
不少的开发者向我们的架构部小哥提出了“拷问”:
MatrixGate 号称“轻松达到5000万数据点/秒的接入速度”,为什么在自己生产的环境里速度却上不去?
MatrixGate 确实能达到如此高的接入速度,前提是要正确使用,根据实际情况做参数调整,才能实现功能性能样样精通!
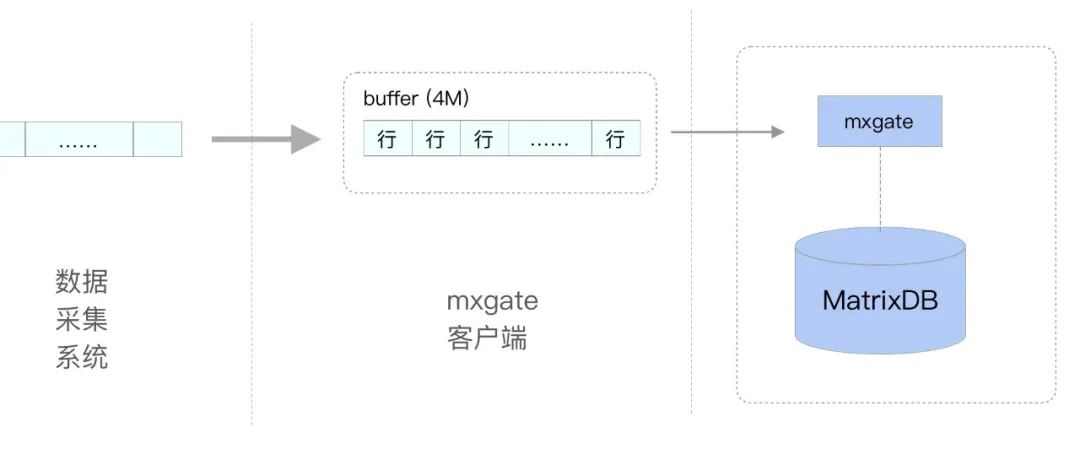
首先,需要排查客户端与 MatrixGate 的通信方式。MatrixDB 是关系模型,数据采用的是按行存储。
在使用服务模式时,向 MatrixGate 提交数据需要批量提交,而不是一次只提交一行,因为每次建立连接会有额外的网络开销。
MatrixGate 接收数据包体的大小上限默认是 4M,所以在提交数据时先本地缓存多行,组合一个接近 4M 大小的数据包再提交即可。该上限可以通过--max-body-bytes参数修改,但一般不需要修改。
另一个影响接入速度的因素是写入的目标表。
目前 MatrixGate 有3种存储引擎来做数据的直接接入,分别是:Heap、AO、AOCO(mars 因为是压缩表,只用来热转冷,不接热数据)。
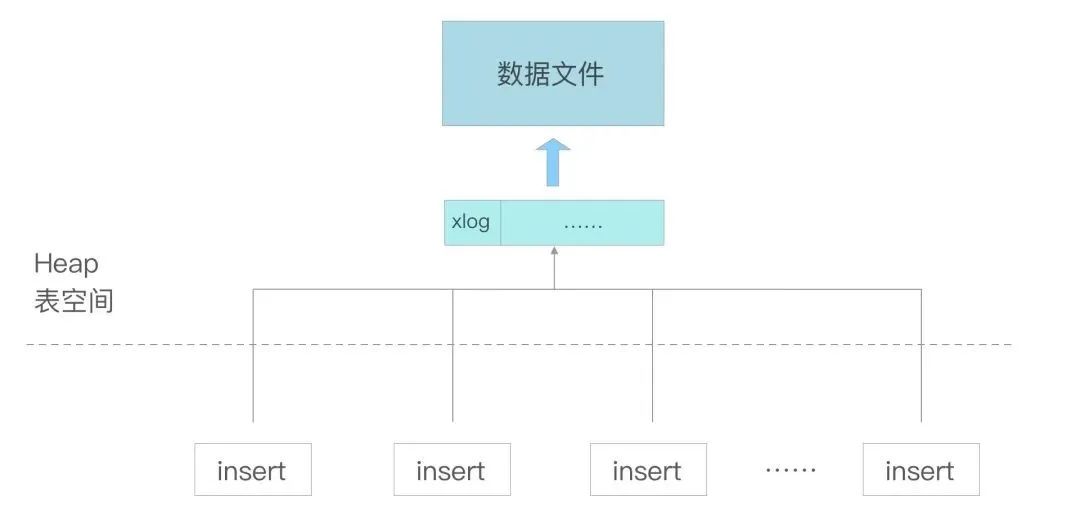
Heap 表,在写入数据时会先写入xlog,然后异步同步到表的数据文件中。xlog 文件是固定的,不会随着并发而增多。
AO(Append Optimized)表,作为 OLAP 场景优化的存储引擎,与 Heap 表不同的是,数据会直接写入到表的数据文件中,并且会为每个并发插入进程分配独立的数据文件。

AOCO (Append Optimized Column-Oriented) 表,为列存的 AO 表,与 AO 表不同的是,AOCO 表会为每个列生成单独的数据文件,并且每个列文件数量与并发插入的进程数相同。所以,*实际打开的文件数量为:{并发数量} {列数}。**

综上,可以看出不同存储引擎在插入数据时涉及的文件数量不同:
首先,写入操作不仅仅会消耗 IO 资源,打开文件也会消耗内存,文件的数量越多,消耗的内存就越大。所以,要适当控制并发数,尤其是 AOCO 表。通过减小--stream-prepared参数来降低并发数。实际并发数为:{stream-prepared} + 1,该参数默认值为10,所以默认并发数为11。
其次,时序数据会从设备源源不断生成,MatrixGate 在向 MatrixDB 提交数据时也不能一条一条提交,这样性能会大大受损,整个过程也是批量来提交的。那批量如何控制?目前使用的是通过时间阈值来控制,当时间窗口达到 100ms 则提交。
所以,客户端向 MatrixGate 提交数据并返回 HTTP 204 码后,数据已经入库并可以被其他事务查询到。100ms 是默认值,该参数可以通过参数--interval修改。
这个值决定了每次向文件写入的数据量。在写入数据时,需要经过如下3个过程:
对于 AOCO 表来说,在写入每行数据的时候,每个列都要经历如上3个过程。如果列非常多的话,每次打开、关闭的开销会放大,并且写次写入数据量太小也不利于 IO 优化。
所以,对于 AOCO 表的写入,可以适当增加--interval,达到最佳配置值。
MatrixGate 要想达到最佳性能,需要关注如下几点:
POST 方式提交数据要批量提交;
在写入 AOCO 表时要注意--interval和--stream-prepared两个参数。其中,--interval适当提高,--stream-prepared适当降低。






