
在介绍存储引擎之前,先介绍一下数据存储常用的几种方式:
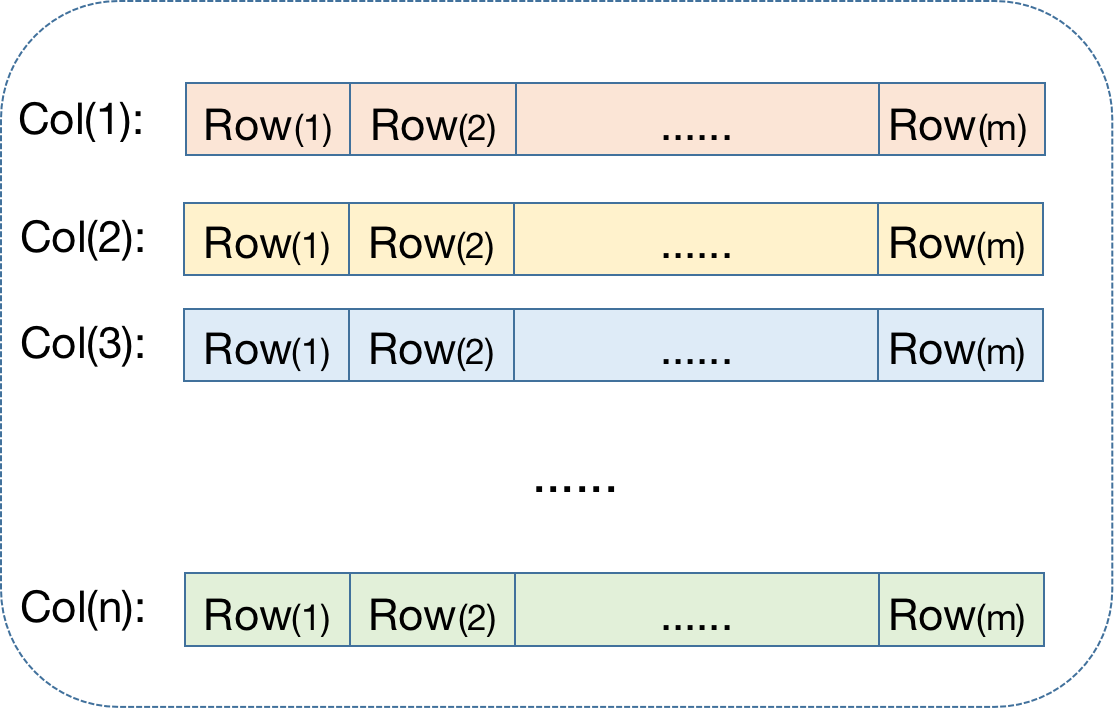
行存,如下图所示,数据按行存储。同一行中不同的列存储在一起:
 列存,与行存相对应,数据按列存储。不同行中相同的列存储在一起:
列存,与行存相对应,数据按列存储。不同行中相同的列存储在一起:
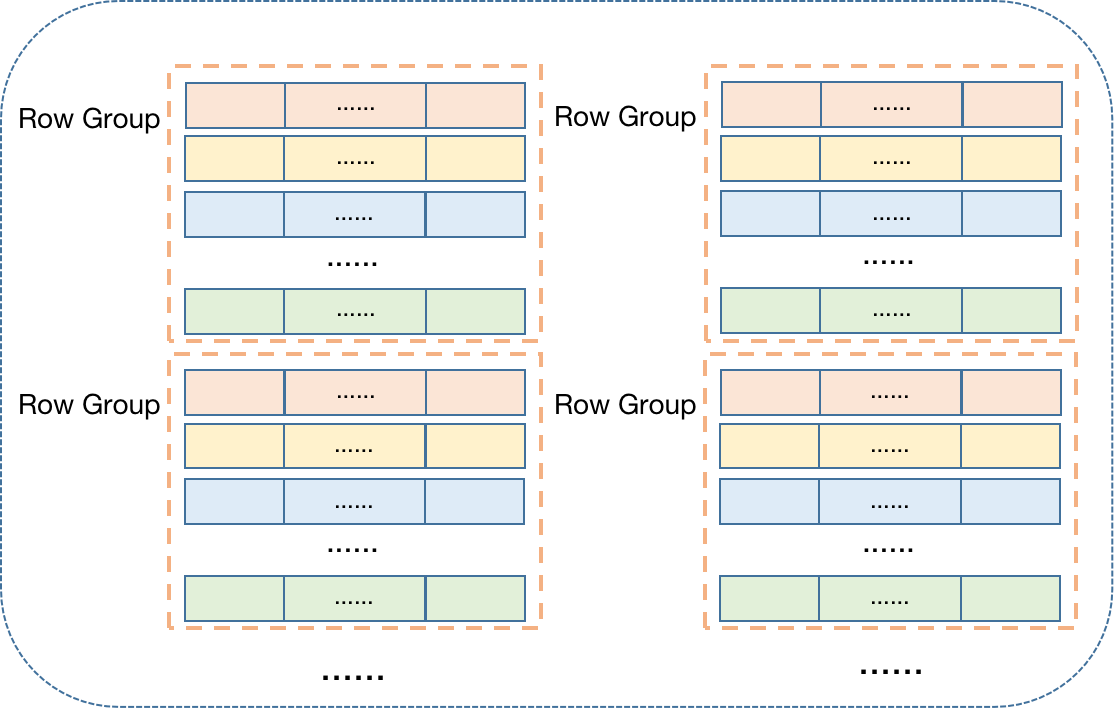
行列混存,兼具了行存和列存的特点,按照行分了若干组,每个组中按列存储:
MatrixDB提供了 Heap 和 Mars 两种存储引擎,分别支持行存和行列混存两种存储方式。
Heap 存储引擎是行存方式,是 MatrixDB 建表时使用的默认存储引擎。
如下图所示,每个Heap表对应一个数据文件(上限1G,超过会增加),数据文件由Block构成,每个Block内存储了表中的多个行:
 Heap 表数据存储并无顺序,按照插入先后顺序存储。所以,对 Heap 表基于键值快速检索要额外建立索引,最常用的就是 BTree 索引。
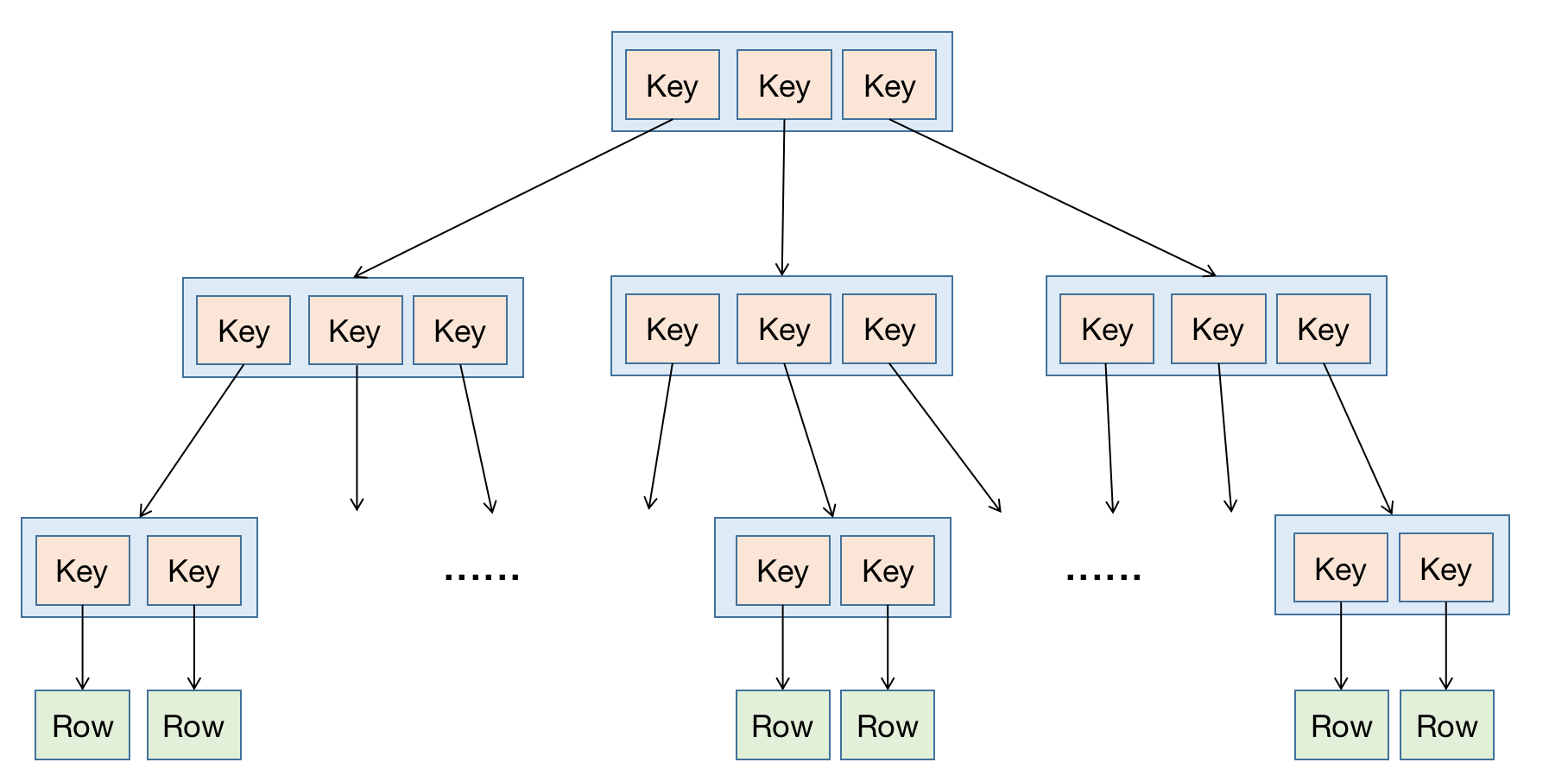
Heap 表数据存储并无顺序,按照插入先后顺序存储。所以,对 Heap 表基于键值快速检索要额外建立索引,最常用的就是 BTree 索引。
如下图所示,BTree 索引是一颗高度平衡树,数据索引存储在叶子节点中,指向数据所在行:
Mars 存储引擎是 MatrixDB 自研的存储引擎,是行列混存。
Mars引 擎包含两个重要的概念
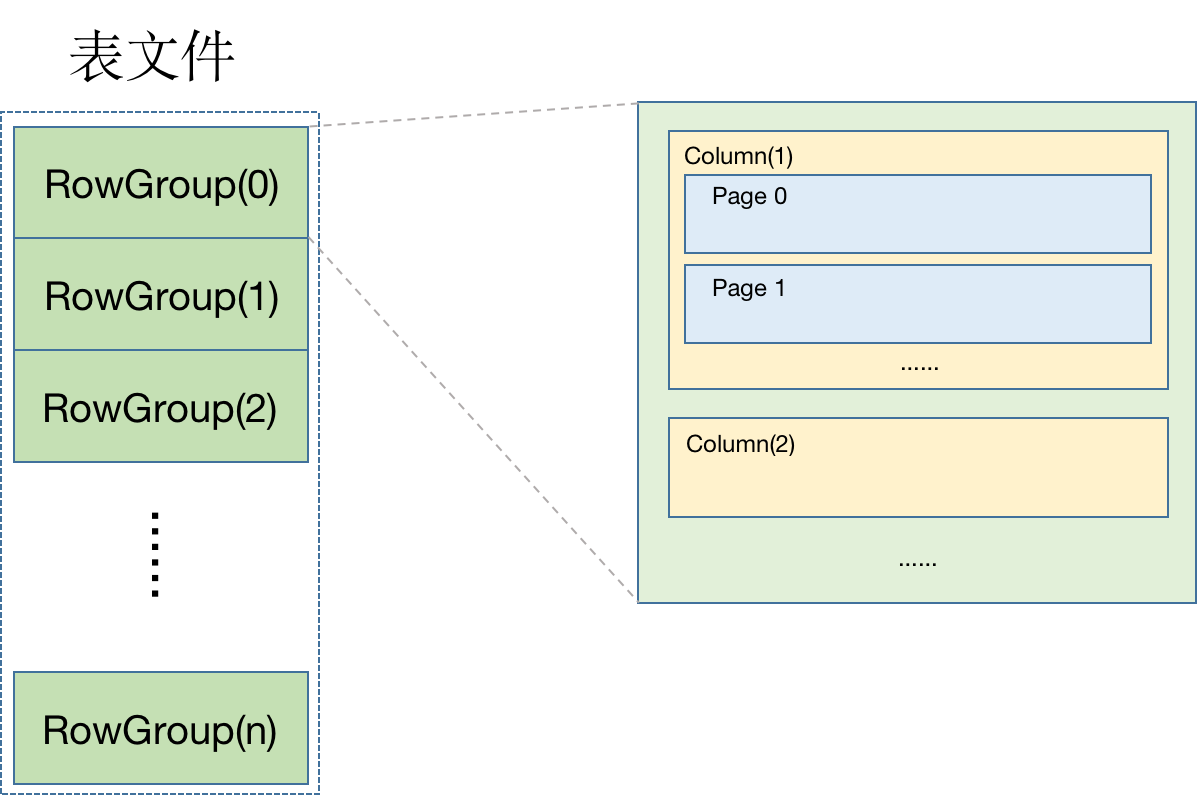
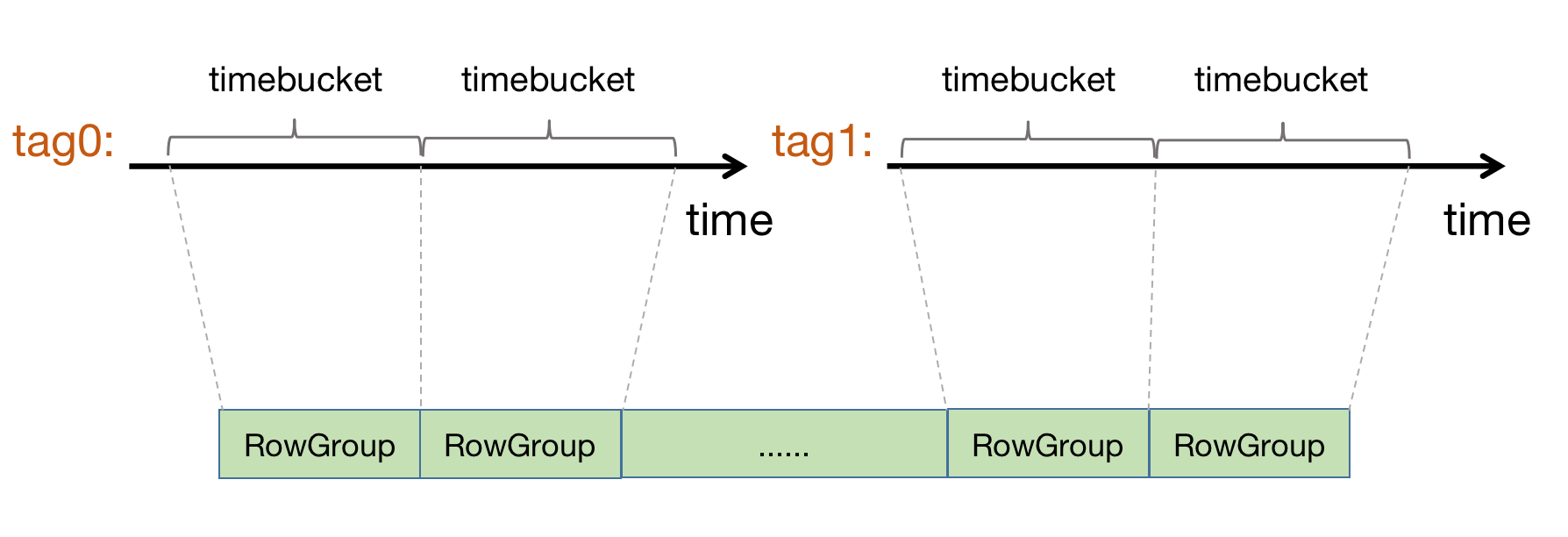
如图所示,Mars 引擎中数据是按 Row Group 组织起来的,每个 Row Group 包含了一组有序存储的行。Row Group 内部按列分页存储:
那么一个 Row Group中 要存储多少行呢?这取决于建表时定义的 time bucket。作为时序数据库,所有数据都是来自设备,会包含设备id(tag_id)和时间戳。
所以,当新数据时间戳超过 time bucket 阈值或设备 ID 变化的时候,就会创建新的 Row Group。Row Group 内部数据有序存放。
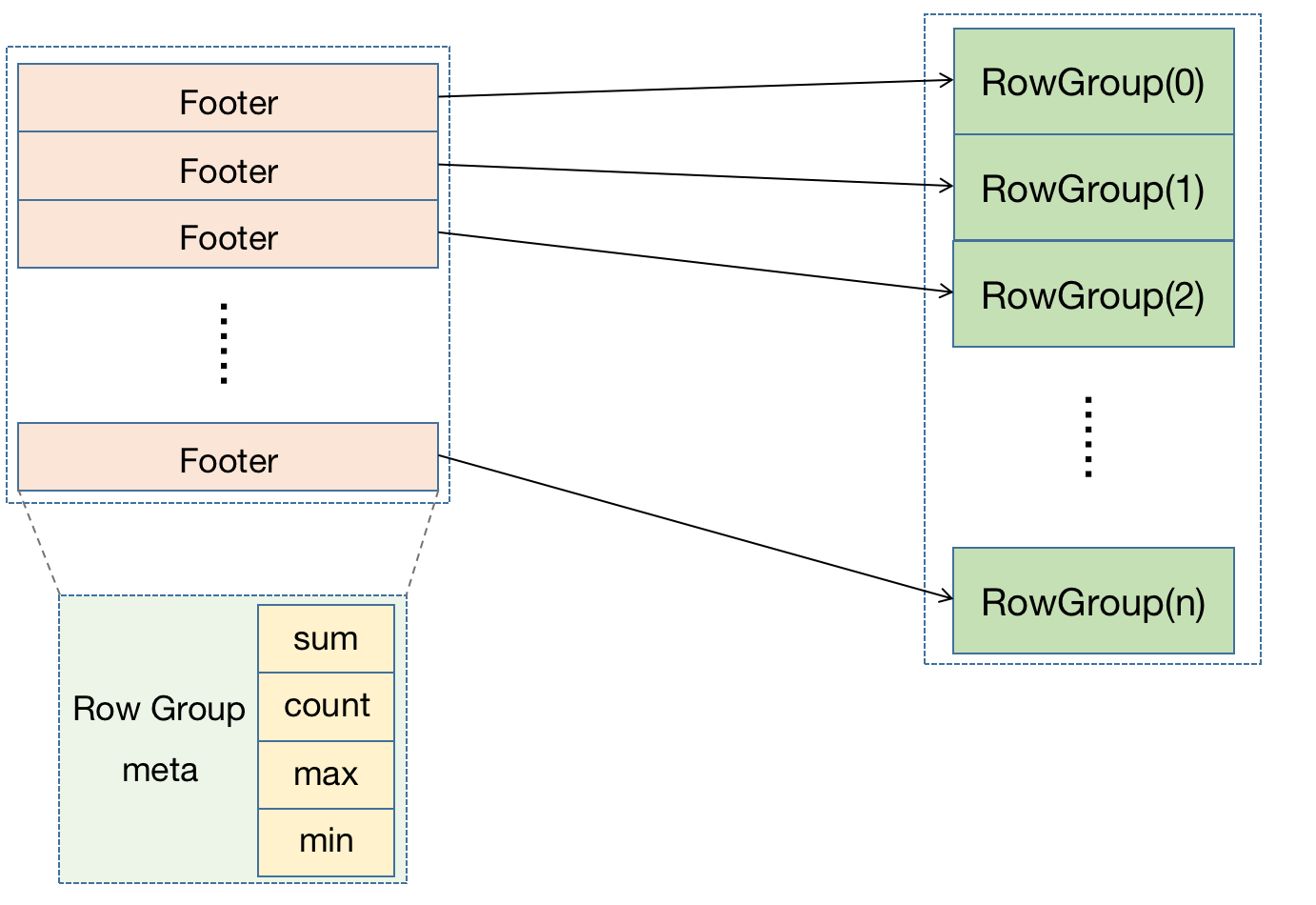
Footer 存储了 Row Group 的元数据,如:行数、累计和、最大值、最小值,相当于 Row Group 的稀疏索引。在MatrixDB 中每个 Row Group 对应一个 Footer,存储在独立的文件中:
从前面了解到Mars引擎的数据存储有如下特征:
基于如上特征,可以对查询执行做如下优化:
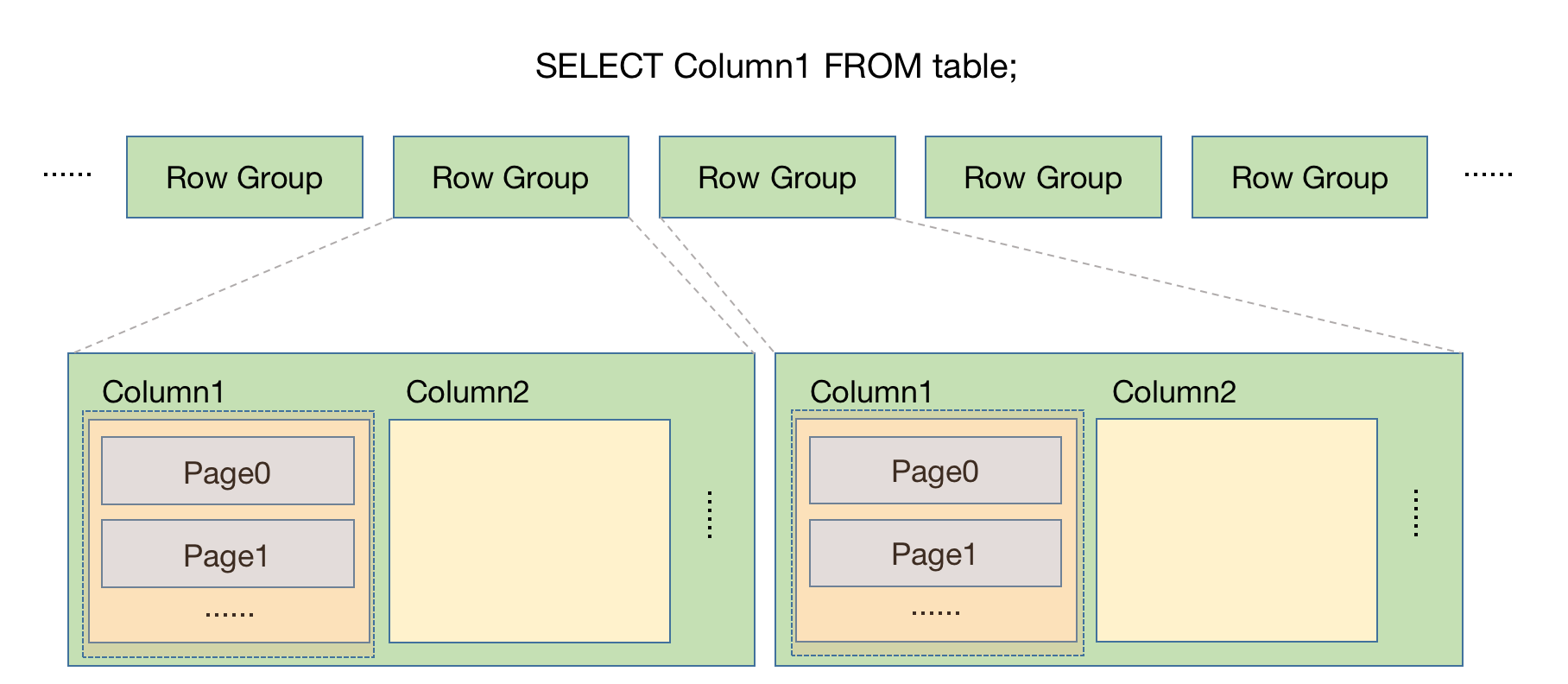
如果查询中只指定了部分列,则可以使用列裁剪,即在数据扫描时跳过不需要的页。
如下图所示,当只查询 Column1 的时候,做 Scan 只读取 Row Group 中 Column1 的相关页即可,大大减少了 IO 操作,这也是列存的好处。
因为每个 Row Group 的 MIN 与 MAX都已知晓,所以在做条件扫描的时候就可以根据扫描条件和每个 Row Group 的最大值、最小值来决定是否需要进行裁剪。
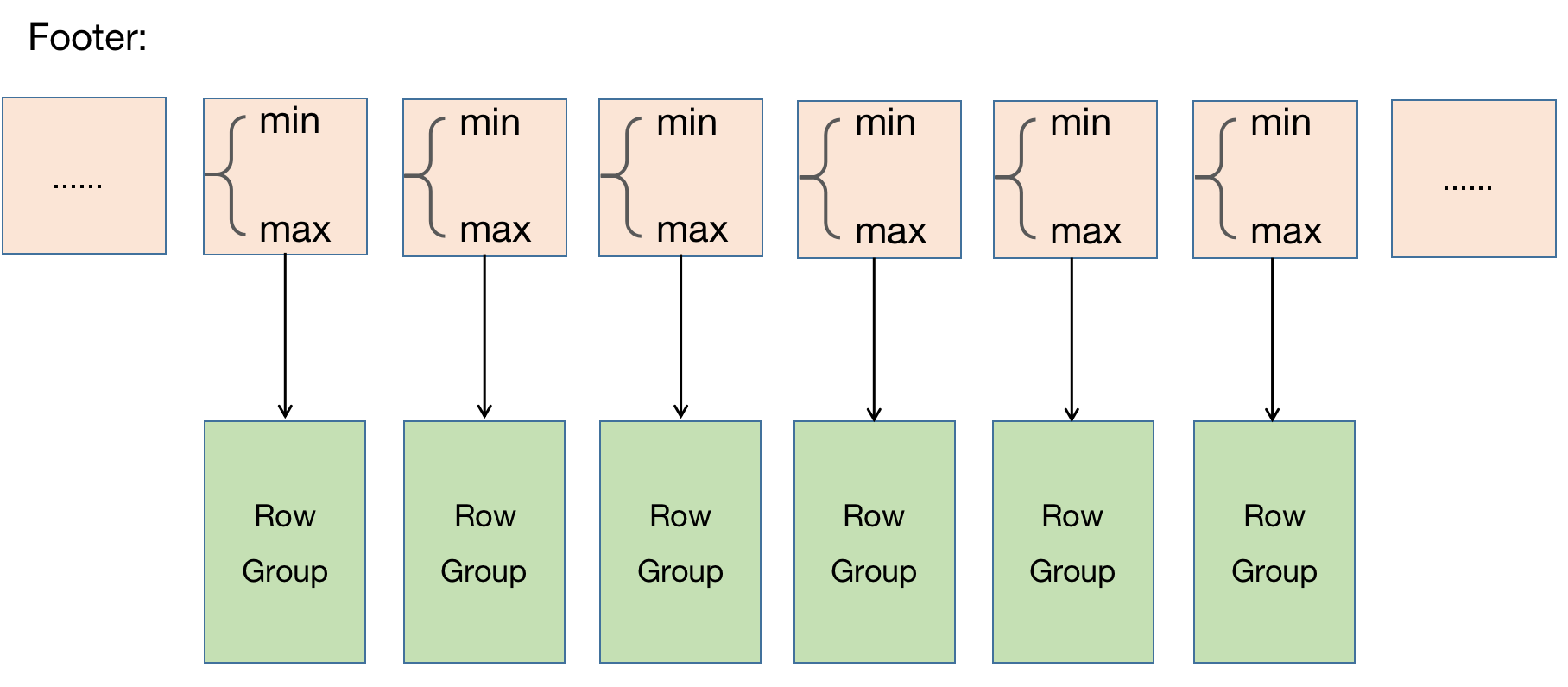
如下条件可以利用裁剪:
SQL 样例:SELECT * FROM table WHERE c1 = v0; 等值条件 SQL,如果目标值在最小值和最大值范围内,则对 Row Group 进行扫描,否则跳过:
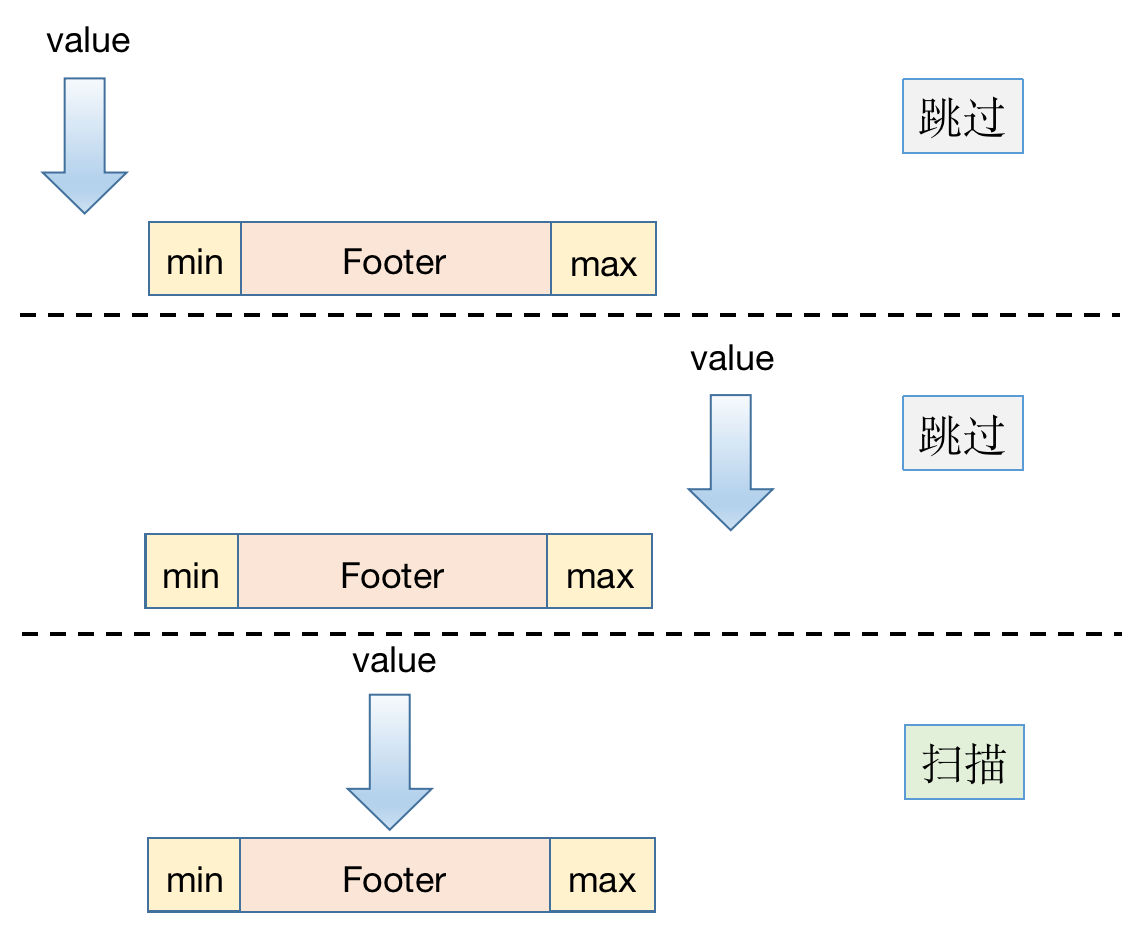
SQL 样例:SELECT * FROM table WHERE c1 >= v0; 当比较值小于等于最大值 max 的时候,需要进行扫描;否则跳过:
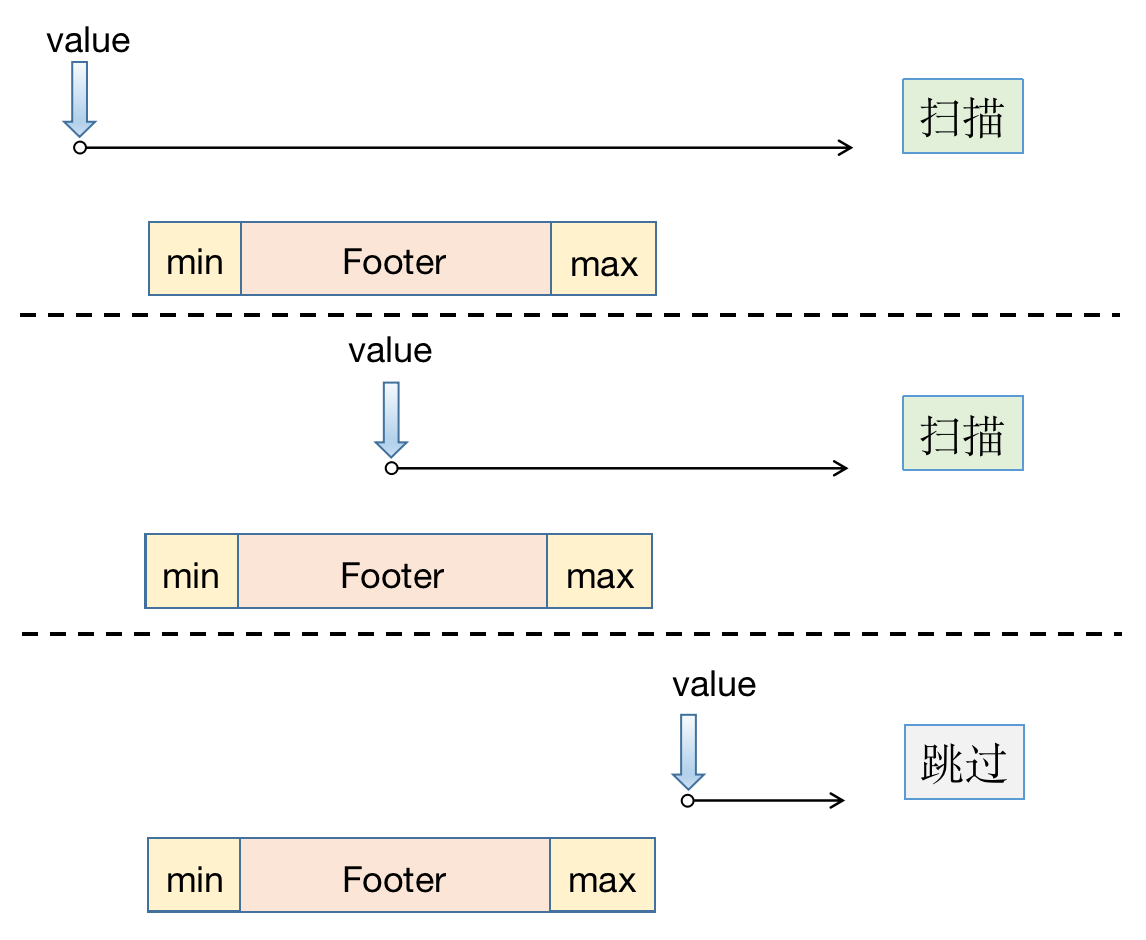
SQL 样例:SELECT * FROM table WHERE c1






