
在物联网和实时数仓场景中,数据的高速写入能力至关重要,直接影响产品方案的可用性、可靠性和扩展性。以物联网为例,当面临千万甚至上亿设备、平均每个设备采集几十个到几百个指标时,每秒生成的数据将达到数十亿至数百亿。能否及时可靠的插入这种量级的数据,是评价一个时序数据库的核心要素和第一需求。
物联网时序数据具有“写多读少”特征,据统计,其中 95% 甚至 99% 以上是数据写入操作,从这个意义上讲,怎么重视数据写入能力都不为过。
为了应对这种高通量数据写入需求,一些产品采用无事务或者弱事务的方式来提高写入速度,这样造成错误数据、重复数据或者丢失数据。MatrixDB 通过 MatrixGate 组件,创新性的在保证事务严格一致性(ACID)的前提下,支持大吞吐量数据高速写入。同时,产品具有良好的线性扩展性,可以通过添加节点的方式,线性提升系统的写入速度,满足车联网、工业互联网、智能家居、智能城市等各种物联网场景的数据写入需求。
在这篇博客中,将详细介绍在同样环境下 MatrixDB、InfluxDB 和 TDengine 三个产品的写入能力。主要测试结果概述如下:
本文采用行/每秒衡量数据写入能力,有的文章使用数据点/秒,这两种方式可以互换,譬如一张表有时间列、设备 ID 列和 5个指标列,那么插入一行数据就意味着插入 5个数据点,如果一秒插入 1000行,那么写入能力是每秒 5000个数据点。
根据不同的用户使用场景,我们定义了小规模、中规模和大规模三种不同的测试场景,数据采集间隔均为 60 秒。具体特征如下:
| 规模 | 说明 |
|---|---|
| 小规模 | 分别为 10万、20万、50万、100万设备, 生成 1列 int 型数据 |
| 中等规模 | 10万设备,分别生成 10、50、100、400列 int 型数据 |
| 大规模 | 100万设备,分别生成 100、200、400、800列 int 型数据 |
针对每种测试用例,分别使用三种产品各自推荐的快速写入方式取得最高值,测试结果如下(单位: 行/秒),其中小规模选择 100万设备及 1列指标数据、中等规模选择 10万设备及 400列指标数据、大规模选择100万设备及800列指标数据:
| MatrixDB | InfluxDB | TDengine | |
|---|---|---|---|
| 小规模 | 2779126 | 263974 | 2064622 |
| 中等规模 | 167507 | 2268 | 5853 |
| 大规模 | 93988 | 1202 | 2427 |
MatrixDB与两个产品的写入速度之比分别是:
| MatrixDB vs TDengine | MatrixDB vs InfluxDB | |
|---|---|---|
| 小规模 | 1.3 | 10.5 |
| 中等规模 | 28.6 | 73.8 |
| 大规模 | 38.7 | 78.2 |
综上,在三种场景下,写入性能从高到低分别是:MatrixDB > TDengine > InfluxDB
值得一提的是,三个产品的事务支持是不一样的,MatrixDB 在单节点和集群多节点都支持完整严格的事务,包括原子性(A)、一致性(C)、隔离性(I)和持久性(D),InfluxDB 和T Dengine 不支持事务。测试时,也注意到不同产品内存消耗不同,MatrixDB 内存占用较小较平稳,InfluxDB 内存占用较多,TDengine 内存消耗最多并且与设备数正相关,例如在 500万设备时,内存占用会超过 80G。
MatrixDB、InfluxDB、TDengine 均采用单机部署。 机器配置如下:
| cpu 核数 | 2v物理核 32v逻辑核 |
|---|---|
| 内存 | 256GB |
| CPU平台 | Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz |
| 储存大小 | 9.0TB(1.4 GB/秒写入,3.3 GB/秒读取) |
| linux 发行版 | CentOS Linux release 7.8.2003 (Core) |
| linux 内核 | 3.10.0-1127.el7.x86_64 |
软件版本
| 数据库类型 | 版本 |
|---|---|
| MatrixDB | MatrixDB 3.3.0-community |
| InfluxDB | InfluxDB 1.8.3 |
| TDengine | taos 2.0.16.0 |
参数调整
| 库名 | 参数 |
|---|---|
| MatrixDB | max_wal_size=150GB;wal_buffers=256MB;shared_buffers=5G |
| InfluxDB | cache-max-memory-size=10GB;max-values-per-tag = 0 |
| TDengine | numOfCommitThreads 4 |
数据通过 tsbs_generate_data 工具生成。tsbs_generate_data 是开源时序数据测评基准tsbs中的数据生成工具。MatrixDB 团队扩充了该工具以支持大规模设备场景,通过参数--use-case="massiveiot"来使用,可以在百度网盘https://pan.baidu.com/s/1BFYcQR3DzqVLiy8ymXu9eg (提取码:8cba)下载该工具。
tsbs_generate_data 命令常用参数说明如下:
--format="MatrixDB" //指定数据格式名称,使用MatrixDB,表示生成大规模iot数据
--use-case="massiveiot" //生成的场景,填massiveiot
--scale="100000" //规模参数,相当于设备数
--log-interval=60s //生成数据的频率,默认是60秒
--column-data-type=simple //列类型,simple表示简单类型
--point-type=int //表示数据是int类型
--columns-per-row=1 //列数
--timestamp-start //开始时间,默认是 "2016-01-01T00:00:00Z"
-timestamp-end //结束时间,默认是 "2016-01-02T00:00:00Z"详细的数据生成方法和命令,请参考文末链接《时序数据库写入性能测试过程》。
| 文件名 | 设备数 | 列数 | 容量 | 行数 |
|---|---|---|---|---|
| cpu_1_10w.csv | 10万 | 1 | 4.9G | 144,000,000 |
| cpu_1_20w.csv | 20万 | 1 | 10G | 288,000,000 |
| cpu_1_50w.csv | 50万 | 1 | 26G | 720,000,000 |
| cpu_1_100w.csv | 100万 | 1 | 51G | 1,440,000,000 |
| 文件名 | 设备数 | 列数 | 容量 | 行数 |
|---|---|---|---|---|
| cpu_10_10w.csv | 10万 | 10 | 18G | 144,000,000 |
| cpu_50_10w.csv | 10万 | 50 | 75G | 144,000,000 |
| cpu_100_10w.csv | 10万 | 100 | 146G | 144,000,000 |
| cpu_400_10w.csv | 10万 | 400 | 400G | 144,000,000 |
| 文件名 | 设备数 | 列数 | 容量 | 行数 |
|---|---|---|---|---|
| cpu_100_100w.csv | 100万 | 100 | 1460GB | 144,000,000 |
| cpu_200_100w.csv | 100万 | 200 | 2920GB | 144,000,000 |
| cpu_400_100w.csv | 100万 | 400 | 4000GB | 144,000,000 |
| cpu_800_100w.csv | 100万 | 800 | 8000GB | 144,000,000 |
由于 InfluxDB/TDEngine 在列数超过 100列时较慢,为避免写入时间过长,测试中采取限定时间范围方法:
100万设备, 100列,限定采集 2小时数据
100万设备, 200列,限定采集 1小时数据
100万设备, 400列,限定采集 30分钟数据
100万设备, 800列,限定采集 15分钟数据
限定时间范围后,实际数据大小如下:
| 文件名 | 设备数 | 列数 | 容量 | 行数 |
|---|---|---|---|---|
| cpu_100_100w.csv | 100万 | 100 | 122G | 120,000,000 |
| cpu_100_100w.csv | 100万 | 200 | 120G | 60,000,000 |
| cpu_100_100w.csv | 100万 | 400 | 119G | 30,000,000 |
| cpu_100_100w.csv | 100万 | 800 | 119G | 15,000,000 |
每种产品使用的写入方式如下:
| 产品名称 | 写入方式 | 说明 |
|---|---|---|
| MatrixDB | mxgate | mxgate 写入 csv 格式数据 |
| InfluxDB | tsbs_load_influx | 因为 tsbs_load_influx 不支持直接写入 csv 格式数据,故从 MatrixDB 按 InfluxDB 行协议导出数据,通过 tsbs_load_influx 写入到InfluxDB |
| TDengine | taosdemox | TDengine 是 taosdemox 生成数据,同时,写入TDengine |
值越大代表写入性能越好

| 列数 | 设备数 | MatrixDB/InfluxDB |
|---|---|---|
| 1 | 10万 | 11.6 |
| 1 | 20万 | 11.1 |
| 1 | 50万 | 11.5 |
| 1 | 100万 | 10.5 |
| 列数 | 设备数 | MatrixDB/TDengine |
|---|---|---|
| 1 | 10万 | 2 |
| 1 | 20万 | 1.7 |
| 1 | 50万 | 1.5 |
| 1 | 100万 | 1.3 |
值越大代表写入性能越好
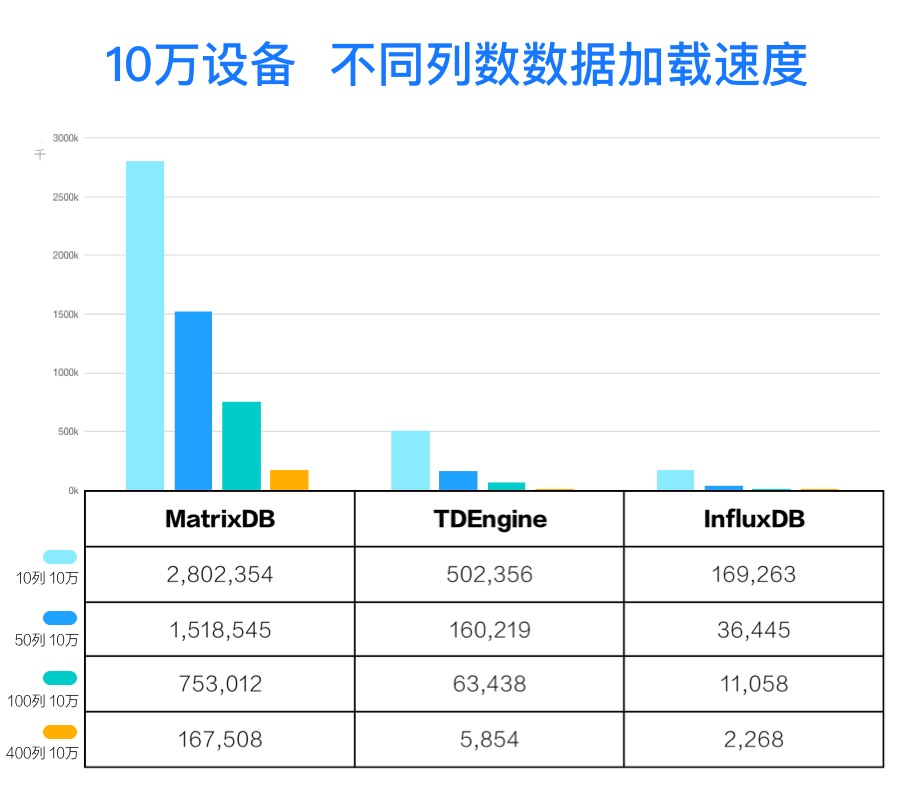
| 列数 | 设备数 | MatrixDB/InfluxDB |
|---|---|---|
| 10 | 10万 | 16.6 |
| 50 | 10万 | 41.7 |
| 100 | 10万 | 68.1 |
| 400 | 10万 | 73.8 |
备注: 如果 InfluxDB 全量写入,按 400列的 2268.06行每秒的写入速度计算,14.4亿行,需要费时 1058 分钟,而 MatrixDB 只需要 14 分钟,相比之下 InfluxDB 写入速度太慢。故 InfluxDB 10列、50列,只写入1千万行,InfluxDB 100列,只写入 100万行,400列,只写入 10万行。
| 列数 | 设备数 | MatrixDB/TDengine |
|---|---|---|
| 10 | 10万 | 5.6 |
| 50 | 10万 | 9.5 |
| 100 | 10万 | 11。9 |
| 400 | 10万 | 28.6 |
备注: 按 TDengine 100列全量写入需要 262 分钟计算,400列估算需要 1050分钟,而MatrixDB 最快仅需要 14 分钟。10万设备数 400列,相比之下写入速度太慢、费时太久,故设置 1000个设备,然后推导出 10万设备所需时间。
值越大代表写入性能越好
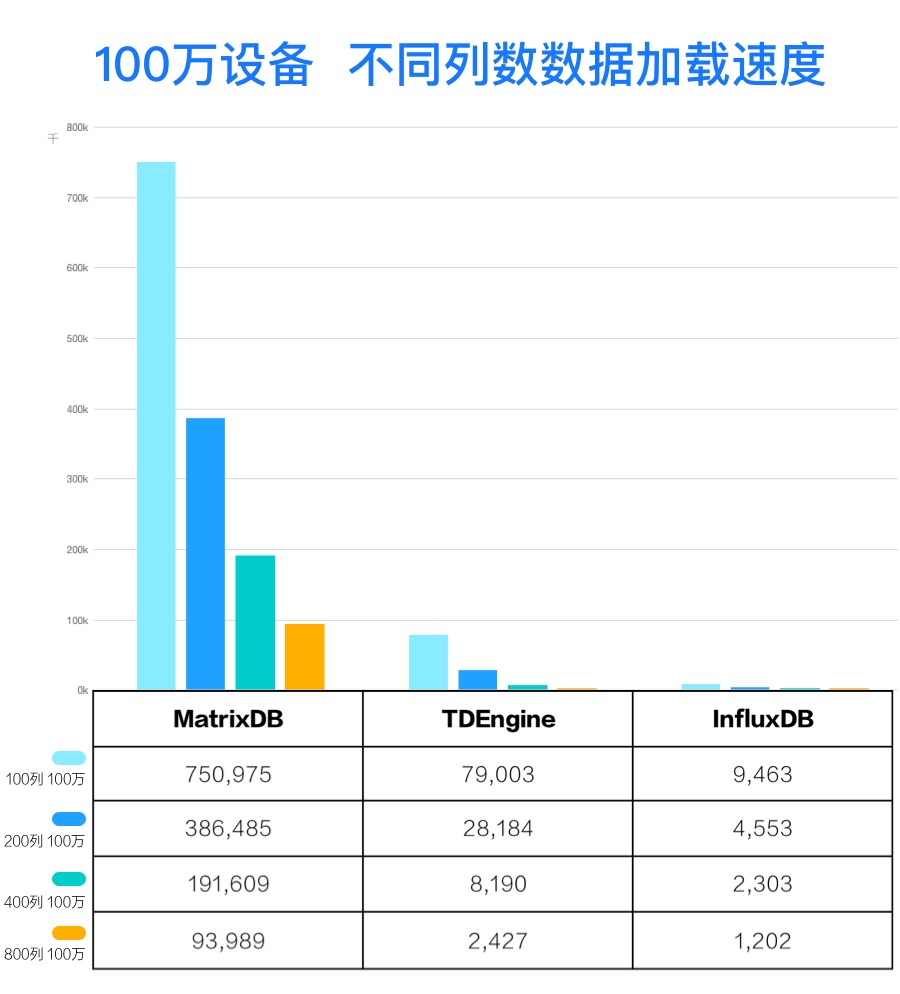
| 列数 | 设备数 | MatrixDB/InfluxDB |
|---|---|---|
| 100 | 100万 | 16.6 |
| 200 | 100万 | 41.7 |
| 500 | 100万 | 68.1 |
| 800 | 100万 | 73.8 |
备注: 如果 InfluxDB 全量写入,按10万设备量 400列 2268.06行每秒的写入速度计算,14.4亿行,需要费时 1058 分钟,100 万设备量估算需要花费 10580 分钟,耗时太久。为避免 InfluxDB写入费时太长,InfluxDB 100万设备数、100列和200列,只写入100万行,400、800列只写入 10万行,然后同比推导出结果数据。
| 列数 | 设备数 | MatrixDB/TDengine |
|---|---|---|
| 100 | 100万 | 9.2 |
| 200 | 100万 | 13.7 |
| 400 | 100万 | 23.4 |
| 800 | 100万 | 38.7 |
备注: TDengine按 10万设备数、100列全量写入需要 262分钟计算,400列估算需要 1050 分钟,而 MatrixDB 400列最快仅需要 14 分钟,100万设备数,相比之下写入速度太慢、避免写入费时太久,故 TDengine 100、200、400、800列,设置的是 1000个设备,然后同比推导出结果数据。






