
工程车辆是特种车辆的一种。混凝土搅拌车、自卸车、压路机、混凝土泵车等专用于工程领域的车辆都可以被称为工程车辆。得益于近些年我国新基建的蓬勃发展,我国的工程车辆行业已逐渐进入世界主舞台,很多行业龙头在很多子领域做到了世界第一第二。市场也蓬勃发展,近年来,以混凝土泵车为例,我国的保有量已近七成。在行业欣欣向荣之余,业内的龙头企业也有着担忧。相比于家用汽车,工程车辆的智能化还处于转型起步阶段。企业在新的领域若无法迎头赶上,往往处于不翻身就翻盘的尴尬。

车辆健康状态、赚了多少钱、更多赚钱机会、车辆残值
不同于家用汽车,工程车辆更多的定位是生产资料,或者叫赚钱工具。客户比家用汽车车主更依赖车辆的全周期智能运维。因为往往客户会雇佣司机与操作员来通过车辆完成指定的工程任务,所以客户更加关心车辆的实时位置与实时健康状态、是否有疑似偷油偷料的现象发生。同时需要借由智能化的平台来获得客源、降低调度成本、评估车辆残值等。这些功能中,大部分的指标依赖于车辆本身回传数据的专业计算结果。
大数据平台接入来自数万台设备的几千个工况参数的数据,每日回传数据在十亿条至百亿条左右,以实现每天每台设备的指标计算、智能巡检、模型训练和时序数据的展示。客户通常采用 Hadoop + Spark 的传统大数据架构,该架构遇到四个方面的挑战:
传统的 Hadoop + Spark 架构需要搭建 CDH 等大数据全家桶,包括 Hadoop(负责存储原始数据)、Spark(负责每日任务)、Hive(负责临时离线任务)、HBase(负责数据展示),构成复杂的技术栈。为了满足不同服务的需求,数据会同时以不同形式存在不同的组件中,浪费资源也给运维带来了极大的不便,过多的技术栈也不利于团队成员的配置和培养,招人难,培养人难,留人更难。
工况数据具有时序性。在设备工作时,由于各种无法预计的情况导致数据无法整齐上传,大量的数据在“行的维度”上会出现不对齐的现象。平台是数据的被动接收方,只有等待数据落盘后才能对数据进行清洗等操作,每天的集群有大量的空数据,数据清洗的工作繁琐,效率低。
数据分析师需要频繁运行算法以优化数据模型。因此,需要分析工具能够快速得到结果,分析结果的易得性会使数据分析人员在思维上连续,有利于算法的产出,反之亦然。传统架构中数据计算引擎 Spark 需要将存在 HDFS 的数据移动出来,归集的过程中非常消耗资源和时间,严重影响计算速度。
在工业场景中,Python 等语言是数据分析师必用的工具之一。传统架构中,需要采用 Spark 计算引擎中的 PandasUDF 功能来批量运行 Python 代码,这导致了大量的胶水代码,拖慢了算法开发的周期。
以 MatrixDB 为主体的大数据平台架构如下图所示,分为如下4层:
贴源层:有两类数据源,一是通过MatrixGate获取kafka提供的实时工况数据;一是以外部表的形式集成CRM、ERP等关系数据;也可包含其他视频帧/图片/文本等所需数据。
整合层:将工况数据做列的筛选,去空,合并,统一物理量,统一设备ID,与CRM数据/事实表保持一致,实现数据的清洗转换和治理。
算法结果层:基于整合层工况数据跑各类算法,对于T+1算法输出天级结果表,对于T+0算法输出实时结果表。
应用层:基于算法结果,结合CRM等各类维度数据输出各类维度指标;以及基于工况数据输出机器学习模型。
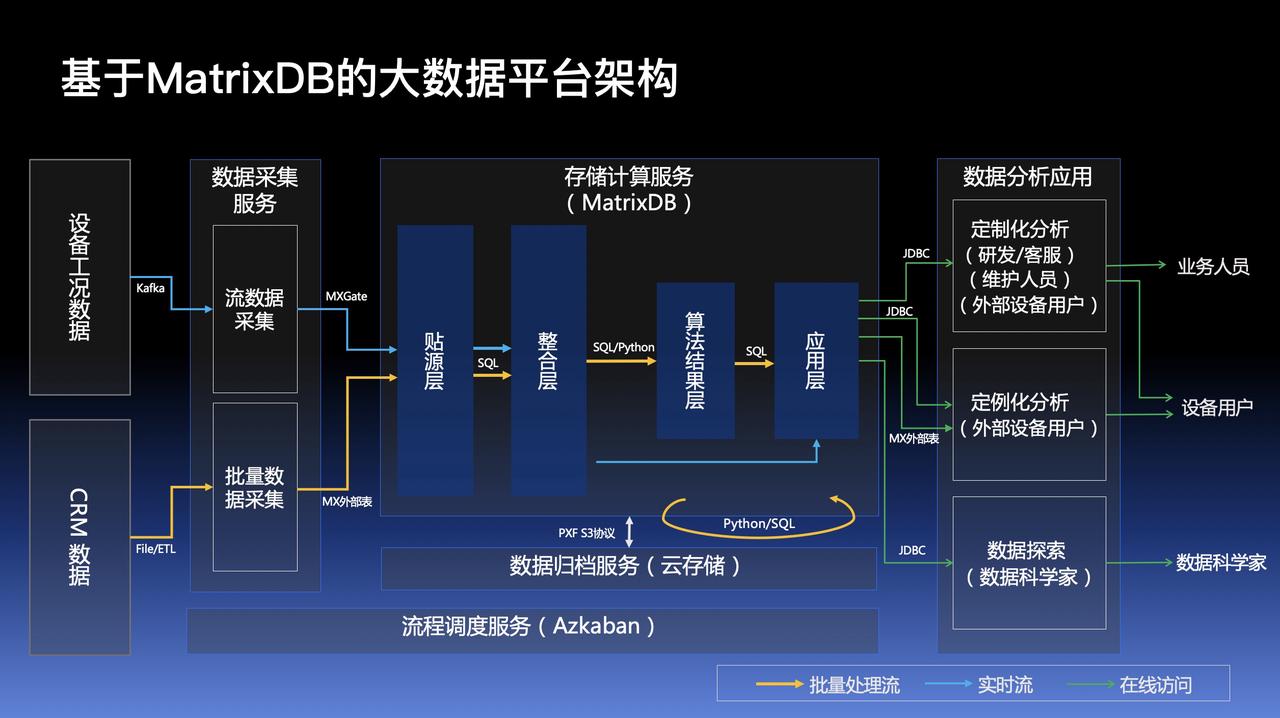
MatrixDB 相比于 Hadoop+Spark 传统大数据架构有如下明显优势:
MatrixDB 将不同的场景需求融合到数据库中,满足了各种类型数据的存储、实时计算、离线计算以及数据展示的功能,避免了 Hadoop 全家桶式的尴尬。同时,MatrixDB 的界面化安装与 Grafana 监控使运维工作难度大大地降低。
MatrixDB 通过 MatrixGate 实现了业内最快的时序数据写入能力,单机峰值达到5000万点/秒;此外支持高并发点查询和明细查询,点查询可以达到20万tps。
实时数据入库采用 MatrixDB 的实时数据写入工具 MatrixGate,支持 UPSERT 功能,可以将同一时刻的不同行数据进行合并更新。这对设备上传的时序数据是十分友好的。此外还可以将部分清洗数据的工作前置到入库前,简化了数据清洗的过程。
MatrixDB 是一款支持OLAP与OLTP的时序数据库,数据本身就存储在 MatrixDB 中,计算时无需移动数据。借助其独创的 MARS 表功能,将查询延迟进一步缩短,使算法更容易获取到计算所需的原始数据。在每台物理机配置相同的情况下,MatrixDB 仅使用了一半的机器数量,将典型算法运行时间从2.5小时减少到可1小时。整体的执行效率提升约为五倍。
MatrixDB 支持使用 Python3 实现自定义函数(UDF),在数据库内部实现机器学习模型的训练和推理,计算贴近数据,性能提升10倍以上。此外 Python UDF 的代码直接存储在数据库内,使得 Python 代码的迁移、调用与管理更加方便,利于算法开发人进行数据分析和算法迭代工作。
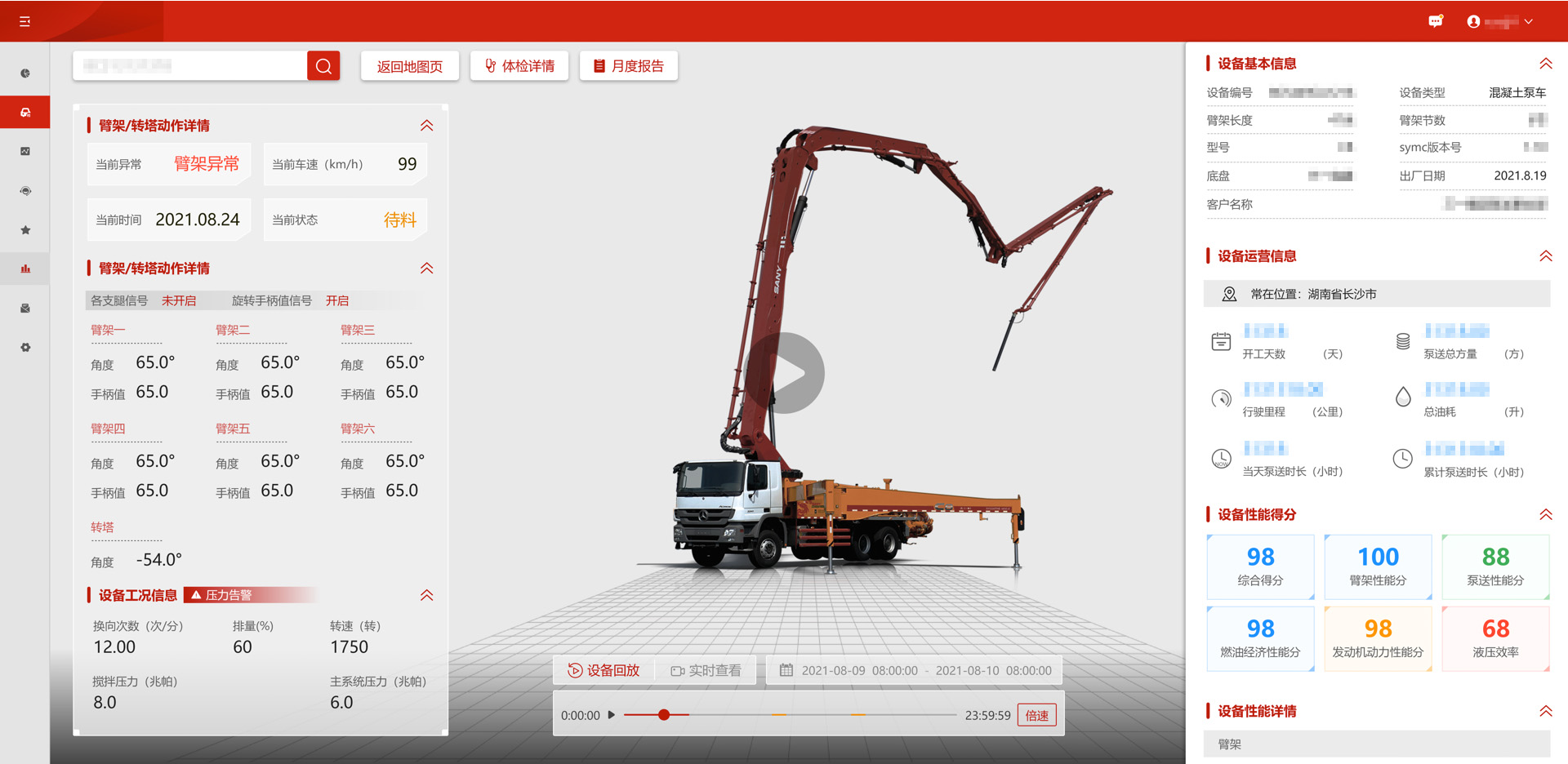
2021年 MatrixDB 帮助三一工程车辆事业部完成了其混凝土泵车的智能化运维平台的搭建。该平台是三一为其客户提供车辆智能运维服务的载体,目前已经接入了数万台混凝土泵车,约占该企业2018年以后生产泵车的90%。混凝土泵车是利用压力将混凝土沿管道连续输送的工程车辆,可以用于房屋建设、城市立交桥建设以及道路建设的混凝土运输,解决了混凝土浇筑中最后的问题。从应用与产量上看是工程车辆的重要组成部分。平台通过量化分析“抖、堵、高、转、效”五大关键性能约268项指标,提供单设备的全面体检报告和故障预警。同时,基于历史的多设备、多维度统计和对比分析,为研发产品定义、优化、跟踪提供数据决策支撑;全面支撑数据决策、新品跟踪、技改验证、精准排故四大场景。依赖于MatrixDB优异的特性,客户在平台的新版本上线后取得了显著的效果。
平台的分析功能分为两个部分,一是通过定制化的分析为产品定义、优化、跟踪提供数据决策支撑。二是通过机器学习算法为客户输出车辆健康状态结果。随着智能化程度的深入,两部分需求都呈明显的上升趋势。在旧平台上,受限于算法的执行效率,研发人员在算法开发的过程中会花费很多调试与等待时间。通过开发人员的反馈我们得知,搭载MatrixDB的新平台可以提升算法执行效率,连贯开发思路,缩短了43%的算法开发周期。
新平台的维护不再需要Hadoop、HIVE、HBase等不同技术栈的庞杂知识体系。MatrixDB 支持标准SQL,开发运维都很方便,释放了客户的时间,使客户更关注自身的专业知识。根据运维人员实际工作中的反馈,投入到大数据平台上的工作量减少了30%。
得益于 MatrixDB 支持高吞吐实时入库的特性,新平台可以提供T+0的分析功能,提高了客户的整体满意度和体验感。平台的用户不用等到第二天再查看设备的经济指标与设备健康指标。值得一提的是关乎于人员安全的臂架稳定性指标的实时计算,为操作手的安全提供了又一层保障,也让客户更放心。
在为大数据平台带来了上述优化与新功能的同时,在保证性能满足需求的前提下,新的集群规模从原本的16个节点缩减到9个节点。使得客户每年在云资源上的成本开销减少了43.75%。
很多传统制造业装备的智能化转型已经在路上。和互联网行业不同,制造业中数据获取任务由设备承担,数据类型以时序数据为主。而来自于互联网行业的大数据平台并不能在时序数据的处理上得心应手。选择更合适的工具,才能少走弯路,让行业人才摆脱数据困境,专注于业务本身,才能在智能化转型的过程中更快取得优势。






