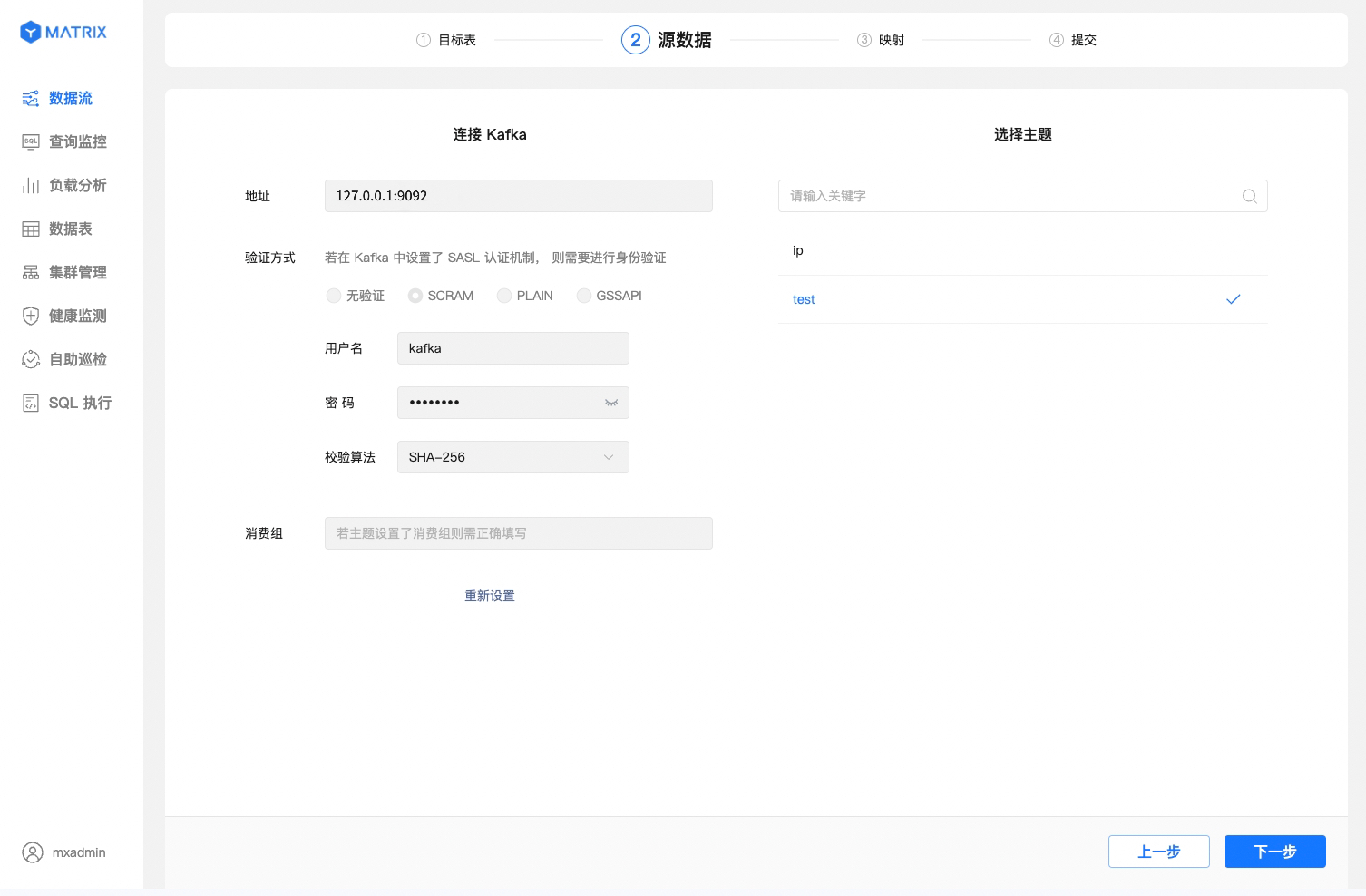
目标表选择完成后,第二步设置源数据的连接。你需要完成以下操作,才可以正确地进入下一步:
第三步配置样例数据,并映射已有表或新建表以导入 Kafka 数据。
选择 CSV 源数据格式,并指定或配置样例数据。你需要指定或手动配置样例数据格式,以保证映射的准确。
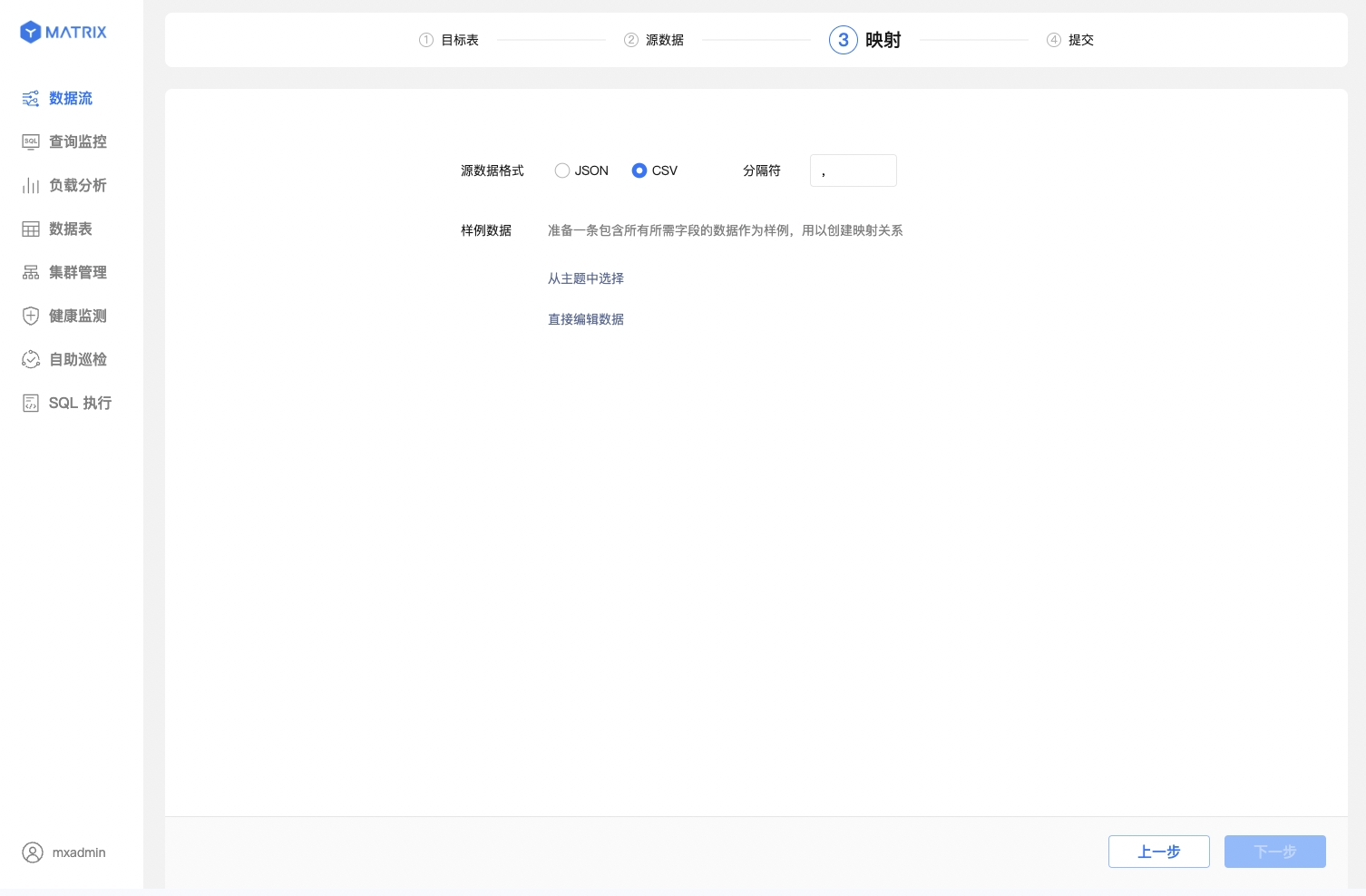
在配置样例数据时,你可以从主题中选择也可以直接编辑数据。
直接编辑数据,按照目标表的字段结构给予我们一条样例数据。该样例数据只用于字段结构的解析与映射,不会被导入到目标表中。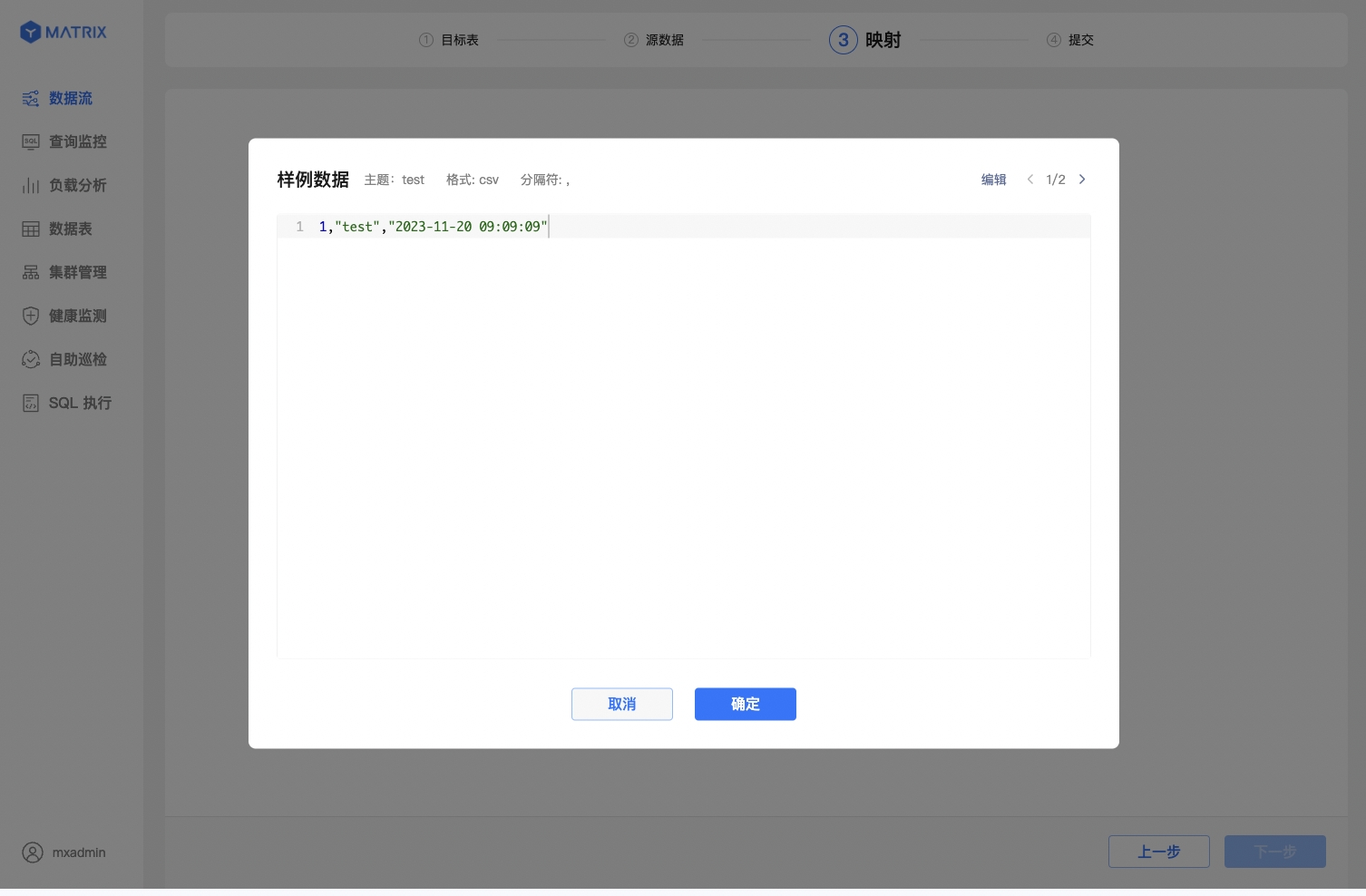
注意!
使用图形化界面新创建的表,默认使用 MARS3 存储引擎。更多相关信息请见 MARS3
简单地映射配置完成后,进行源数据字段与目标表字段的映射。此步骤已有表与新建表的操作有差异。
映射已有表
首先选择一条样例数据,再在映射关系中找到对应的目标字段,设置好之后点击保存,即可建立一条映射关系。
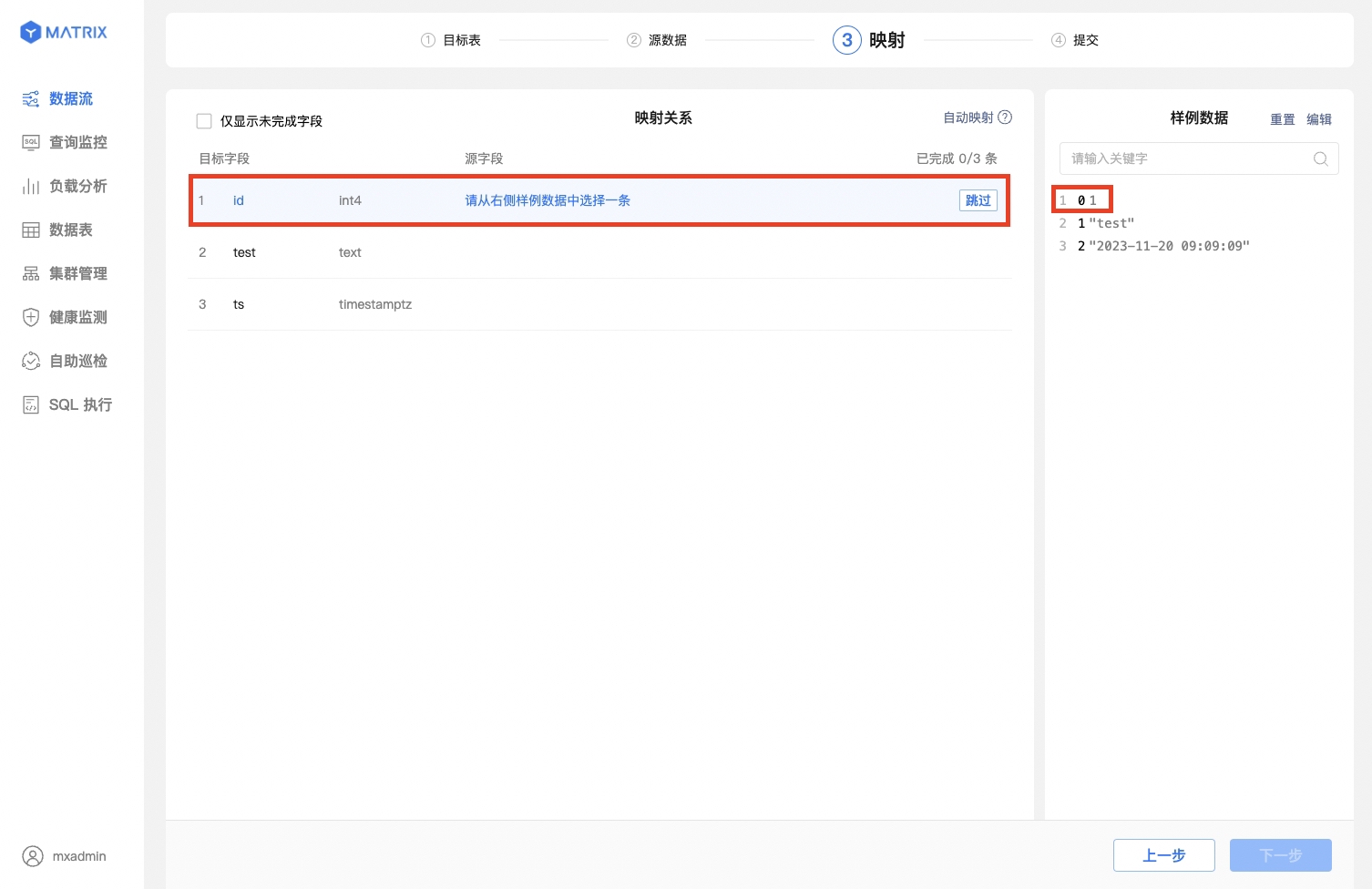
也可以直接一键自动映射,便捷的同时也保持映射的正确性。

映射新建表
新建表除建立映射规则外,还需注意以下设置:
当源字段值为 UNIX 时间戳且目标字段类型选择为 timestamptz 时,输出值右侧会显示复选框存储为 timestamp,勾选此框,输出值结果会自动转换为数据库的 timestamp 格式。
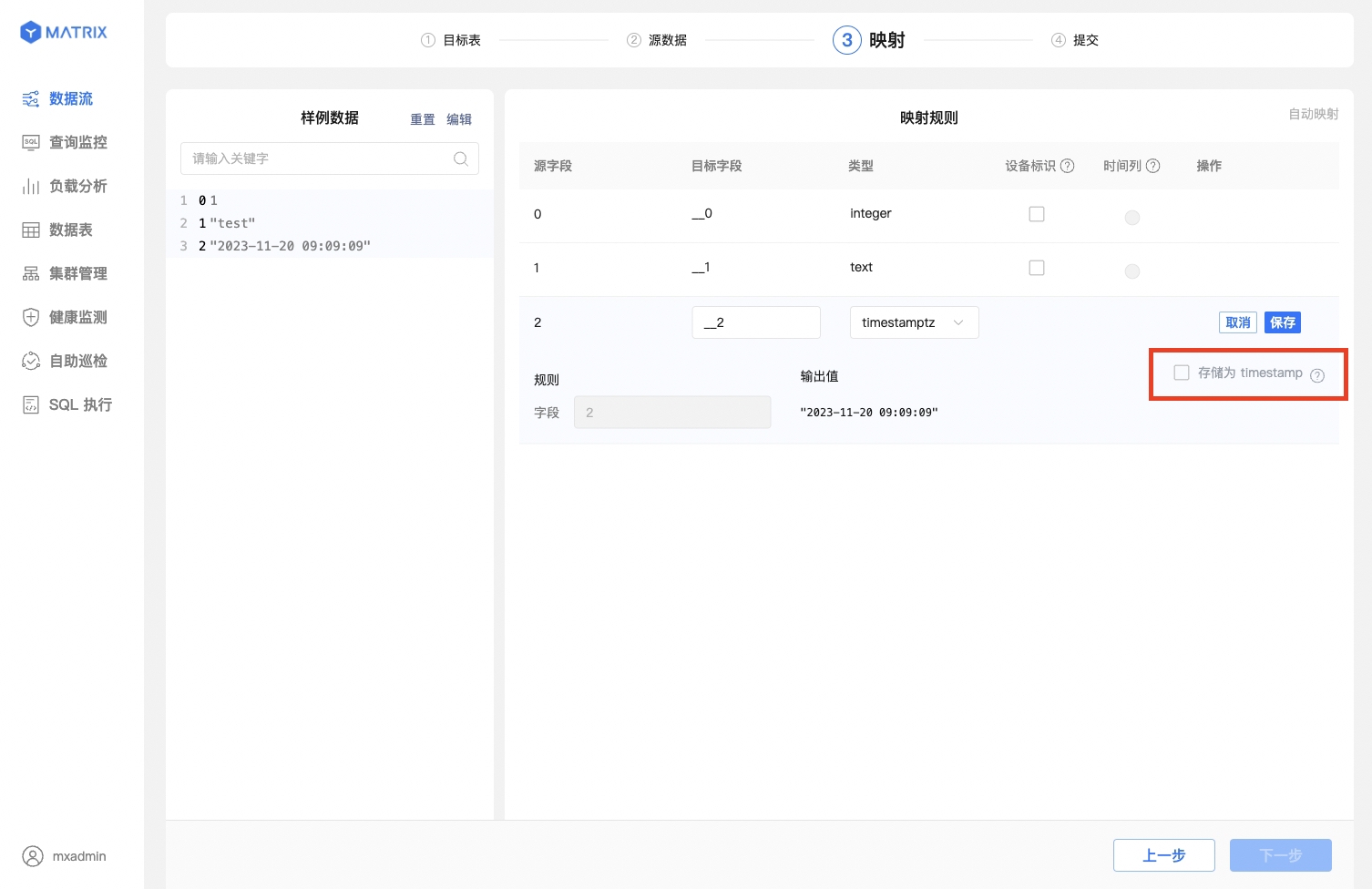
映射规则保存完之后,还需要选择“设备标识”以及“时间列”。“设备标识”选择目标表具有唯一约束的字段或者字段组合,“时间列”选择目标表类型为 timestamptz 的字段。

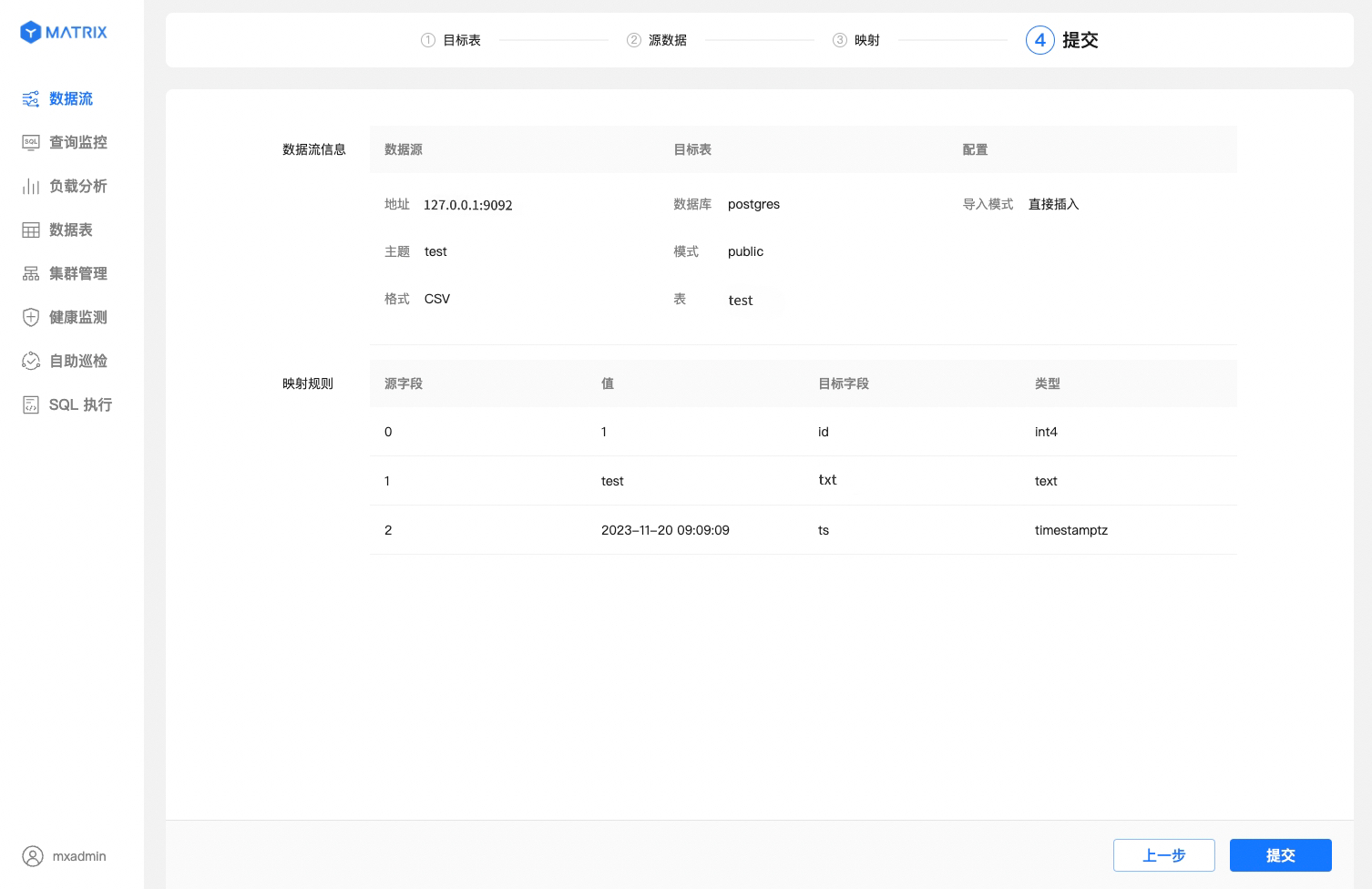
最后,确认数据流所有的配置信息,有误返回修改,无误则提交。
页面展示了数据流所有的配置信息,确认信息后点击“提交”按钮。
比已有表更多地显示了由“设备标识 + 时间列”组合而成的唯一标识信息。确认信息后点击“提交”按钮。
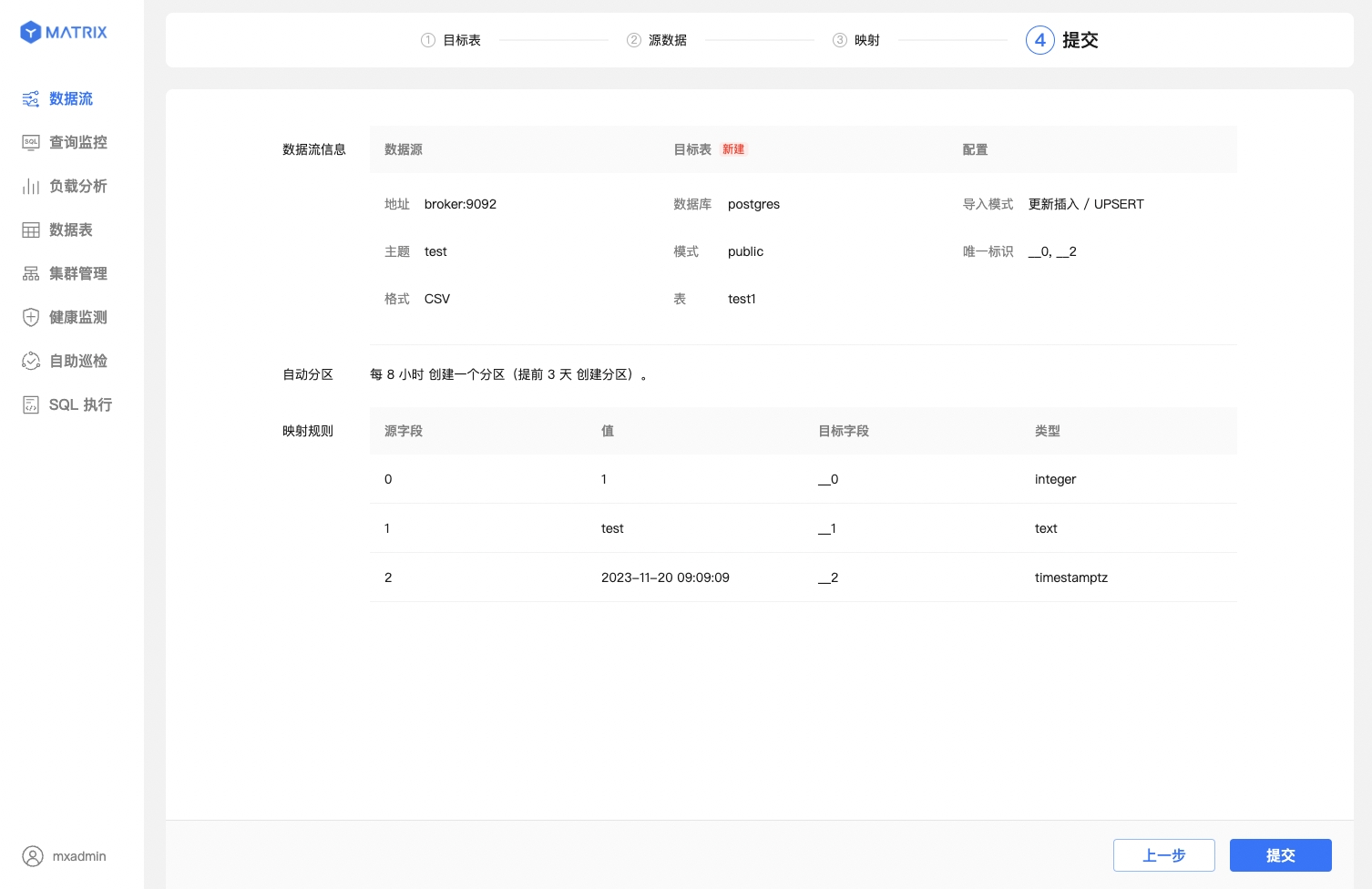
不论是已有表还是新建表,提交成功后都会进入到创建成功提示页面,到此 Kafka 数据流已成功创建。
这里主要描述与 CSV 格式接入的差异,集中在映射步骤。
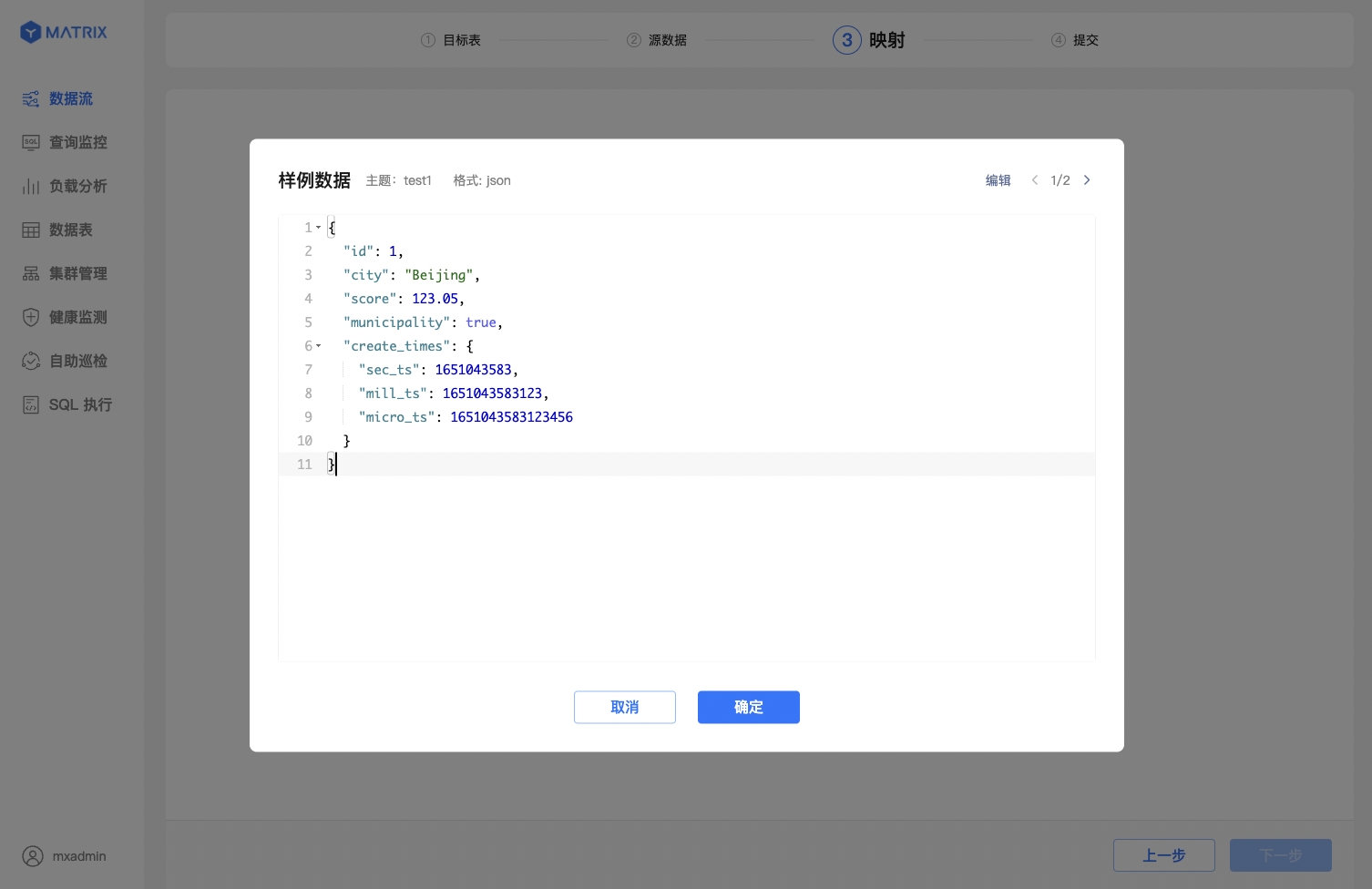
首先,选择 JSON 数据格式并配置样例数据。
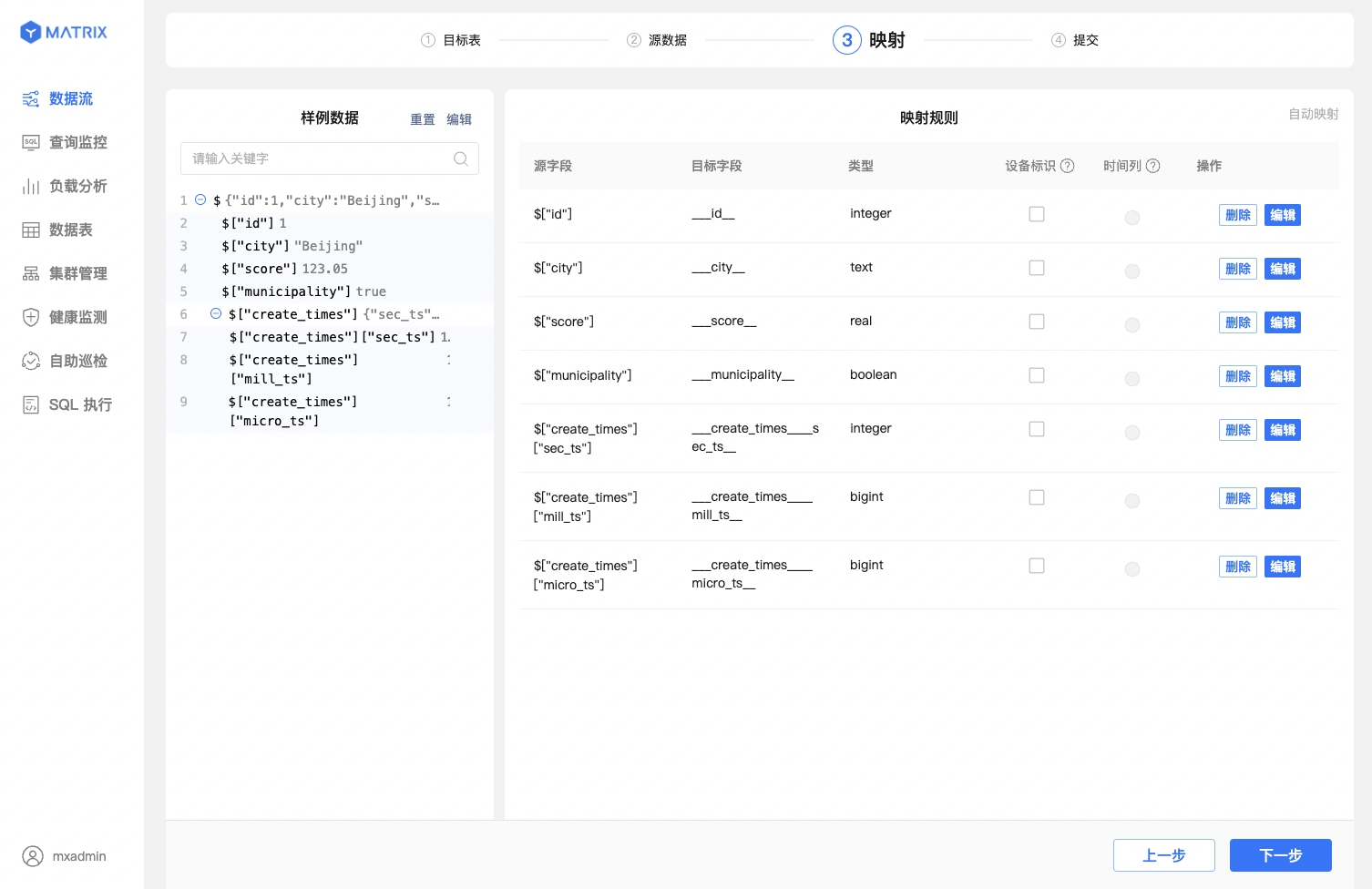
其次,JSON 列的索引使用 $["列名"] 的语义来索引,索引规则参照 JSONPath。
最后,JSON 数据支持多层级嵌套,YMatrix 支持选择不同层级的源数据字段创建映射规则。点击样例数据栏中 ⊕ 展开嵌套层级。
当你使用 YMatrix 图形化界面创建 Kafka 数据流后,数据会持续导入 YMatrix。此时,如因服务调试等原因,你想要临时暂停 Kafka 数据的导入,也可以直接在图形化界面进行操作。
对于运行中的 Kafka 数据流,可以从进程视图和任务视图操作入口暂停数据导入。
注意!
暂停操作可能需要 1-10 秒生效,期间不能对该数据流进行其他操作;暂停操作完成后,Kafka 数据将停止导入,同时状态切换至“已暂停”。
对于处于“已暂停”状态的 Kafka 数据流,可以恢复数据导入。在确认恢复操作后,数据流会立即恢复导入;页面将在最多 5 秒后恢复显示最新的导入信息。
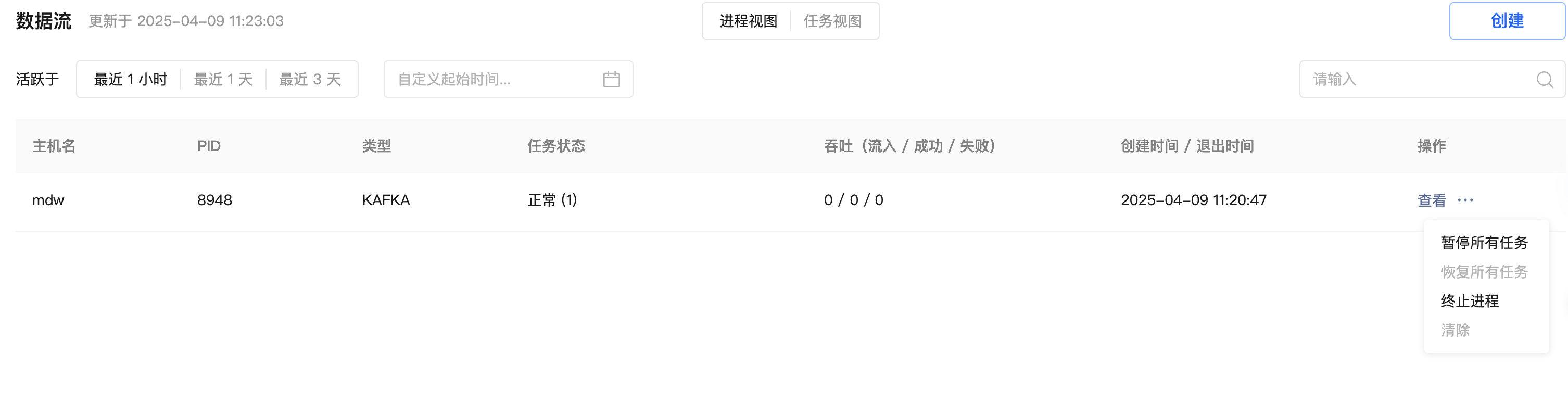
操作菜单下的扩展按钮可以进行暂停所有任务、恢复所有任务、终止进程和清除操作。
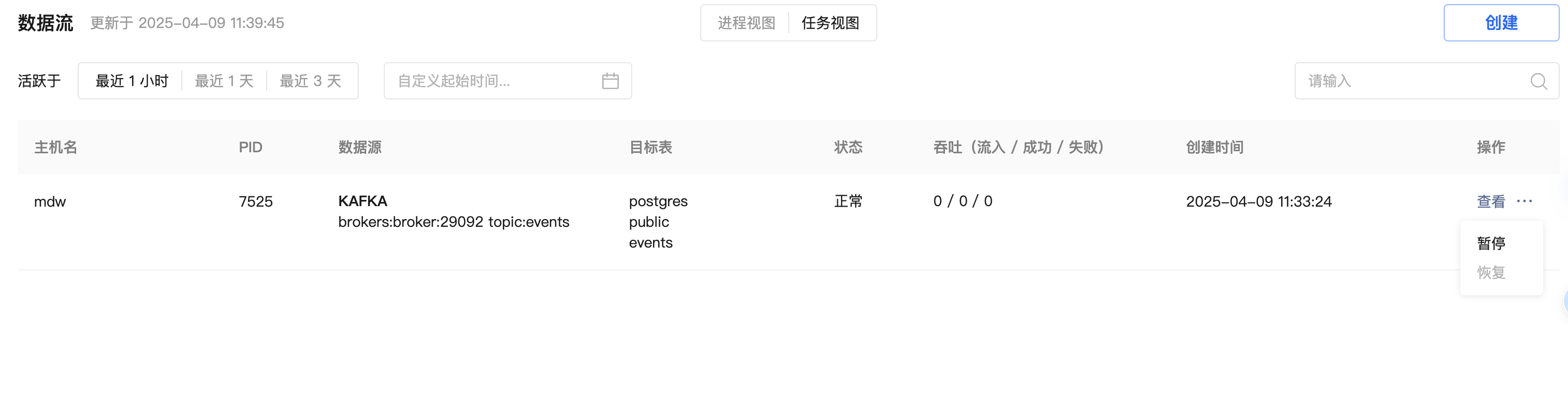
操作菜单下的扩展按钮可以进行暂停和恢复操作。



