Перед описанием компактизации (Compact) рассмотрим три важных понятия:
Увеличение чтения (Read amplification) — фактический объем считываемых данных превышает логически необходимый. Например, при чтении в LSM-Tree требуется сканировать несколько SSTable.
Увеличение записи (Write amplification) — фактический объем записываемых данных превышает логический. Например, при записи в LSM-Tree может запускаться операция Compact, что приводит к многократной перезаписи данных.
Увеличение пространства (Space amplification) — фактический занимаемый дисковой пространство превышает реальный объем полезных данных. Например, устаревшие версии данных в SSTable являются недействительными.
LSM-Tree достигает высокой производительности записи за счет последовательной записи и фонового слияния, а стратегия компактизации определяет баланс между производительностью чтения, записи и потреблением ресурсов.
Для традиционных LSM-Tree существуют две основные стратегии компактизации: Size-Tiered Compaction и Level Compaction.
Tiering — сначала накопление, затем массовое слияние (приоритет записи). Похоже на временное складывание файлов в ящик, а затем единовременное упорядочивание при заполнении.
Leveling — каждое уровень поддерживается в упорядоченном состоянии (приоритет чтения). Похоже на немедленное размещение каждого файла по заранее определенным полкам.
Tiered оптимизирован для записи, Leveling — для чтения.
Size-Tiered Compaction vs Level Compaction
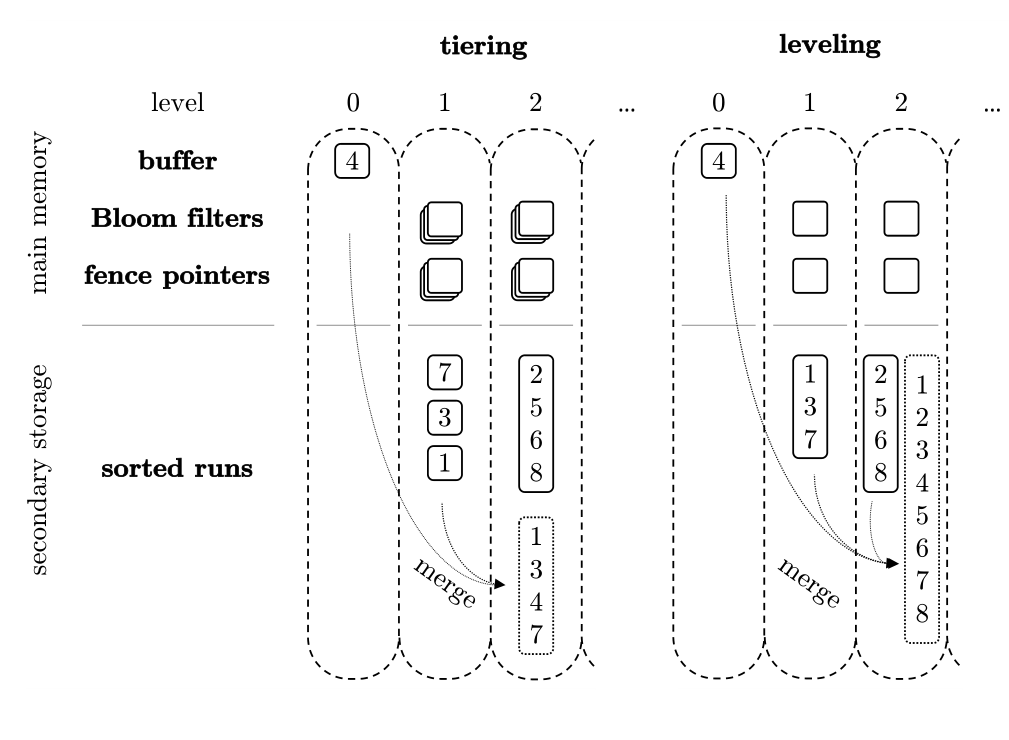
На одном уровне допускается перекрытие диапазонов ключей между SST. Объединяются SST близкого размера в более крупные файлы, без строгого требования неперекрытия.
Преимущества: низкое увеличение записи (слияние выполняется естественно, без частой перезаписи для устранения перекрытий).
Недостатки: высокое увеличение чтения (запрос может потребовать проверки множества Run).
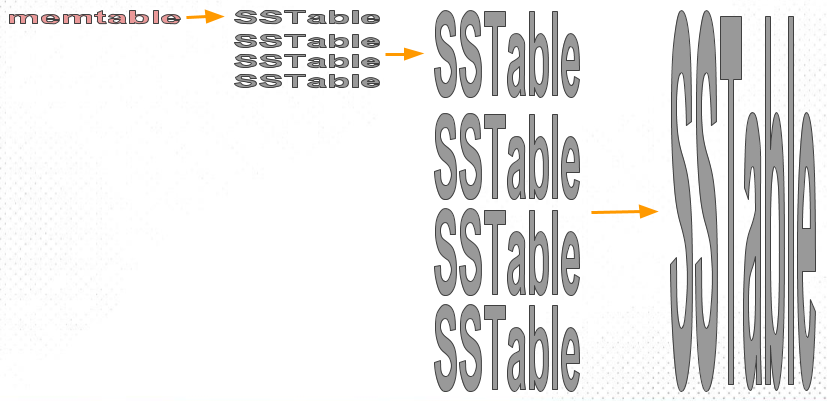
Идея Size-Tiered Compaction Strategy (STCS) — слияние SST близкого размера в новый файл. Memtable постепенно сбрасывается на диск в виде SST; сначала образуются мелкие файлы, затем при накоплении до порога сливаются в средние, затем в крупные и так далее.
Основные принципы:
На одном уровне допускается существование нескольких SST‑файлов с пересекающимися диапазонами ключей.
Файлы сначала накапливаются, и объединяются в единый блок только при достижении порога по количеству.
Предположим, что каждый SST может хранить 4 ключа:
Первая запись на диск: SST-A: [1–4]
Вторая запись на диск: SST-B: [5–8]
Третья запись на диск: в этот раз присутствуют обновления и новые данные; записываются ключи 3, 6, 9, 10, создается SST-C: [3–10]
Текущая структура уровня 0: [1–4] [5–8] [3–10]
Пересечение C и A в диапазоне 3–4
Пересечение C и B в диапазоне 5–8
При поиске ключа key=6 необходимо одновременно проверять несколько файлов — это и есть увеличение чтения (read amplification).
Механизм слияния в Tiered заключается в том, что при достижении порога по количеству файлов на одном уровне запускается объединение, в результате которого формируется один большой файл; в итоге получается единый диапазон [1–10].
Таким образом, преимущество данной схемы — высокая скорость записи и низкое увеличение записи (write amplification), а недостаток — необходимость сканирования нескольких файлов при запросе, то есть высокое увеличение чтения.
SST на каждом уровне не перекрываются по диапазонам ключей; при появлении перекрытия выполняется слияние и перезапись SST верхнего уровня и всех перекрывающихся SST нижнего уровня.
Преимущества: низкое увеличение чтения (запрос обычно обращается к небольшому числу файлов).
Недостатки: высокое увеличение записи (частая перезапись больших объемов данных).
При схеме leveled каждый уровень состоит из нескольких SSTable, образующих один упорядоченный run. Сами SSTable также поддерживают взаимную упорядоченность. При достижении лимита объема данных на уровне выполняется слияние с run следующего уровня. Такой подход сводит несколько run на уровне к одному, уменьшая усиление чтения и усиление пространства. Использование малых SSTable позволяет детально разделять и контролировать задачи, а управление размером задач эквивалентно контролю объема временного пространства.
Основные принципы:
Диапазоны ключей SST‑файлов на каждом уровне не должны пересекаться.
Вся система формирует непрерывное упорядоченное пространство.
В той же ситуации при обнаружении пересечения сразу выполняется слияние: [1–4] + [5–8] + [3–10] → [1–10], после чего производится повторное разделение на [1–5] и [6–10], чтобы гарантировать непересечение диапазонов на одном уровне.
Таким образом, преимущество схемы — высокая скорость запросов, так как запросу достаточно обратиться максимум к одному файлу. Недостаток — большое усиление записи, постоянное выполнение фоновой компактизации и высокая нагрузка на ввод-вывод.
| Параметр | Tiered | Leveling |
|---|---|---|
| Перекрытие на одном уровне | Разрешено | Не разрешено |
| Стоимость записи | Очень низкая | Средне-высокая |
| Стоимость запросов | Высокая | Очень низкая |
| Усиление записи (Write amplification) | Малое | Большое |
| Нагрузка на ввод-вывод (IO) | Легкая | Тяжелая |
| Стабильность задержек | Плохая | Хорошая |
| Приоритетная цель | Пропускная способность (Throughput) | Отзывчивость (Response) |
MARS3 использует стратегию Tiered Compaction. Кратко говоря, при типичной временной нагрузке с ключами вида VIN+TS непрерывная запись данных приводит к широкому перекрытию ключевого пространства нового run с несколькими run нижних уровней. Это делает Leveled Compaction неэффективной: она не может поддерживать непересечение внутри уровня, что часто вызывает массовую перезапись больших объемов данных, значительно увеличивая write amplification (усиление записи), которое в сценариях MPP с множеством экземпляров еще больше усугубляется.
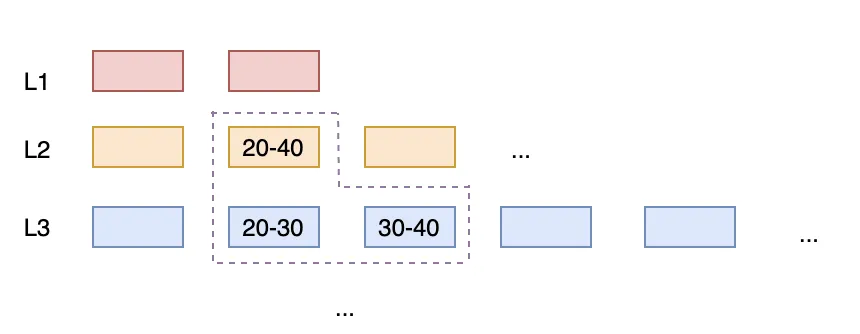
Предположим, что в системе есть 3 устройства (VIN=A,B,C), каждое из которых непрерывно отправляет последние значения.
В системе уже существует уровень L1, где каждый файл покрывает один временной интервал одного VIN:
В L1 уже есть:
Теперь поступают новые данные:
Эти новые записи обычно сначала формируют новый run (например, в L0 или верхнем уровне), назовем его NewRun. NewRun одновременно содержит последние временные срезы A/B/C и покрывает следующие диапазоны ключей:
С какими файлами L1 он перекрывается?
То есть один NewRun одновременно перекрывает несколько файлов L1 (по одному для каждого VIN).
Если устройств больше, например 10 000 VIN одновременно записывают, то один NewRun может перекрывать сотни или тысячи файлов L1 (в зависимости от способа разбиения L1).
При этом Leveled Compaction требует, чтобы файлы в L1 были максимально непересекающимися. Поэтому при слиянии NewRun в L1 Leveled должна выполнить следующее: прочитать NewRun + все перекрывающиеся с ним файлы L1, заново объединить и отсортировать, затем записать обратно в новые файлы L1, чтобы сохранить непересечение. Стоимость этого шага такова: даже если новая запись очень мала (например, 1 ГБ), если она затрагивает исторические сегменты многих VIN, она потянет за собой перезапись большого количества исторических файлов (например, 10 ГБ, 50 ГБ, 100 ГБ), что приводит к сильному write amplification.
Size-Tiered Compaction не требует непересечения нижних уровней: она в основном объединяет run одинакового размера в более крупные, не перезаписывая множество нижних файлов каждый раз для устранения перекрытий. Поэтому в данном сценарии влияние write amplification относительно меньше.
Кроме того, RUN в MARS3 имеет колоночную структуру, которая требует достаточной физической непрерывности для обеспечения пропускной способности сканирования и эффективности сжатия — это конфликтует с мелкозернистыми SST, обычно используемыми в Leveled Compaction. Size-Tiered Compaction лучше подходит под эту нагрузку: она основана на объединении run одинакового размера, значительно снижает write amplification и естественным образом формирует организацию run, сгруппированных по времени в потоке данных с прогрессирующим временем, что делает фильтрацию и пропуск данных по временным условиям более эффективными.
Для контроля read amplification (усиления чтения) мы ограничиваем коэффициент усиления чтения для каждого уровня: когда он превышает заданное значение, запускается компактизация на нижний уровень.

Параметр level_size_amplifier задает коэффициент увеличения размера уровня:
Коэффициент увеличения размера уровня. Порог для запуска операции слияния на уровне вычисляется как: rowstore_size * (level_size_amplifier ^ (level - 1)) Чем больше его значение, тем медленнее скорость чтения и выше скорость записи. Значение можно выбрать в зависимости от конкретного сценария (много записи/мало чтения, много чтения/мало записи, коэффициент сжатия и т.д.). Примечание: необходимо следить, чтобы количество run на каждом уровне не было слишком большим, иначе это повлияет на производительность запросов и даже может блокировать вставку новых данных.
По сути level_size_amplifier контролирует, во сколько раз каждый уровень может быть больше предыдущего — как будто верхние уровни являются буфером, а нижние — долговременным хранилищем.
Поэтому легко понять:
Больший amplifier → каждый уровень может накапливать данные дольше, количество run увеличивается, что заставляет запросы проверять больше объектов (read amplification), но компактизация запускается реже (запись быстрее).
Меньший amplifier → компактизация и упорядочивание запускаются раньше, run становится меньше и более упорядоченными, чтение быстрее, но компактизация происходит чаще.
Параметры rowstore_size и level_size_amplifier вместе формируют контролируемый ритм «погружения» данных, который в модели Tiered ограничивает накопление run, тем самым сдерживая read amplification и сохраняя преимущества пропускной способности записи. Более подробные детали см. в разделе 7.2 «Наблюдаемость».
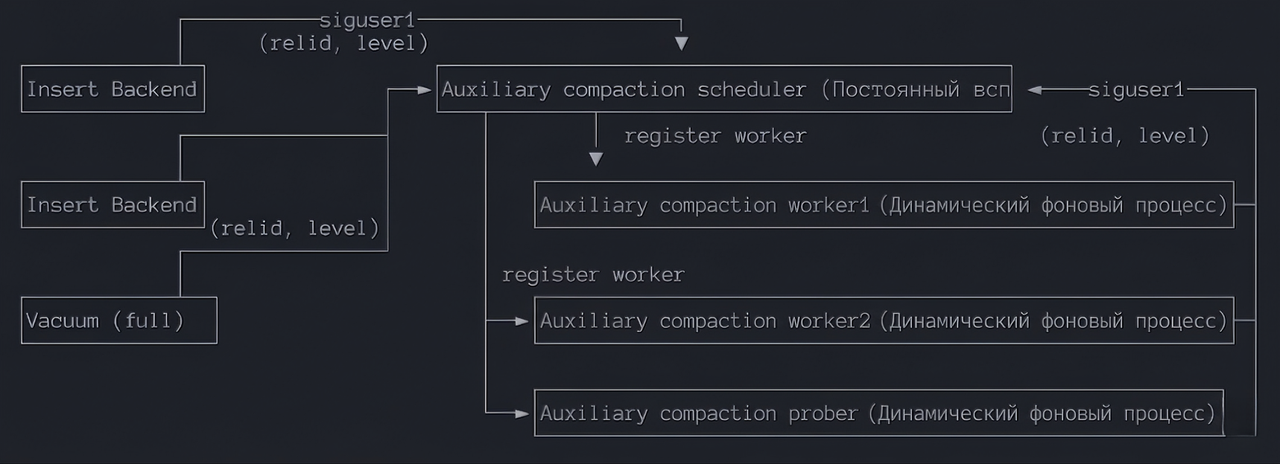
Compaction scheduler — это вспомогательный постоянный процесс, который запускается при старте базы данных. Когда размер rowstore достигает значения rowstore_size, происходит переключение на новый rowstore, после чего процессом отправляется сигнал планировщику и через разделяемую память передается запрос на компактизацию, включая идентификатор отношения и соответствующий уровень. Планировщик отвечает за регистрацию новых рабочих процессов для выполнения компактизации.
Compaction scheduler в основном отвечает за:
Запуск и остановку рабочих процессов компактизации
Управление и повторное использование рабочих процессов компактизации
Определение приоритета задач компактизации
Корректную обработку запроса на остановку базы данных
Compaction worker выполняет конкретные запросы на компактизацию, одновременно обнаруживая превышение коэффициента увеличения чтения на уровне и уведомляя планировщик о новом запросе. На данный момент, в связи с ограничениями модели процессов, максимальное количество рабочих процессов компактизации зафиксировано в коде — 16 штук.
Compaction prober отвечает за активное обнаружение задач компактизации, например:
Периодические задачи компактизации
Прерванные задачи компактизации
Общий процесс:
Insert Backend непрерывно записывает данные в RowStore
Когда определенный Rowstore достигает порогового значения, происходит переключение на новый Rowstore
Отправляется сигнал SIGUSR1 планировщику, одновременно в разделяемую память записывается информация запроса на компактизацию: (relid, level)
Планировщик пробуждается, считывает запрос из разделяемой памяти
Выполняется постановка в очередь, дедубликация, установка приоритета
Выбирается запуск нового рабочего процесса или повторно используется свободный
Рабочий процесс начинает выполнение компактизации
Если для компактизации требуется обработка нескольких таблиц, но доступно только 16 рабочих процессов, необходим определенный приоритет, чтобы обеспечить своевременное выполнение компактизации для наиболее нуждающихся таблиц.
Кратко говоря, при определении приоритета компактизации учитываются: уровень (нижние уровни имеют более высокий приоритет), режим Eager или Lazy (ручной или автоматический), тип компактизации и другие параметры.
Принцип Autoprobe заключается в периодическом обнаружении возраста транзакций и размера всех таблиц MARS3, вычислении оценки как возраст, деленный на размер. Autoprobe позволяет выполнять сжатие исторических уровней. Выбирается N уровней с наибольшей оценкой для запуска задач сброса или компактизации. Через функцию
adw=# select * from matrixts_internal.mars3_autoprobe_candidates();
segid | datname | relname | level | nruns | age | bytes | score
-------+---------+-------------+-------+-------+------------+-----------+-----------------------
0 | adw | t_w0_nosort | 1 | 13 | 616005 | 49888440 | 0.012347650076851471
0 | adw | t_w0_nosort | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w3b_3key | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w1_1key | 1 | 7 | 329693 | 23821378 | 0.013840215288972788
...Чтобы предотвратить невозможность обработки других уровней с более низкой оценкой из-за неудачи компактизации, введен механизм черного списка Autoprobe: один и тот же уровень после трех неудачных попыток попадает в черный список и больше не повторяется.
Через функцию mars3_autoprobe_blacklist() можно просмотреть черный список
Через функцию mars3_autoprobe_blacklist_remove(regclass, level) можно удалить запись из черного списка для указанного уровня текущей базы данных
Через функцию mars3_autoprobe_blacklist_clear() можно очистить весь черный список
Описание параметров GUC:
guc mars3.autoprobe_period управляет интервалом обнаружения, в секундах; значение больше 0 включает функцию, 0 отключает; по умолчанию отключено
guc mars3.autoprobe_workers управляет количеством уровней, выбираемых за одно обнаружение; по умолчанию 2
guc mars3.autoprobe_retry управляет количеством повторных попыток
guc mars3.autoprobe_blacklist_size управляет размером черного списка
Последствие отключения autoprobe заключается в том, что таблицы, в которые не выполняется запись, не будут подвергаться компактизации; таблицы, в которые выполняется запись, по-прежнему будут постоянно объединяться.
Команда ps aux | grep postgres | grep 'compact worker' служит для проверки работоспособности всех рабочих процессов. Необходимо убедиться в отсутствии запущенных долго работающих и не завершающихся процессов, что является признаком ненормальной работы системы.
Кроме того, в журнале базы данных также содержится информация о деятельности компактизации.
postgres=# create table t1(id int,info text)
using mars3 with(mars3options='prefer_load_mode=single,rowstore_size=64');
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE Откройте новое окно и постоянно отслеживайте состояние каждого уровня с помощью функции matrixts_internal.mars3_level_stats.
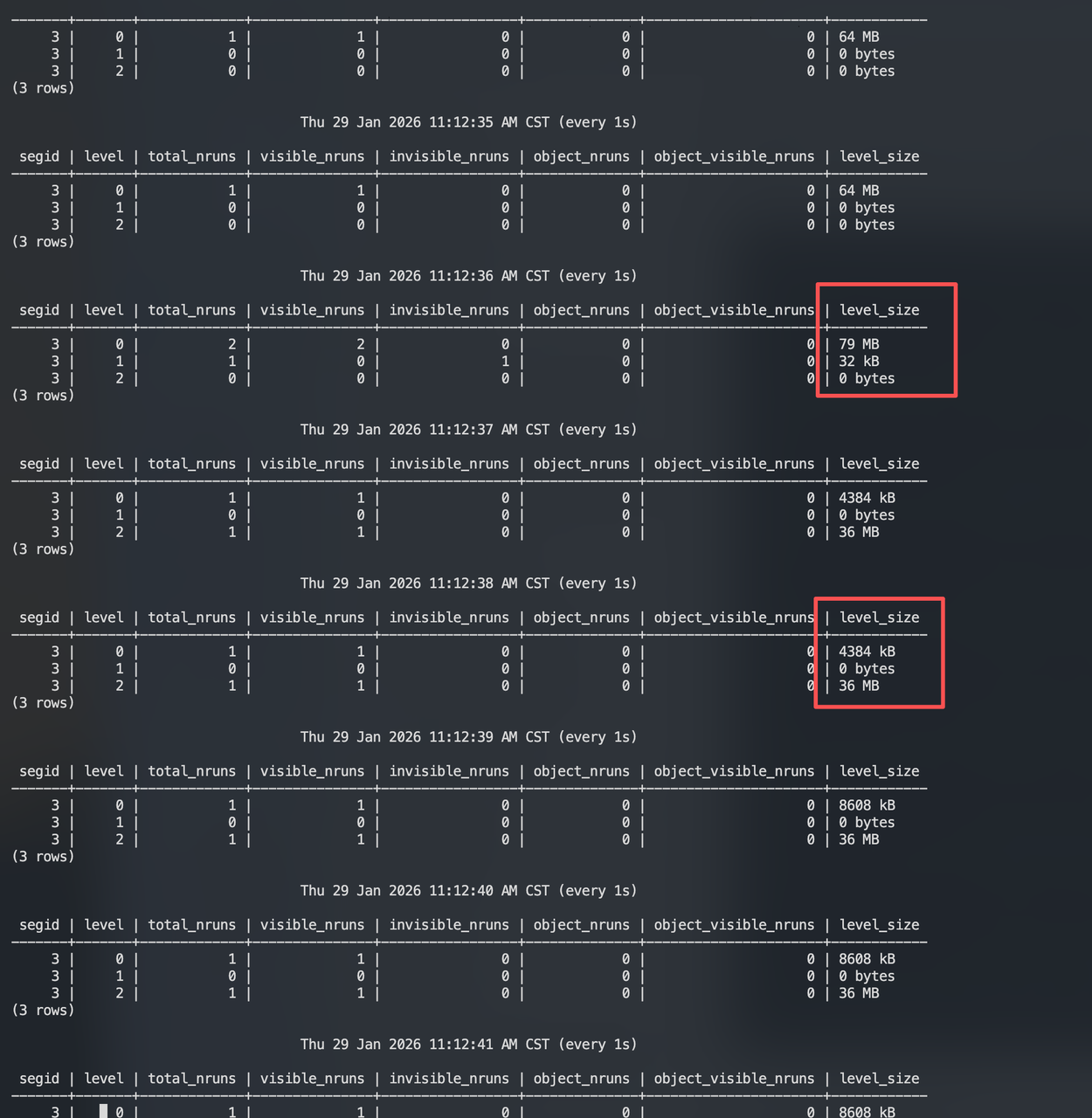
Как видно, после заполнения L0 до 64 МБ (rowstore_size), на L1 появился размер 32 КБ на короткое время, после чего запись сразу пошла в L2. Последующие данные также записываются напрямую в L2. Почему так происходит, почему запись не идет напрямую в L1?
В MARS3 реализована логика adjust level — GetDesiredLevel.
По размеру Run (TotalSize) определяется, к какому уровню он должен относиться (desired_level).
Если текущий уровень (cur_level) не совпадает с желаемым, накладывается блокировка, и Run перемещается с текущего уровня на целевой.
Согласно приведенному коду:
run_size ≈ rowstore_size = 64 МБ
total_amp = run_size / rowstoresize = 64 МБ / 64 МБ = 1.0
desired_level = log(1.0) / log(8) = 0 / log(8) = 0
Таким образом, теоретический относительный номер уровня для этого run равен 0, его размер точно соответствует уровню rowstore_size.
if (desired_level Ошибка: there are too many segments, 6400 at most. please use VACUUM FULL.
Симптом у клиента: ошибка при записи в таблицу (одинаковая структура, одинаковые данные) из режима BULK в режим Single. Причина — слишком высокая скорость записи в режиме Single, компактор не успевает обработать данные, создается избыточное количество Run. Проблема решена увеличением rowstore_size, но это требует баланса, так как большое значение потребляет больше памяти.
### 7.3.4 Слишком большой размер таблицы
Симптом: большой размер таблицы при просмотре через мета-команду \dt+
Возможные причины:
- Избыточное количество Run в rowstore в строчном формате
- Большое количество невидимых Run
Способ решения:
Ручное выполнение vacuum + vacuum full для преобразования в колоночное хранилище; требуется несколько циклов, так как vacuum full включает операцию MERGE и также генерирует невидимые run до завершения объединения
### 7.3.5 Как получить ключи сортировки таблицы
```sql
adw=# create table testmars3(id int,info text) using mars3 distributed by (id) order by(id) ;
CREATE TABLE
adw=# \d+ testmars3
Table "public.testmars3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
info | text | | | | extended | |
Distributed by: (id)
Access method: mars3
Order by: (id)
adw=# select * from matrixts_internal.mars3_sortkeys('testmars3');
sks
------
(id)
(1 row) Начиная с версии 6.5.0 MARS3 официально поддерживает инкрементное резервное копирование с уровнем таблицы, идентичным таблицам AO: система резервного копирования определяет, были ли изменены данные или структура таблицы с последнего бэкапа, и копирует только измененные данные, значительно сокращая объем и время резервного копирования.
YMatrix добавил точный учет изменений данных, аналогичный свойству modcount таблиц AO. Параметр mars3.update_modcount позволяет гибко включать/выключать эту функцию: система автоматически увеличивает счетчик изменений при каждой записи, обновлении или удалении данных в таблице. Кроме того, MARS3 поддерживает получение времени последнего изменения атрибутов таблицы из представления pg_stat_last_operation для выявления структурных изменений.
Последние версии MARS3 поддерживают учет изменений данных, аналогичный свойству modcount таблиц AO, управление осуществляется через параметр mars3.update_modcount. Также поддерживается получение времени последнего изменения атрибутов таблицы из таблицы pg_stat_last_operation. На основе этих двух функций реализована инкрементная analyzedb для таблиц MARS3, идентичная таблицам AO.
MARS3 ориентирован на наиболее распространенные и сложные для балансировки корпоративные сценарии: постоянная запись данных, постоянные запросы, поддержка реального времени и аналитики, детальный просмотр и масштабная агрегация.
В таких сценариях основная проблема клиентов — не недостаток производительности отдельных компонентов, а фрагментация системы: для одновременного удовлетворения требований реального времени и аналитики приходится поддерживать несколько цепочек хранения и обработки, увеличивая сложность архитектуры, стоимость эксплуатации и нестабильность производительности. Основная ценность MARS3 — объединение этих взаимосвязанных функций в единую систему хранения, обеспечивающую стабильную, проверяемую и устойчивую работу.
На стороне записи MARS3 обрабатывает высокочастотные, малопакетные данные реального времени и преобразует их в колоночный формат для аналитики в фоновом режиме. Клиентам не нужно выбирать между реальным временем и аналитикой: новые данные быстро поступают в систему, а накопленные данные обеспечивают эффективное сканирование и агрегацию. Стратегия фоновой обработки MARS3 оптимизирована для смешанных нагрузок, контролирует усиление записи и конкуренцию ресурсов, предотвращая деградацию системы при росте данных, пиковых нагрузках и параллельной работе нескольких экземпляров.
На стороне запросов ценность MARS3 не только в ускорении чтения, но и в минимизации чтения нерелевантных данных. За счет локальности данных на основе ключей сортировки, блочных метаданных и оптимизации путей доступа через индексы система сокращает область сканирования на ранних стадиях запроса. Для клиентов это означает поддержку большего количества аналитических задач на том же оборудовании, стабильные запросы при том же объеме данных и контролируемые затраты на ресурсы. Этот эффект достигается за счет системных механизмов: организации хранения, пропуска данных и оптимизации индексов, без ручной тонкой настройки.
Важнее всего: MARS3 — не экспериментальное решение, а промышленный движок с гарантированной корректностью и эксплуатационными границами. При обновлении и удалении данных он сохраняет семантику при переносе и объединении в фоновом режиме; при параллельных обновлениях реализует корректное поведение с ожиданием, цепочкой версий и повторной проверкой. Для управления и эксплуатации предусмотрена наблюдаемость статистики уровней/run, определение режимов деградации и параметрическое управление, обеспечивающее долгосрочную стабильную работу. Клиенты получают не просто высокопроизводительный движок хранения, а готовое к внедрению, простое в эксплуатации решение для критически важных бизнес-задач.
Итоговая ценность MARS3 для смешанных нагрузок AP сводится к трем пунктам:
Унификация: одна система хранения для реального времени, аналитики и детального просмотра, снижение сложности интеграции нескольких систем
Стабильность: предсказуемая производительность при одновременной записи, запросах и фоновой обработке, а не только в идеальных сценариях
Готовность к внедрению: фокус на корректности, наблюдаемости и эксплуатационном цикле, обеспечение долгосрочной работы в промышленной среде
Основная ценность MARS3 — не улучшение отдельных функций, а поддержка устойчивого бизнеса в сложных смешанных сценариях за счет меньшей фрагментации, сниженных общих затрат и повышенной долгосрочной стабильности.
Поддержка индексов BRIN с multi-minmax
Поддержка индексов GIN в MARS3
Улучшение наблюдаемости: текущая информация о pick, compact записывается в логи и требует поиска на соответствующих QE, часть данных ориентирована на разработчиков ядра и неудобна для эксплуатации
mxnumeric и MARS3
Тип numeric в PostgreSQL (далее pg numeric) имеет более высокую точность, чем аналогичные типы в других базах данных, но сложнее в реализации и имеет низкую производительность. pg numeric плохо поддерживает векторизацию: в векторизованном исполнителе он не дает ускорения, а работает через механизм совместимости, медленнее не векторизованного исполнителя. По сравнению с ускоренными типами int/float производительность pg numeric ниже на 1–2 порядка. Для повышения производительности реализован тип numeric с ограниченной точностью (далее mxnumeric), поддерживающий до 38 знаков, предоставляемый расширением mxnumeric.
Поскольку MARS3 и mxnumeric являются независимыми расширениями, порядок их установки не гарантирован. По умолчанию тип mxnumeric не поддерживает индексы mars3_btree и mars3_brin.
Для использования индексов mars3_btree и mars3_brin вызовите mxnumeric.set_config('mars3', true) для ручного создания operator class. Требуется установленное расширение matrixts, иначе возникнет ошибка:
ERROR: data type numeric has no default operator class for access method "mars3_btree" HINT: You must specify an operator class or define a default operator class for the data type.
Для удаления operator class и возврата к состоянию по умолчанию используйте mxnumeric.set_config('mars3', false).
Run: упорядоченный набор данных по ключу сортировки в MARS3, базовая единица хранения и фоновой обработки (объединение/преобразование в колонки/очистка)
Level: иерархическая структура организации Run; нижние уровни оптимизированы под запись, верхние — под чтение и упорядочивание
Delta: инкрементная информация изменений для поддержки обновлений/удалений (новые версии/метки/различия), подлежащая сбору и очистке в фоновом режиме
MVCC: механизм управления многоверсионным параллелизмом, определяющий видимость данных для текущей транзакции и обеспечивающий согласованность параллельных операций чтения/записи
Сначала строка, потом колонки: стратегия жизненного цикла: данные поступают в систему в строчном формате (оптимизированном под запись) и преобразуются в колоночный формат (оптимизированный под сканирование) в фоновом режиме
RowStore (строчное хранилище): физическая организация данных по строкам, оптимальная для точечных запросов и малого чтения, но с высоким неэффективным вводом-выводом при аналитическом сканировании
ColumnStore (колоночное хранилище): физическая организация данных по столбцам, оптимальная для масштабного сканирования и агрегации, высокий коэффициент сжатия, чувствительность к высокочастотной малопакетной записи
Ключ сортировки (Sort Key / ORDER BY): определяет порядок данных внутри Run, ключевой параметр, влияющий на эффективность пропуска данных, сканирования и стоимость обработки
Локальность данных (Locality): физическое соседство данных с близкими ключами, сокращение области сканирования для запросов по диапазонам
Пропуск данных (Data Skipping): пропуск нерелевантных блоков с использованием блочных метаданных (min/max, BRIN), сокращение объема чтения
Блочные метаданные (Block Metadata): статистика для пропуска данных (min/max блока, количество строк, видимость)
BRIN: индекс/механизм метаданных на основе сводки диапазонов блоков, экономичное решение для обрезки диапазонов больших таблиц
default_brin: стандартная стратегия BRIN/метаданных пропуска данных в MARS3 для типичных нагрузок, сокращение области и стоимости сканирования
Избирательность (Selectivity): доля данных, сохраняемых после фильтрации; в сценариях BRIN соответствует доле попавших диапазонов/страниц
Усиление чтения (Read Amplification): отношение фактического объема чтения к логическому запросу (поиск по нескольким Run/версиям)
Усиление записи (Write Amplification): отношение физической записи к логической операции (поддержка метаданных, объединение, преобразование в колонки)
Компактизация (Compaction): фоновое упорядочивание/объединение нескольких Run для снижения усиления чтения, очистки невидимых версий, улучшения пропуска данных и сжатия
Долг компактизации (Compaction Debt): мера невыполненной фоновой работы, приводящая к удлинению пути чтения или скачкам записи
Сброс (Flush / Dump): запись инкрементных данных из памяти на диск с формированием постоянного Run
Преобразование в колонки (Row-to-Column / Columnization): преобразование строчного формата в колоночный для повышения пропускной способности сканирования и сжатия
Очистка (GC / Vacuum-like Reclaim): удаление невидимых версий/меток и освобождение пространства, совместно с компактизацией
Unique Mode: режим вставки-обновления по уникальному ключу (определенному ключом сортировки), создание новых версий при записи с одинаковым ключом; оптимизирован для моделей последнего состояния/сnapshot
shared_buffers: традиционный пул буферов PostgreSQL, участие в чтении зависит от реализации движка хранения
varbuffer (mx_varbuffer_size_mb): специализированный кэш MARS3 для индексных операций, снижение повторного чтения и хвостовой задержки
adw=# select name,setting from pg_settings where name like '%mars3%';
name | setting
----------------------------------------+-------------------
mars3.allow_alter_rewrite | off
mars3.append_sync | off
mars3.archive_dontvacuum | off
mars3.autoprobe_period | 0
mars3.autoprobe_retry | 2
mars3.autoprobe_workers | 2
mars3.debug_block_skip | off
mars3.debug_btree_bloomfilter | off
mars3.debug_btree_build_summary | off
mars3.debug_btree_minmax | off
mars3.debug_clean_ignore_successor | off
mars3.debug_columnstripereader | off
mars3.debug_indexrollback | off
mars3.debug_logicdecode | off
mars3.debug_thread_insert | off
mars3.debug_uniquemode_sortkey | on
mars3.debug_update_chain | off
mars3.debug_use_deltachain | off
mars3.default_btree_options |
mars3.default_storage_options | compresstype=none
mars3.disable_physical_tlist | on
mars3.enable_autofreeze | off
mars3.enable_block_sample | off
mars3.enable_block_skip | on
mars3.enable_btree_bloomfilter | on
mars3.enable_btree_minmax | on
mars3.enable_inorderscan | on
mars3.enable_post_customscan_vectorize | on
mars3.force_allocate | off
mars3.freeze_in_compact | on
mars3.inplace_freeze_columnstore | off
mars3.mars3_autoprobe_blacklist_size | 1000
mars3.max_insert_threads | 2
mars3.punish_inorderscan | 1.15
mars3.test_print_index_info | off
mars3.trace_run_life | on
mars3.update_modcount | off
mars3.verify_rangefile | on
mars3_auto_analyze_projection | on
mars3_brin_buildsleep | 0
mars3_orderkey_contain_partkey | on
optimizer_enable_mars3_indexscan | on
(42 rows)Примечание:
Параметры GUC с префиксом debug/test предназначены для отладки, не используются в промышленной среде
Зачеркнутые параметры — устаревшие
| Параметр | Текущая установка | Значение (на русском) |
|---|---|---|
| mars3allow_alter_rewrite | off | Разрешить перезапись таблиц при выполнении ALTER. При изменении параметров хранения вызывает перезапись, для подтверждения операции необходимо явно использовать этот параметр. |
| mars3append_sync | off | Принудительно ожидать синхронизации. Управляет синхронностью mars3 при добавлении данных. |
| mars3archive_dontvacuum | off | Отключить выполнение vacuum при архивировании, упрощает отладку анализа. |
| mars3autoprobe_period | 0 | Период автоматического обнаружения задач сжатия (в секундах). Установка значения 0 отключает функцию автоматического обнаружения. |
| mars3autoprobe_retry | 2 | Количество повторных попыток для неуспешных задач. Значение 0 означает отсутствие повторных попыток. |
| mars3autoprobe_workers | 2 | Количество рабочих процессов для выполнения задач автоматического обнаружения (диапазон: 1-16). |
| mars3debug_block_skip | off | Включить отладочную информацию для операции пропуска блоков, используется для оптимизации логики пропуска блоков. |
| mars3debug_btree_bloomfilter | off | Вывести отладочную информацию для фильтра Блума B-дерева. |
| mars3debug_btree_build_summary | off | Вывести отладочную информацию при построении сводки B-дерева. |
| mars3debug_btree_minmax | off | Вывести отладочную информацию для проверки минимального/максимального значения в B-дереве. |
| mars3debug_clean_ignore_successor | off | Игнорировать последующие узлы при очистке операций. |
| mars3debug_columnstripecanreader | off | Отладить чтение данных ColumnStripeReader. |
| mars3debug_indexrollback | off | Вывести отладочную информацию для отката индекса, используется для анализа проблем с index rollback. |
| mars3debug_logicdecode | off | Отладить функцию логического декодирования. |
| mars3debug_thread_insert | off | Отладить много поточную вставку. |
| mars3debug_uniquemode_sortkey | off | Отладить сканирование по ключу сортировки в режиме уникального режима. |
| mars3debug_update_chain | off | Отладить логику обновления цепочки (update-chain), используется для анализа проблем с update-chain. |
| mars3debug_use_deltachain | off | Использовать цепочку дельт (delta chain) в режиме отладки. |
| mars3default_btree_options | (22) | Установить параметры по умолчанию для индексов B-дерева mars3 (например, compressstype, compresslevel, fillfactor, minmax, compressstid и т.д.). |
| mars3default_storage_options | compresstype=none | Установить параметры хранения по умолчанию для mars3 (например, compressstype, compresslevel, mars3options, encodechain, uniquemode и т.д.). |
| mars3disable_physical_list | off | Запретить физический список (list) для столбцов. |
| mars3enable_autofreeze | off | Включить автоматическую очистку (autofreeze) для mars3. |
| mars3enable_block_sample | off | Включить выборку по блокам для анализа статистики. |
| mars3enable_block_skip | on | mars3 использует оптимизацию на основе блоков по данным BRIN. По умолчанию BRIN может пропускать нерелевантные блоки при SeqScan, эту оптимизацию можно изменить через этот параметр. |
| mars3enable_btree_bloomfilter | on | Включить фильтр Блума для B-дерева. |
| mars3enable_btree_minmax | on | Включить проверку минимального/максимального значения для B-дерева. |
| mars3enable_inorderscan | on | Включить сканирование по порядку ключа сортировки (inorderscan). |
| mars3_enable_post_customscan_vectorize | on | Устарело; сейчас поддерживается только для ORCA для векторизации на основе bitmapscan. |
| mars3force_allocate | off | Принудительно выделить segment и run slot. Должен быть включен, только если при достижении предела размера run или segment невозможно записать данные. |
| mars3freeze_in_compact | on | Выполнять операцию freeze в процессе компакции. |
| mars3inplace_freeze_columnstore | off | Включить функцию встроенной заморозки (inplace freeze) для列存. |
| mars3_mars3autoprobe_blacklist_size | 1000 | Максимальный размер черного списка автоматического обнаружения, максимальное количество задач, которые можно пропустить. |
| mars3max_insert_threads | 2 | Количество рабочих потоков для однократной максимальной операции вставки (диапазон: 0-6). Значение 0 означает отсутствие параллелизма. |
| mars3punish_inorderscan | 1.15 | Коэффициент штрафа за стоимость неотсортированного порядка (inordercost) для mars3 (диапазон: 1.0-10.0), влияет на вероятность выбора сканирования по порядку оптимизатором. |
| mars3test_print_index_info | off | Только для тестирования, вывести дополнительную информацию об индексе. |
| mars3trace_run_life | on | Вывести отладочную информацию о жизненном цикле внутренних объектов mars3, используется для анализа проблем. По умолчанию true. |
| mars3update_modcount | on | Включить обновление счетчика количества изменений (modcount). |
| mars3verify_rangefile | on | Включить проверку данных диапазона (rangefile). По умолчанию true. |
| mars3_auto_analyze_projection | on | При автоматическом анализе только анализировать столбцы order by by, уменьшить количество анализа. |
| mars3_brin_buildsleep | 0 | Время сна (в миллисекундах) при построении индекса BRIN, диапазон: 0-600. Только для тестирования и отладки. |
| mars3_orderkey_contain_partkey | on | Ключ сортировки mars3 должен содержать в себе разделенный ключ (partkey). |
| optimizer_enable_mars3_indexscan | on | Оптимизатор ORCA поддерживает сканирование индексов mars3. |
CREATE EXTENSION matrixts;
CREATE TABLE t(
time timestamp with time zone,
tag_id int,
i4 int4,
i8 int8
)
USING MARS3
WITH (compresstype=zstd, compresslevel=3,compress_threshold=1200,
mars3options='rowstore_size=64,prefer_load_mode=normal,level_size_amplifier=8')
DISTRIBUTED BY (tag_id)
ORDER BY (time, tag_id);Алгоритмы сжатия lz4, zstd, zlib указываются в предложении WITH при создании таблицы:
=# WITH (compresstype=zstd, compresslevel=3, compress_threshold=1200)Описание параметров:
| Параметр | Значение по умолчанию | Мин. значение | Макс. значение | Описание |
|---|---|---|---|---|
| compress_threshold | 1200 | 1 | 8000 | Порог сжатия. Контролирует, сколько кортежей (Tuple) в одной таблице будет сжато за раз; это верхний предел количества кортежей, сжимаемых в одной ячейке. |
| compresstype | none | — | — | Алгоритм сжатия, поддерживаются zstd, zlib и lz4. |
| compresslevel | 0 | 1 | — | Уровень сжатия. Меньшее значение — быстрее сжатие, но хуже результат; большее значение — медленнее сжатие, но лучше результат. Диапазон допустимых значений зависит от алгоритма: 1. zstd: 1–192. zlib: 1–93. lz4: 1–20 |
При указании compresstype по умолчанию и отсутствии compresslevel значение по умолчанию для compresslevel — 1
При compresslevel > 0 и отсутствии compresstype значение по умолчанию для compresstype — zlib
Параметры для регулировки размера Run на уровне L0 (и косвенно на уровнях выше L1):
| Параметр | Единица | Значение по умолчанию | Диапазон значений | Описание |
|---|---|---|---|---|
| rowstore_size | МБ | 64 | 8 ~ 1024 | Управляет моментом переключения Run уровня L0. Когда объем данных превышает это значение, происходит переключение на следующий Run. |
Параметры для указания режима загрузки данных в MARS3:
| Параметр | Значение по умолчанию | Диапазон значений | Описание |
|---|---|---|---|
| prefer_load_mode | normal | normal / bulk | Режим загрузки данных. - normal: обычный режим. Новые данные сначала записываются в строковый Run уровня L0, после накопления до rowstore_size переносятся в колонный Run уровня L1. По сравнению с режимом bulk добавляется одна операция ввода-вывода, преобразование в колоночный формат становится асинхронным. Подходит для сценариев с высокочастотными мелкопакетными записями при достаточных ресурсах ввода-вывода и чувствительности к задержкам. - bulk: режим массовой загрузки. Данные напрямую записываются в колоночный Run уровня L1. По сравнению с режимом normal сокращается одна операция ввода-вывода, преобразование в колоночный формат становится синхронным. Подходит для сценариев с низкочастотными крупными пакетами записей при ограниченных ресурсах ввода-вывода и нечувствительности к задержкам. |
Параметры для указания коэффициента увеличения размера уровня:
| Параметр | Значение по умолчанию | Диапазон значений | Описание |
|---|---|---|---|
| level_size_amplifier | 8 | 1 ~ 1000 | Коэффициент увеличения размера уровня. Порог для запуска операции слияния на уровне вычисляется по формуле: rowstore_size * (level_size_amplifier ^ level). Чем больше значение, тем медленнее скорость чтения и быстрее скорость записи. Значение выбирается в зависимости от конкретного сценария (много записи/мало чтения, много чтения/мало записи, коэффициент сжатия и т.д.). Примечание: необходимо следить, чтобы количество run на каждом уровне не было слишком большим, иначе это повлияет на производительность запросов и даже может блокировать вставку новых данных. |
6.7.0
6.6.0
6.5.0
6.4.1
6.4.0
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть II)
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть I)
Модель потоковой обработки PostgreSQL
Эпоха ИИ: параллельные запросы — от «быстрого сканирования» к «быстрому вычислению»
Новый фундамент баз данных в эпоху ИИ: исследование векторизованного выполнения в PostgreSQL