
MatrixDB 直播教程第二期,介绍了高性能数据加载工具 MatrixGate,给大家精剪了回放视频,可以在线回看直播啦!
本文主要分享 4 个内容:
MatrixDB 作为一款分布式、高性能,需要处理超大规模数据的数据库产品,在数据加载的过程中难免会遇到一些挑战和需求,对数据加载的速度、吞吐量及实时性要求都非常高。
在客户复杂的业务场景下,我们对数据加载的普遍需求是,将不同类型的数据源数据和不同格式的数据都要能够兼容,统一加载到 MatrixDB 里。
产品的易用性和稳定性也非常重要,易用性做的不够好,就不是合格的产品,所以在易用性这块我们也是孜孜不倦的追求;稳定性测试也是非常严苛,每一次版本 release 都要保证以年为单位的稳定运行,并能支持客户关键的业务场景。
可以总结出,MatrixDB 在兼容、易用性、稳定性、性能和功能等诸多方面持续迭代增强与优化升级。
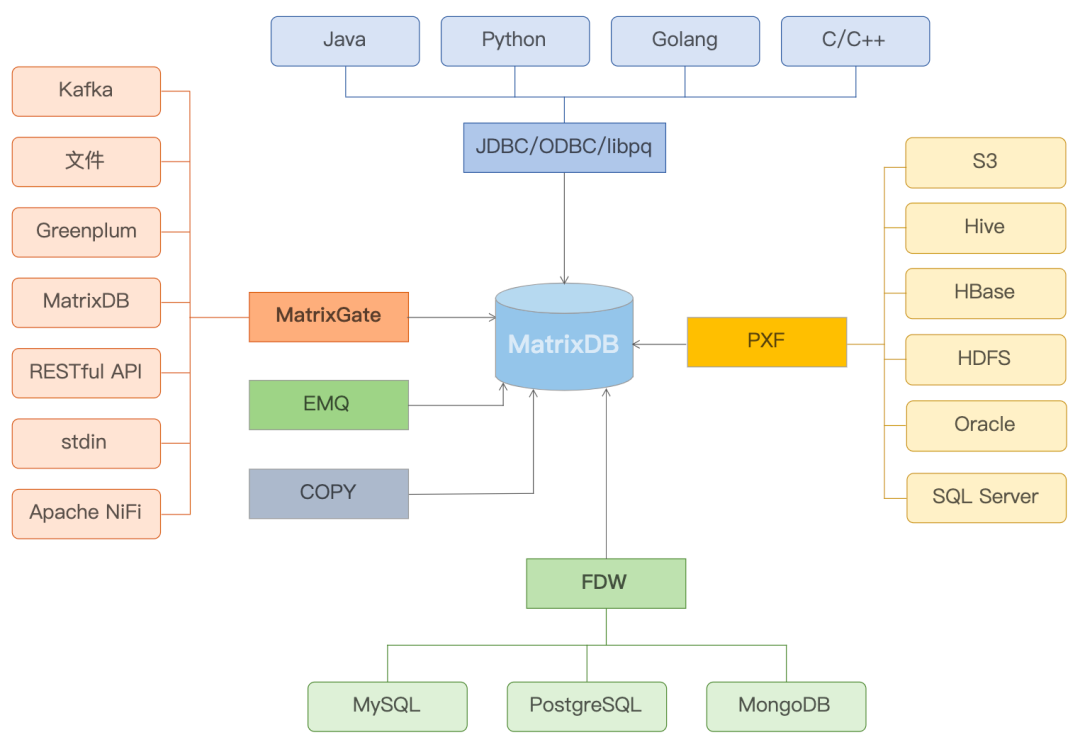
从 MatrixDB 全景图可以看出,通过各种不同手段和方式将不同的数据源载入到 MatrixDB,比如 FDW ,将 MySQL / PostgreSQL / MongoDB 的数据载入到 MatrixDB 中,还可以使用 PXF 将来自 S3 / Hive / HBase 等不同的数据源载入。
大家经常使用到的 JDBC / ODBC / libpq,比如通用 Java / Python / Golang / C / C++ 方式编程,然后对数据库进行读写,且可以通过 MatrixGate 将 Kafka、文件、 Greenplum 等不同形式的数据导入到 MatrixDB 中。
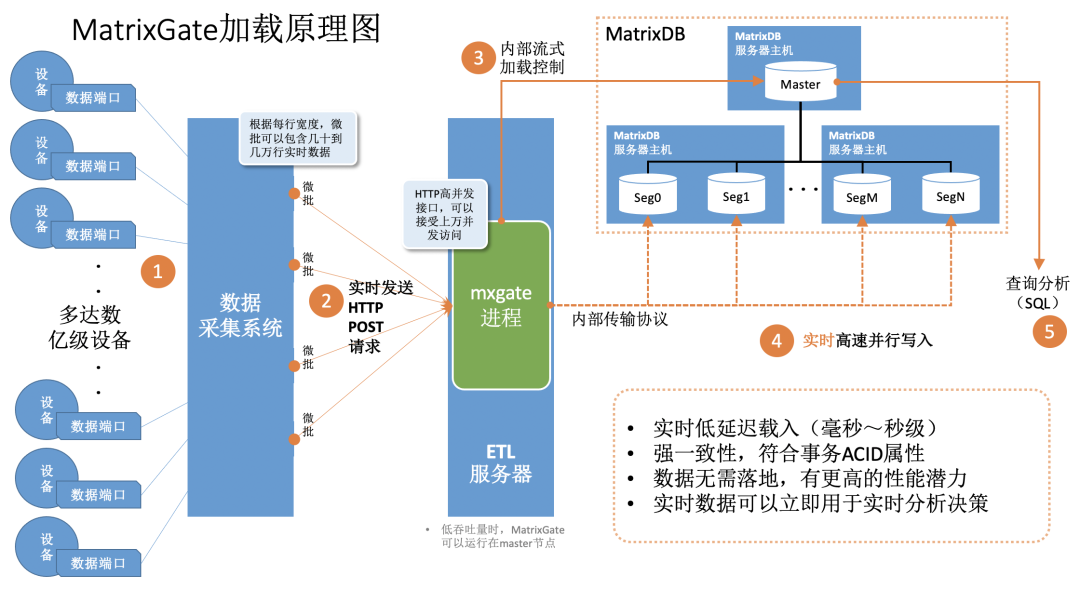
MatrixGate 主要特点在于它是一个高并发加载组件,采用一个多节点并行的写入机制,加载性能远高于原生的 Insert 语句。在大规模的生产环境下,全速写入速度可以达到 1 亿点每秒,比 Insert 语域加载速度要快好几个数量级。
通过上图我们可以看到 MatrixGate 在整个数据加载环节中,扮演了一个后端数据库和前端数据采集系统的一个“中间人”角色。
在后端,MatrixGate 通过内部传输我们自定义的一个协议,和多个 Segment 之间直接建立多个并行的连接,数据就可以并行的写入到多个数据节点上;在前端,MatrixGate 的进程作为一个 HTTP Server 的服务,可以同时支持上万个 HTTP Client 并发的连接,每个 Client 可以实时将采集到的数据发送到 MatrixGate 中。
MatrixGate 内部,我们实现了一个非常精妙的微批流式控制,保证每一个 HTTP Client 发送的数据,在以秒级到毫秒级的延迟就可以写入到数据库并行落盘,数据一旦写入完成之后,就可以立即可查,并保证满足了 ACID 强一致性。数据在整个 MatrixGate 中是没有落盘操作的,所以说有着非常高的吞吐量和性能。

总结下来,MatrixGate 主要特点具有以下 4 个方面:
MatrixGate 和所有的数据节点直接相连,不走 master ,就不会有单点瓶颈。在并行流式数据加载的情况下,可以保证高性能、实时性和稳定性。
支持多种不同的数据格式,如:CSV / Text / JSON。
支持多种不同格式数据源,通过 HTTP / Kafka / Stdin / Greenplum 或者 MatrixDB 等不同的数据源,直接通过 MatrixGate 把数据导入到 MatrixDB 中。
MatrixGate 轻松简单易上手,在接下来的演示中,大家可以有一个更直观的体会。

这次演示,我在云上的虚拟机搭建一个集群,集群的配置非常一般。
MatrixDB 集群的配置如上,同时,我还搭建了一个 Kafka 单机节点,便于演示将 Kafka 数据导入到 MatrixDB 中。
为什么会使用这样非常低配置的集群呢?
目的是让大家能够更加直观的感受到,即使在如此低的配置集群上,MatrixGate 依然具有非常强悍的性能。如果说在生产环境下,随着集群规模的扩张,性能的提升,那么 MatrixGate 的加载性能还会数量级的提升。
这次我操作了 4 种数据源,依次分别是:HTTP,Kafka,Stdin,Transfer(大家可以依需求查看相应视频~~)
MatrixGate 作为 HTTP Server,支持多个 HTTP Client 并发的数据写入。通过视频可以看出 2 分钟的时间,写入 1000 万数据,对方只是一个单台的服务器在向我们发数据;如果是多台服务器的话,MatrixGate 连接到一个更大的集群上,性能也会成倍的在扩展。
Kafka 是一个普遍使用的消息队列,应用非常广泛,如何把 Kafka 的数据直接写入到 MatrixDB 中?

在 MatrixGate 中,具体的逻辑就是 MatrixGate 内部会针对每一个 Topic 下的每一个 Partition,我们都会实现一个对应的协程。
这个协程就相当于扮演了当前 Partition 的一个消费者的角色,源源不断的从 Partition 手中拉取对应的消息,然后并行的写入到数据节点中。
当前支持2种数据类型:CSV,JSON。CSV 结构化数据,我们从 Kafka 中获取后,可以直接写入到 MatrixDB 中,JSON 这种非结构化数据,还需要做一个转换。
这种转换通常情况下由客户的业务开发来完成,但这样就相当于客户要做更多的工作。为了减轻用户的工作量,MatrixGate 内部也支持从 JSON 到 CSV 的转换,通过简单的界面的配置就可以实现,轻松的就可以把数据直接导入到数据库中。
接下来我们演示如何通过 MatrixGate 来消费 Kafka 中 CSV 数据,可以看到在 27 秒左右的时间,340 行数据就已经写入到数据库中。
通过加载文件的方式,比如,我要将一个很大的 CSV 文件直接加载到数据库中,不需要编写程序来处理这个文件。这个时候有没有更轻松简单的方式?
MatrixGate 来告诉你,是有的,而且非常的简单!
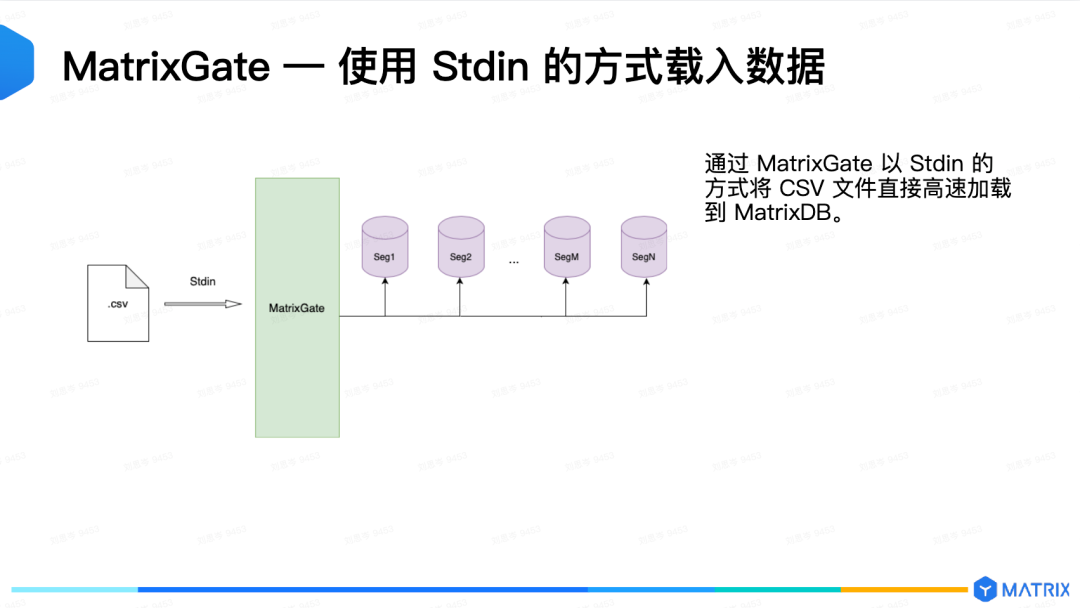
mxgated \
--source stdin \
--db-database demo \
--db-master-host 127.0.0.1 \
--db-master-port 5432 \
--db-user mxadmin \
--time-format unix-nano \
--delimiter "|" \
--target csvtable \
--parallel 2





