Before introducing Compaction, let's understand three important concepts:
Read Amplification: The amount of data actually read is greater than the logical data needed. For example, scanning multiple SSTables in LSM-TREE.
Write Amplification: The amount of data actually written is greater than the logical data written. For example, writing a key in LSM-TREE may trigger compaction, causing far more data to be written.
Space Amplification: The actual disk space occupied is greater than the true data size. For example, SSTables storing invalid old versions.
LSM-TREE achieves high write throughput through sequential writes and background compaction. The Compaction strategy determines the core trade-off between write performance, read performance, and resource consumption.
For traditional LSM-TREE, there are two main compaction strategies: Size-Tiered Compaction and Level Compaction.
Tiering: Stack data first, merge later when there's enough. Write-optimized.
Leveling: Keep each level tidy, disallow overlaps. Read-optimized.
Tiered pays for writes, Leveling pays for reads.
Size-Tiered Compaction vs Level Compaction
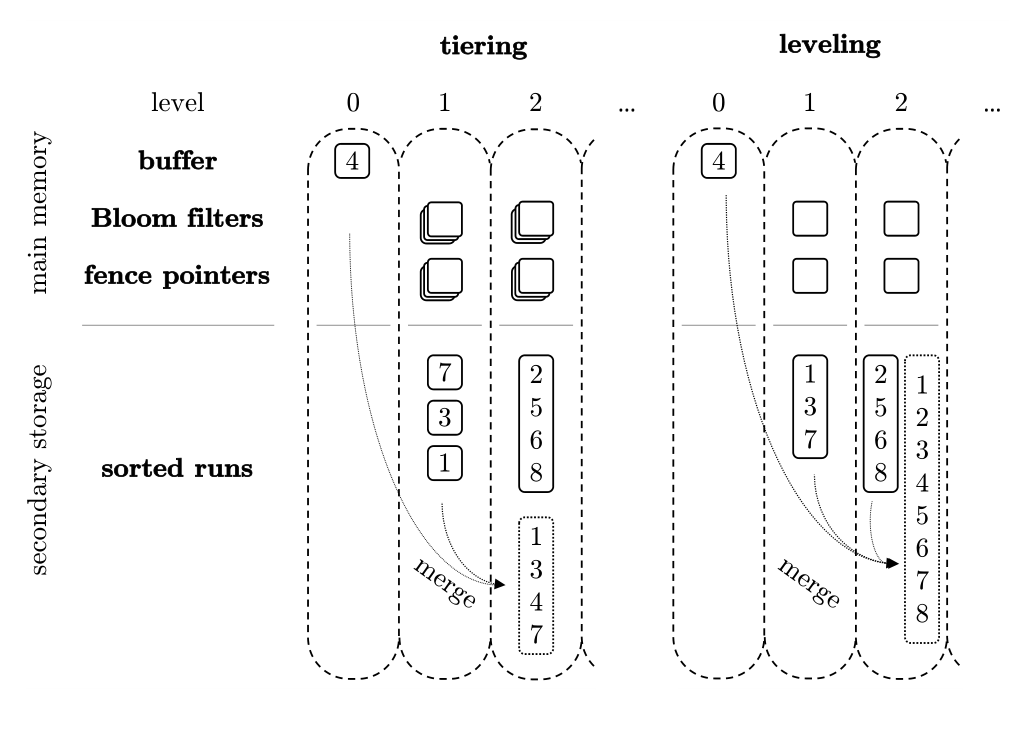
Allows SSTs in the same level to have overlapping key ranges. Primarily merges SSTs of similar size into larger SSTs, without strictly enforcing non-overlap per level.
Advantages: Low write amplification (merges are less aggressive, don't repeatedly rewrite data to eliminate overlap).
Disadvantages: High read amplification (queries may need to check more runs).
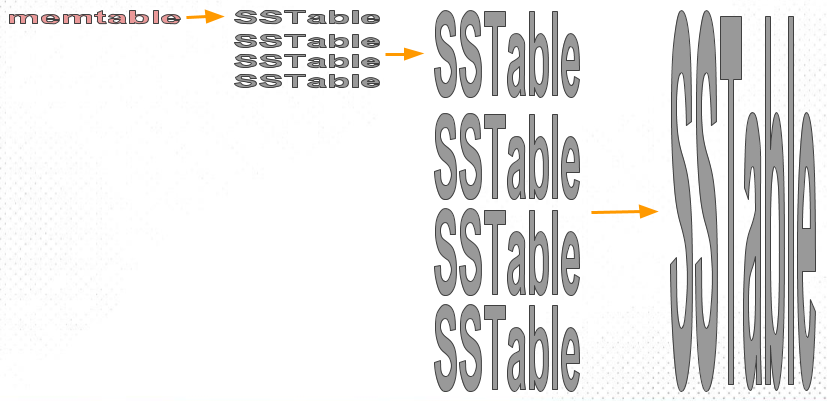
The core idea of the Size-Tiered Compaction Strategy (STCS) is to merge SST files of similar sizes into a new file. The memtable is gradually flushed to disk as SST files. Initially, these SSTs are small files. As more small files accumulate and the amount of data reaches a certain threshold, the STCS strategy compacts these small files into a medium-sized new file. Similarly, when the number of medium-sized files reaches a certain threshold, they are compacted into larger files. This process recurses, continuously generating larger and larger files.
Core Principles:
Multiple SST files with overlapping key ranges are allowed within the same level.
Files are first accumulated; merging occurs uniformly when the quantity threshold is reached.
Assume each SST can store 4 keys.
First flush: SST-A: [1 – 4]
Second flush: SST-B: [5 – 8]
Third flush, which includes updates and new data, writing 3, 6, 9, 10, generates SST-C: [3 – 10]
At this point, Level 0 structure: [1–4] [5–8] [3–10]
C overlaps with A in the range 3–4.
C overlaps with B in the range 5–8.
When querying for key=6, multiple files must be scanned simultaneously. This is read amplification. The Tiered merging approach triggers a merge when the number of files in a level reaches a threshold, outputting a larger file, ultimately resulting in [1 – 10].
Therefore, its advantage is fast writes and low write amplification, but the disadvantage is that queries need to scan multiple files, leading to read amplification.
Strives for SSTs within each level to have non-overlapping key ranges. Once overlap occurs, the upper SST and all overlapping lower-level SSTs are merged and rewritten.
Advantages: Low read amplification (checking a key/range typically involves few files).
Disadvantages: High write amplification (frequently rewriting large amounts of data).
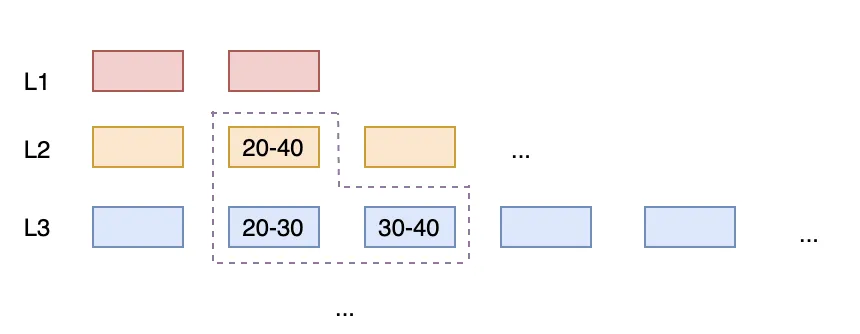
In Leveled compaction, each level consists of multiple SSTables that form an ordered run, and the SSTables maintain an ordered relationship with each other. When the data size of a level reaches its limit, it is merged with the run from the next level. This approach reduces multiple runs in a level down to one, decreasing read amplification and space amplification. The use of small SSTables enables fine-grained task decomposition and control; controlling task size essentially means controlling temporary space usage.
Core Principles:
The key ranges of SST files within each level must not overlap.
The entire system forms a continuous ordered space.
In the same scenario, when overlap is detected, merging occurs immediately: [1–4] + [5–8] + [3–10] → [1–10], which is then split again into [1–5] and [6–10] to ensure non-overlapping intervals within the same level.
Therefore, its advantage is fast queries — at most one file needs to be examined per query. However, the disadvantage is significant write amplification, with background compaction occurring continuously, leading to high I/O pressure.
| Dimension | Tiered | Leveling |
|---|---|---|
| Overlap within the same level | Allowed | Not allowed |
| Write cost | Extremely low | Medium to high |
| Query cost | High | Extremely low |
| Write amplification | Small | Large |
| I/O pressure | Light | Heavy |
| Latency stability | Poor | Good |
| Priority objective | Throughput | Responsiveness |
MARS3 adopts the Tiered compaction approach. In short, under typical time-series workloads with VIN+TS, continuous writes cause new runs to broadly overlap with the key spaces of multiple lower-level runs. This makes it difficult for Leveled Compaction to maintain non-overlap within levels, frequently triggering large-scale rewrites. Write amplification becomes significant and is further magnified in MPP multi-instance scenarios.
Assume there are now 3 devices (VIN = A, B, C), each continuously reporting the latest values.
The system already has L1 files, each covering a time segment for a VIN:
L1 already contains:
Now new data arrives:
These new writes typically first form a new run (e.g., in L0 or an upper level), which we'll call NewRun. NewRun contains the latest time slices for A/B/C, covering roughly the following key ranges:
Which L1 files will it overlap with?
This means a single NewRun simultaneously overlaps multiple files in L1 (one for each VIN).
If there are more devices, say 10,000 VINs writing concurrently, a single NewRun could overlap hundreds or thousands of L1 files (depending on how L1 is partitioned). Leveled's requirement is that files within L1 should be as non-overlapping as possible. So when NewRun is to be merged into L1, Leveled must do the following: read NewRun + all overlapping L1 files, re-merge and sort them, and write them back as new L1 files, ensuring no overlap after the write. The cost of this step is that even if the new write contains only a small amount of data (e.g., 1GB), as long as it touches the historical segments of many VINs, it will drag in a large amount of historical files to rewrite (e.g., 10GB, 50GB, 100GB), resulting in severe write amplification. Size-Tiered, however, does not require non-overlap in lower levels; it primarily merges runs of similar sizes and does not pull in a bunch of lower-level files for rewriting just to eliminate overlap. Therefore, in this scenario, the impact of write amplification is relatively smaller.
Furthermore, MARS3's Runs are columnar structures requiring sufficient physical contiguity to ensure scan throughput and compression efficiency, which conflicts with the small SST granularity commonly used in Leveled. Size-Tiered Compaction aligns better with this workload: it focuses on merging runs of similar size, significantly reducing write amplification. Additionally, under a time-progressing data stream, it naturally forms run organizations clustered by time, making time-based filtering and data skipping more effective.
To control read amplification, we have set a read amplification limit for each level. When read amplification for a level exceeds this limit, compaction to the lower level is triggered:

level_size_amplifier is used to specify the size amplification factor for each level. It is the threshold for triggering merge operations at a level, calculated as: rowstore_size * (level_size_amplifier ^ (level - 1)). The larger this value, the slower the read speed and the faster the write speed. The specific value can be determined based on scenario characteristics (write-heavy vs. read-heavy, compression ratio, etc.). Note: Ensure that the number of runs in each level does not become excessive, as this can impact query performance and even prevent new data insertion.
The essence of level_size_amplifier is to control how many times larger each level can be compared to the previous one, analogous to upper levels being buffer zones and lower levels being long-term storage areas.
Therefore, it's easy to understand: a larger amplifier allows each level to hold data longer, potentially increasing the number of runs, leading to more objects being checked during queries (read amplification), but triggering fewer compactions (faster writes). A smaller amplifier triggers compaction earlier, resulting in fewer and cleaner runs, faster reads, but more frequent compactions. rowstore_size and level_size_amplifier work together to form a controllable sinking rhythm, constraining run accumulation in the Tiered model to limit read amplification while preserving write throughput advantages. For more details, refer to Section 7.2 Observability.
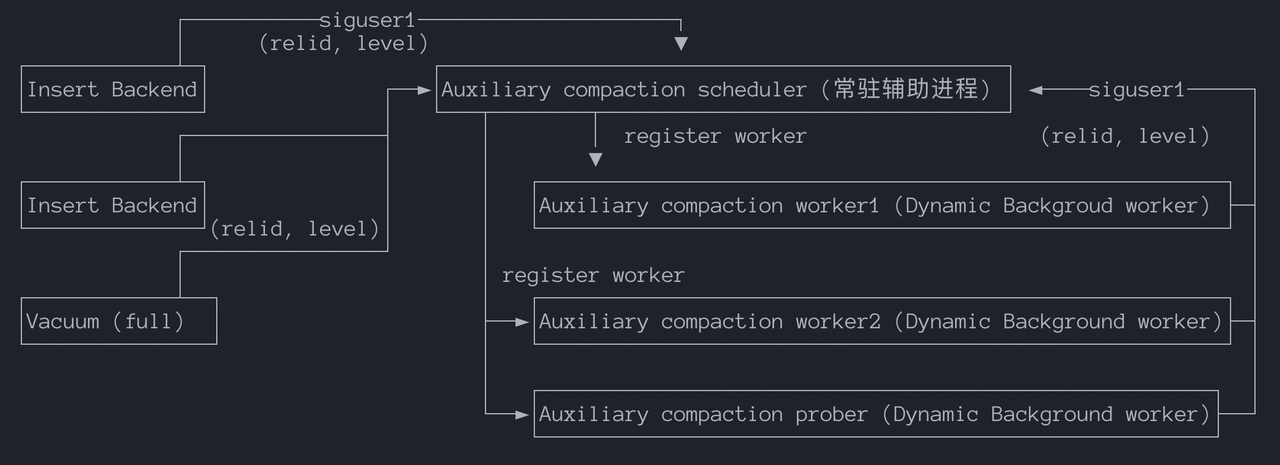
The Compaction Scheduler is primarily responsible for:
Starting and stopping compaction workers.
Managing and reusing compaction workers.
Determining the priority of compaction tasks.
Correctly responding to database shutdown requests.
Compaction Worker: Responsible for executing specific compaction requests. If it detects that the read amplification for a level exceeds the limit, it notifies the scheduler process of a new compaction request. Currently constrained by the process model, the maximum number of compaction workers is hardcoded to 16.
Compaction Prober: Responsible for actively probing for compaction tasks, such as:
The general flow is:
1. Insert Backend continuously writes to RowStore.
2. When a RowStore reaches its threshold, it switches to a new RowStore.
3. Sends SIGUSR1 to the scheduler and writes compaction request information to shared memory: (relid, level).
4. The scheduler is woken up, reads the request from shared memory:
- Queues / deduplicates / prioritizes.
- Chooses to launch a new worker or reuse an idle one.
5. The worker begins executing the compaction.For compaction, if multiple tables require compaction but there are only 16 workers, a priority system is needed to ensure that tables with the greatest need are compacted in a timely manner.
In short, compaction prioritization considers factors such as the level (lower levels have higher priority), whether it is Eager or Lazy (manual vs. automatic), the type of compaction, etc.
The principle of Autoprobe is to periodically probe the transaction age and size of all Mars3 tables, calculating a score based on age divided by size. Autoprobe can trigger compaction on historical levels. It selects the N levels with the highest scores to initiate flush/compaction tasks. The matrixts_internal.mars3_autoprobe_candidates() function can be used to view candidate levels for autoprobe and their scores.
adw=# select * from matrixts_internal.mars3_autoprobe_candidates();
segid | datname | relname | level | nruns | age | bytes | score
-------+---------+-------------+-------+-------+------------+-----------+-----------------------
0 | adw | t_w0_nosort | 1 | 13 | 616005 | 49888440 | 0.012347650076851471
0 | adw | t_w0_nosort | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w3b_3key | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w1_1key | 1 | 7 | 329693 | 23821378 | 0.013840215288972788
...Because autoprobe always selects levels with the highest score, to prevent autoprobe from being unable to process other lower-score levels due to compaction failures, a blacklist mechanism has been added. After a compaction fails 3 times for the same level, it enters the blacklist and will not be retried:
The mars3_autoprobe_blacklist() function can be used to view the blacklist.
The mars3_autoprobe_blacklist_remove(regclass, level) function can be used to remove a blacklist entry for a specific level in the current database.
The mars3_autoprobe_blacklist_clear() function can be used to clear all blacklist entries.
GUC Configuration:
GUC mars3.autoprobe_period controls the probe interval in seconds. A value greater than 0 enables it, 0 disables it. Default is off. It can be initially set to 10 minutes and adjusted based on workload.
GUC mars3.autoprobe_workers controls how many levels are selected per probe. Default is 2. Note that this consumes regular compaction worker slots, not new workers.
GUC mars3.autoprobe_retry controls the number of retries; a value of 2 means a total of 3 attempts.
GUC mars3.autoprobe_blacklist_size controls the size of the blacklist.
If autoprobe is disabled, tables without writes will not be compacted; tables with writes will still undergo merging.
ps aux | grep postgres | grep 'compact worker': This command is used to verify that all worker processes are running. Check for any worker processes that are not running but have been started for a long time without exiting, as these are signs of abnormal system operation.
Additionally, database logs contain information related to compaction activities. Create a table t1 and continuously insert data:
postgres=# create table t1(id int,info text)
using mars3 with(mars3options='prefer_load_mode=single,rowstore_size=64');
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE Open a new window and use matrixts_internal.mars3_level_stats to continuously observe the status of each level.
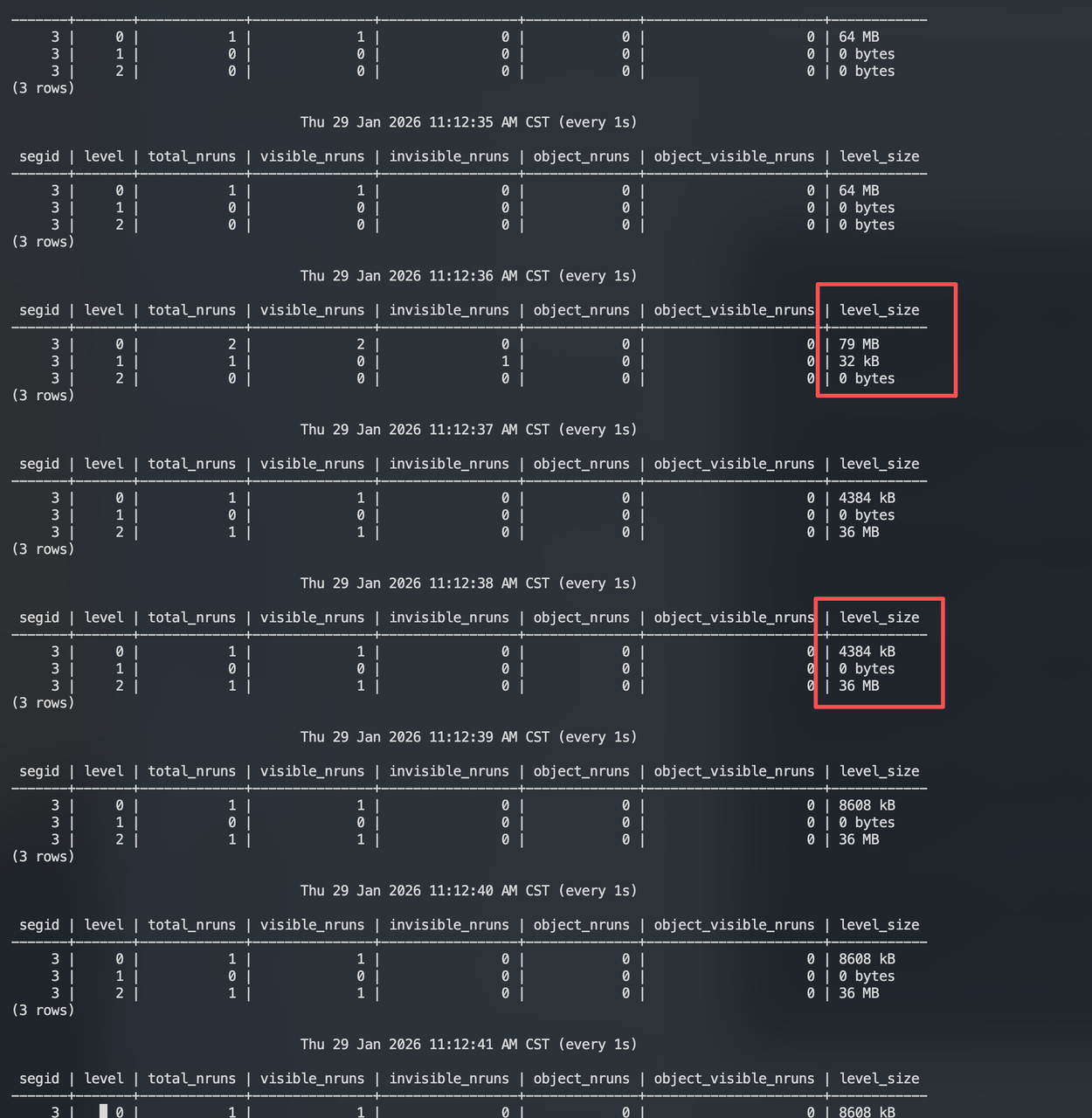
It can be observed that after L0 fills up to 64MB (rowstore_size), L1 briefly appears with 32 KB, and then data is written directly to L2. Subsequent writes also go directly to L2. Why is this? Why isn't data first written to L1?
In MARS3, there is logic for adjusting levels – GetDesiredLevel.
It calculates which level a Run should belong to (desired_level) based on its total size.
If the Run is not currently in that level (cur_level), it acquires a lock and moves the Run from its current level to the target level.
Based on the code flow above:
run_size ≈ rowstore_size = 64MB
total_amp = run_size / rowstoresize = 64MB / 64MB = 1.0
desired_level = log(1.0) / log(8) = 0 / log(8) = 0
Therefore, the theoretical relative level number for this Run is 0, as its size exactly matches the rowstore_size tier.
if (desired_level < 0)
{
ret = desired_level < -0.5 ? 1 : 2;
}
else
{
ret = Min(2 + round(desired_level), MAXLEVELS - 1);
}Since we calculated desired_level = 0, it takes the else branch:
round(0) = 0
ret = 2 + 0 = 2 (then applies Min protection with the upper bound)
So the final result: GetDesiredLevel() returns 2, meaning this 64MB Run should be placed in L2 according to the new version rules.
In MARS3's tiered model, stable geometric growth is not achieved by strictly satisfying total size limits per level instantly, but by compaction gradually making the target size tiers of Runs approach growth by the amp factor. The core thresholds for triggering compaction are:
Old version (< REL_V1): threshold(level) = rowstoresize × amp^level
New version (>= REL_V1): threshold(level) = rowstoresize × amp^(level-1)
Bytes_threshold is used to budget the input set size for triggering a compaction / pick. Compaction will pick N runs, and the total_size of these N runs is roughly bytes_threshold.
Based on this calculation method:
Additionally, with the Min(MAX_RUN_SIZE, ...) limit, if the calculated value exceeds MAX_RUN_SIZE, it is capped to MAX_RUN_SIZE (to prevent jobs or output Runs from becoming too large).
rowstore_size is based on RowStore granularity.
Levels L1+ are compressed columnar states, where byte counts can vary greatly. Without adjusting the base point, applying the same formula rigidly to each level could easily cause issues: L1 becomes smaller due to compression → distortion in trigger rhythm → loss of control over read amplification/accumulation.
The new version uses level-1 in the formula and +2 in Run classification to align the model baseline to a more stable level. From an engineering perspective: don't use the most volatile layer as the ruler.
Exponential growth: Deeper layers should process larger amounts of data per compaction; otherwise, deep-layer data would be disturbed too frequently (write amplification, I/O jitter).
MAX_RUN_SIZE: Prevents a single compaction task or output Run from becoming too large and dragging down the system; it can be adjusted at the table level.
The faster the thresholds grow → fewer compactions → smoother writes.
But runs are more likely to accumulate → greater risk of read amplification.
So, a larger amp results in slower reads and faster writes.
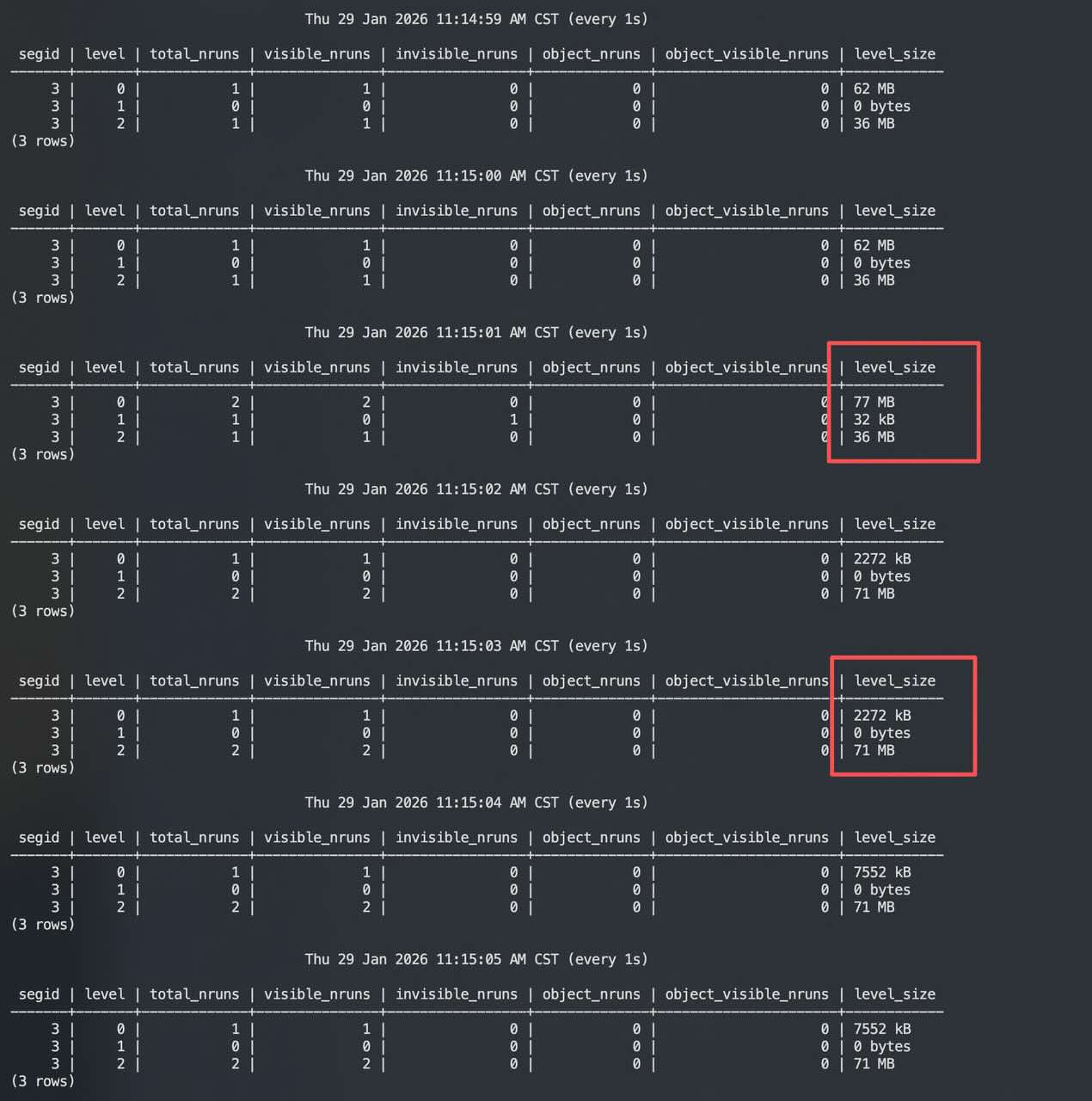
Using the t1 table from above as an example, observe when L2 triggers a Pick. According to the calculation model just described, L2 triggers compaction at approximately 512 MB:
Thu 29 Jan 2026 02:42:07 PM CST (every 1s)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 64 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 15 | 15 | 0 | 0 | 0 | 533 MB
3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 bytes
(4 rows)
Thu 29 Jan 2026 02:42:08 PM CST (every 1s)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 2 | 2 | 0 | 0 | 0 | 69 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 15 | 15 | 0 | 0 | 0 | 533 MB
3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 bytes
(4 rows)
Thu 29 Jan 2026 02:42:09 PM CST (every 1s)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 16 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 16 | 16 | 0 | 0 | 0 | 577 MB
3 | 3 | 1 | 0 | 1 | 0 | 0 | 32 kB
(4 rows)
Thu 29 Jan 2026 02:42:10 PM CST (every 1s)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 16 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 16 | 16 | 0 | 0 | 0 | 626 MB
3 | 3 | 1 | 0 | 1 | 0 | 0 | 32 kB
(4 rows)
...
...
Thu 29 Jan 2026 02:42:26 PM CST (every 1s)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 32 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 16 | 16 | 0 | 0 | 0 | 626 MB
3 | 3 | 1 | 0 | 1 | 0 | 0 | 467 MB
(4 rows)
...
...
Thu 29 Jan 2026 02:43:58 PM CST (every 1s)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 32 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 1 | 1 | 0 | 0 | 0 | 36 MB
3 | 3 | 1 | 1 | 0 | 0 | 0 | 531 MB
(4 rows)
Thu 29 Jan 2026 02:43:59 PM CST (every 1s)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 32 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 1 | 1 | 0 | 0 | 0 | 36 MB
3 | 3 | 1 | 1 | 0 | 0 | 0 | 531 MB
(4 rows) Combining the logs and observations:
14:42:07 ~ 14:42:08
L0 RowStore is at a run switch point.
L2 has accumulated 15 columnar runs, totaling 533 MB.
L0: 1 run, 64MB
L2: 15 runs, 533MB
L1: 0
L3: 014:42:09 ~ 14:42:10
L0 goes from 69MB back to 16MB: indicates a flush/switch just occurred, a new run starts accumulating.
L2 runs go from 15→16: a newly flushed columnar run is placed into L2.
L3 shows an invisible and very small (32KB) run: suspected to be a common placeholder/metadata/temporary artifact during compaction.
L0: back to 16MB (a new run begins accumulating)
L2: 16 runs, 577 → 626MB (one more run added)
L3: 1 run, invisible=1, 32KB14:42:26
Compaction of L2 is still in progress.
The output run for L3 has been written with a large volume but is still invisible, indicating the output run hasn't been committed yet, or metadata updates are pending.
L2: 16 runs, 626MB
L3: invisible 32KB → 467MB (still invisible)14:43:58 ~ 14:43:59 (Finalization)
L2: 1 run, 36MB
L3: 1 run, 531MB (visible)
L0: 32MB (a new RowStore run is accumulating)This indicates the compaction has completed and committed:
Most of the 16 runs in L2 were merged and consumed, leaving only a small run (36MB), typically a run generated during compaction that wasn't selected for this merge, or leftover due to thresholds/boundaries.
L3 ends up with only 1 visible large run (531MB), the output of this L2→L3 compaction.
L0 continues writing, operating stably.

It is worth noting that L0's bytes_threshold is 0; it's flushed, which is not meaningful.
RunLife-Flushed is used for code debugging to track the lifecycle of a Run, including:
RunLife-Created: A RUN is created.
RunLife-Flushed: A RUN is read and flushed.
RunLife-Recycled: A RUN is recycled and reused.

rowstore_size: Controls the granularity of run output from L0 (= write-side rhythm)
Small → runs produced quickly → more prone to read amplification/compaction pressure
Large → fewer runs → more stable writes, but heavier single flush, potentially greater memory/jitter
level_size_amplifier (default 8): Controls level threshold growth by 8^(level-1) (= read/write trade-off)
Large → fewer compactions (faster writes) but run accumulation (slower reads, jitter)
Small → more compactions (slower writes) but cleaner levels (faster reads, stable)
prefer_load_mode: Controls the write method
Writes: Extremely high concurrency, continuous appends
Queries: Latest values; time-range filtering + aggregation (by device/tag, time window)
Success Criteria: No write backlog; stable latest value and window queries; controllable space amplification, high compression ratio
Example time-series scenario:
-- Here we only consider properties when creating a MARS3 table
WITH(
mars3options='prefer_load_mode=single,rowstore_size=64',
compresstype=zstd,
compresslevel=3, -- For MARS3, zstd is a good compression algorithm choice; level 3 achieves good compression without significantly reducing write performance
compress_threshold=10000, -- For time-series downsampling scenarios, threshold 10000 is a good sweet spot, balancing query performance and compression ratio; the maximum actual adjustment value is 65535
uniquemode=true)
Writes: Micro-batches (every few seconds/tens of seconds), possibly upsert or append+merge
Queries: Wide table aggregations, joins, report scans (sensitive to stable throughput)
Success Criteria: Stable batch processing latency; stable query throughput; avoid compaction contention causing batch latency spikes
Mixed Read-Write: Point queries/hot queries + occasional analytical scans
Success Criteria: Stable low-latency point queries; no hot-spot jitter; analytical tasks do not degrade online read-write performance
Symptoms:
Point queries/small range queries significantly slower, P95/P99 jitter
Level status shows increased total_nruns in a certain level (commonly L2/L3), level_size also growing
Possible Causes:
Run accumulation in the same level, delayed compaction triggering
Compactor anomalies (e.g., tablespace bugs in previous versions, poor I/O, blocked by TRUNCATE in older versions)
Parameter thresholds too high (level_size_amplifier too large or rowstore_size too small causing runs to be generated too quickly)
Excessive invisible_nruns, leading to read amplification
Solutions:
Manually trigger vacuum + vacuum full
Adjust parameters:
For read priority: appropriately reduce level_size_amplifier
Reduce run generation speed: appropriately increase rowstore_size to make L0 switching less frequent
Symptoms:
Log shows large number of "worker launched" / "worker exit"
But level state improvement is not significant
Possible Causes:
Verification Method:
Compare the number of "compact:" and "compact done" during the same time period
Report the issue and collect packcore for R&D
ERROR: there are too many segments, 6400 at most. please use VACUUM FULL.
A customer encountered this error when writing a table (same structure, same data) during a mode switch from BULK to Single. The cause was that writing was too fast in Single mode, causing the compactor to be unable to keep up, generating too many runs. The solution was to increase rowstore_size, but note that increasing rowstore_size consumes more memory, requiring trade-offs.
Symptom: Using the \dt+ command shows the table size is too large
Possible Causes:
Too many runs in RowStore, still in row format
Excessive invisible runs
Solution:
Manually execute VACUUM + VACUUM FULL to flush to ColumnStore. This may need to be performed multiple rounds, as VACUUM FULL involves MERGE operations which can also generate invisible runs, until no further merges are possible.
adw=# create table testmars3(id int,info text) using mars3 distributed by (id) order by(id);
CREATE TABLE
adw=# \d+ testmars3
Table "public.testmars3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
info | text | | | | extended | |
Distributed by: (id)
Access method: mars3
Order by: (id)
adw=# select * from matrixts_internal.mars3_sortkeys('testmars3');
sks
------
(id)
(1 row)Starting from version 6.5.0, MARS3 officially supports incremental backup with table-level capabilities consistent with AO tables. The backup system can determine whether a table has undergone data modifications or structural changes since the last backup, thus backing up only the content that has actually changed, significantly reducing backup size and time consumption.
YMatrix has introduced precise recording of data modification changes, similar to the modcount attribute for AO tables. Users can flexibly control whether to enable this feature via the parameter mars3.update_modcount, allowing the system to automatically increment the modification counter each time a table is written to, updated, or deleted. Additionally, MARS3 supports retrieving the last attribute modification time of a table from the pg_stat_last_operation view to identify structural changes.
The latest supported version of MARS3 supports recording data modification changes, similar to the modcount attribute for AO tables, controlled by the mars3.update_modcount parameter (enable/disable). It also supports retrieving the last table attribute modification time from the pg_stat_last_operation table. Based on these two features, MARS3 tables achieve the same incremental analyzedb capability as AO tables.
MARS3 targets the most common yet hardest-to-balance scenarios in enterprises: continuous data writes, concurrent queries, needing to handle real-time data while supporting analytical decisions, and requiring both detailed lookups and large-scale aggregations.
In such scenarios, the biggest headache for customers is usually not single-point performance bottlenecks, but system fragmentation: to satisfy both real-time writes and analytical queries simultaneously, multiple storage and compute pipelines must be maintained, leading to higher architectural complexity, operational costs, and performance uncertainty. MARS3's core value lies in integrating these previously competing capabilities into a unified storage system, forming a deliverable, verifiable, and sustainable system capability.
On the write side, MARS3 can handle high-frequency, small-batch, real-time data and systematically organizes it into columnar formats better suited for analysis in the background. This means customers don't have to choose between real-time write capability and analytical performance: new data can enter the system quickly, while settled data maintains efficient scanning and aggregation. Simultaneously, MARS3 adopts a background management strategy better suited for hybrid workloads, effectively controlling write amplification and resource contention, preventing the system from becoming increasingly "hard to write, hard to query, hard to maintain" as data grows, business peaks occur, and multi-instance concurrency increases.
On the query side, MARS3's value lies not just in reading data faster, but more importantly in reading less invalid data. Through data locality driven by sort keys, block-level statistics, and index access path optimization, the system can narrow the actual scan range early in the query process, moving the "skip if not matching" decision as far forward as possible. For customers, the direct benefits are: the same hardware resources can support more analytical tasks, queries are more stable under the same data scale, and overall resource investment is more controllable. This benefit does not rely on manual, repeated tuning but is a systematic capability formed by storage organization, data skipping, and index optimization.
More importantly, MARS3 is not just a "lab capability" that shines only under ideal loads; it fills the correctness and operational boundaries truly needed in production environments. In update and delete scenarios, it ensures semantics are not lost during background relocation and merging. In concurrent update scenarios, it upgrades the behavior from "abort on conflict" to a correct behavior of "waitable, traceable via chain, re-checkable." In governance and operations, it provides observable level/run statistics, degradation pattern identification, and parameterized management methods, evolving the system from "able to run" to "able to run stably long-term." This means customers receive not just a storage engine with better performance, but a foundational capability that is easier to implement, easier to operate, and better suited for long-term core business support.
Ultimately, MARS3's value in AP-core mixed workloads can be summarized in three points:
Unified Capability: Uses a single storage system to simultaneously handle real-time writes, analytical scans, and detailed lookups, reducing the complexity introduced by multi-system assembly.
Stable Capability: Maintains predictable performance and behavior under the coexistence of continuous writes, continuous queries, and background management, rather than being "fast only under ideal scenarios."
Deployable Capability: Not only pursues performance metrics but also emphasizes correctness, observability, and operational closure, enabling the system to truly meet the conditions for long-term production operation.
This is MARS3's core value: it does not simply enhance a single capability, but helps customers in the most common and complex hybrid workload scenarios achieve truly sustainable business support with less system fragmentation, lower overall costs, and higher long-term stability.
BRIN index support for multi-minmax
MARS3 support for GIN indexes
Further improvements in observability. Currently, information about picks, compactions, etc., is recorded in logs that need to be accessed on the corresponding QE nodes, and some of this information is oriented toward kernel developers and not user-friendly for operations.
Although PostgreSQL's numeric type (hereinafter referred to as pg numeric) offers much higher precision than its counterparts in other databases, its implementation is more complex and its performance is relatively poor. pg numeric is difficult to vectorize, resulting in not only a lack of performance improvement in the vectorized executor but actually lower performance than in the non-vectorized executor due to compatibility mechanisms. Compared to vectorized types such as int/float, pg numeric's performance is approximately 1-2 orders of magnitude slower. To improve the performance of the numeric type, a limited-precision numeric type (hereinafter referred to as mxnumeric) has been implemented, supporting up to 38 digits of precision, and is provided through the mxnumeric extension.
Because both mars3 and mxnumeric are extensions, there is no guarantee that mars3 will be installed before mxnumeric. Therefore, by default, the mxnumeric type does not support the mars3_btree and mars3_brin index types.
If you need to use mars3_btree and mars3_brin index types, you can use mxnumeric.set_config('mars3', true) to manually create operator classes, enabling the mxnumeric type to use mars3_btree and mars3_brin indexes. However, you must ensure that the matrixts extension has already been created; otherwise, an error will be reported:
ERROR: data type numeric has no default operator class for access method "mars3_btree" HINT: You must specify an operator class or define a default operator class for the data type.
You can also use mxnumeric.set_config('mars3', false) to delete the operator classes and restore the default state.
Run: An ordered set of data based on the sort key in MARS3. It is the basic unit for storage and background management (compaction, column conversion, reclamation).
Level: A structure organizing Runs hierarchically. Lower levels favor writes and fast persistence; higher levels favor read optimization and data regularity.
Delta: Incremental change information (new versions, markers, differences) appended to support updates and deletions. It requires background management for gradual convergence and reclamation.
MVCC: Multi-Version Concurrency Control. A mechanism that uses version visibility to determine which data is visible to the current transaction, supporting concurrent read-write consistency.
Row-First, Column-Later: A lifecycle strategy where data first enters the system in a form more suitable for writes and fresh access, then is gradually transformed in the background into a columnar form more suitable for scans and compression.
RowStore: A physical layout where data is organized by row. Suitable for point queries, detailed lookups, and small-range reads, but analytical scans may incur significant invalid I/O.
ColumnStore: A physical layout where data is organized by column. Suitable for large-range scans and aggregations, offering high compression efficiency, but is more sensitive to high-frequency, small-batch writes (maintenance/write amplification is more pronounced).
Sort Key (ORDER BY): Determines the ordering of data within Runs. A key design factor affecting data skipping effectiveness, scan efficiency, and management costs.
Locality: The principle where data with similar key values is physically stored as close together as possible, allowing range queries to access data more contiguously and reduce scan range.
Data Skipping: Utilizing block-level metadata (e.g., min/max, BRIN) to skip data blocks that cannot possibly contain matching data during reads, achieving "less reading."
Block Metadata: Statistical information used for data skipping and filtering, such as minimum/maximum values for a block, row count, visibility information, etc.
BRIN: An index/metadata mechanism based on range summaries, providing range pruning capability at low cost. Commonly used for range filtering on large tables.
default_brin: A set of BRIN/data skipping metadata strategies that MARS3 enables/maintains by default for typical workloads, used to reduce scan range and cost.
Selectivity: The estimated proportion of data expected to remain after predicate filtering. In BRIN scenarios, it often corresponds to the proportion of ranges/pages hit.
Read Amplification: The multiple by which the actual amount of data read or number of objects accessed exceeds the logical requirement (e.g., needing to search across multiple Runs/versions).
Write Amplification: The multiple effect caused by one logical write resulting in more physical writes (e.g., due to metadata maintenance, merge rewrites, column conversion, etc.).
Compaction: A background process that reorganizes/merges multiple Runs into a more regular data form to reduce read amplification, reclaim invalid versions, and improve data skipping and compression effectiveness.
Compaction Debt: A measure of the outstanding background compaction work (governance gap). Accumulated debt typically leads to longer read paths or write jitter.
Flush / Dump: The process of writing in-memory incremental data to disk sequentially, forming a persistent Run.
Row-to-Column / Columnization: The process of converting data from a more write-friendly form into a columnar layout to enhance scan throughput and compression efficiency.
GC / Vacuum-like Reclaim: The process of cleaning up no-longer-visible versions/markers and reclaiming space, typically performed in coordination with compaction/reorganization.
Unique Mode: A mode where inserting with the same unique key (defined by the sort key) acts as an update. Writing the same key generates a new version, suitable for latest-state/snapshot data models.
shared_buffers: PostgreSQL's traditional buffer pool. Its involvement in a particular read path depends on the storage engine's implementation and access method.
varbuffer (mx_varbuffer_size_mb): A dedicated cache provided by MARS3 for specific access paths (commonly index-related access), used to reduce repeated reads and tail latency.
adw=# select name,setting from pg_settings where name like '%mars3%';
name | setting
----------------------------------------+-------------------
mars3.allow_alter_rewrite | off
mars3.append_sync | off
mars3.archive_dontvacuum | off
mars3.autoprobe_period | 0
mars3.autoprobe_retry | 2
mars3.autoprobe_workers | 2
mars3.debug_block_skip | off
mars3.debug_btree_bloomfilter | off
mars3.debug_btree_build_summary | off
mars3.debug_btree_minmax | off
mars3.debug_clean_ignore_successor | off
mars3.debug_columnstripereader | off
mars3.debug_indexrollback | off
mars3.debug_logicdecode | off
mars3.debug_thread_insert | off
mars3.debug_uniquemode_sortkey | on
mars3.debug_update_chain | off
mars3.debug_use_deltachain | off
mars3.default_btree_options |
mars3.default_storage_options | compresstype=none
mars3.disable_physical_tlist | on
mars3.enable_autofreeze | off
mars3.enable_block_sample | off
mars3.enable_block_skip | on
mars3.enable_btree_bloomfilter | on
mars3.enable_btree_minmax | on
mars3.enable_inorderscan | on
mars3.enable_post_customscan_vectorize | on
mars3.force_allocate | off
mars3.freeze_in_compact | on
mars3.inplace_freeze_columnstore | off
mars3.mars3_autoprobe_blacklist_size | 1000
mars3.max_insert_threads | 2
mars3.punish_inorderscan | 1.15
mars3.test_print_index_info | off
mars3.trace_run_life | on
mars3.update_modcount | off
mars3.verify_rangefile | on
mars3_auto_analyze_projection | on
mars3_brin_buildsleep | 0
mars3_orderkey_contain_partkey | on
optimizer_enable_mars3_indexscan | on
(42 rows)Note:
GUCs starting with debug/test are for debugging and should not be used in production.
Strikethrough indicates parameters that have been deprecated.
| Parameter Name | Current Setting | Description |
|---|---|---|
| mars3.allow_alter_rewrite | off | Allows table rewrites triggered by ALTER operations. When modifying table storage options that would result in a table rewrite, this parameter needs to be explicitly enabled to confirm the operation. |
| mars3.append_sync | off | Forces append synchronization. Controls the synchronization behavior of mars3 when appending data. |
| mars3.archive_dontvacuum | off | Does not perform VACUUM operations after archiving, facilitating debugging and analysis. |
| mars3.autoprobe_period | 0 | Interval (in seconds) for automatic compaction task probing. A setting of 0 disables the automatic probing feature. |
| mars3.autoprobe_retry | 2 | Number of retries for failed tasks. A setting of 0 disables retries. |
| mars3.autoprobe_workers | 2 | Number of worker threads executing automatic probe tasks (range: 1-16). |
| mars3.debug_block_skip | off | Outputs debugging information for block skip optimization logic. |
| mars3.debug_btree_bloomfilter | off | Outputs debugging information for B-tree bloom filters. |
| mars3.debug_btree_build_summary | off | Outputs debugging information for B-tree build summaries. |
| mars3.debug_btree_minmax | off | Outputs debugging information for B-tree min/max boundary checks. |
| mars3.debug_clean_ignore_successor | off | Debugs logic for ignoring successor nodes during cleanup operations. |
| mars3.debug_columnstripereader | off | Debugs the read behavior of ColumnStripeReader. |
| mars3.debug_indexrollback | off | Displays debugging information for index rollback, used to analyze index rollback related issues. |
| mars3.debug_logicdecode | off | Debugs logical decoding functionality. |
| mars3.debug_thread_insert | off | Debugs multi-threaded insertion functionality. |
| mars3.debug_uniquemode_sortkey | on | Debugs sort key scans in unique mode. |
| mars3.debug_update_chain | off | Debugs update-chain logic, used to analyze update-chain related issues. |
| mars3.debug_use_deltachain | off | Debugs the logic for using delta chains in delete operations. |
| mars3.default_btree_options | (empty) | Sets default options for mars3 B-tree indexes (e.g., compresstype, compresslevel, fillfactor, minmax, compressctid, etc.). |
| mars3.default_storage_options | compresstype=none | Sets default options for mars3 storage (e.g., compresstype, compresslevel, mars3options, encodechain, uniquemode, etc.). |
| mars3.disable_physical_tlist | on | Disables physical tlist (target list) optimization for mars3. |
| mars3.enable_autofreeze | off | Whether autovacuum for mars3 automatically performs autofreeze operations. |
| mars3.enable_block_sample | off | mars3 uses block sampling for analytical statistics. |
| mars3.enable_block_skip | on | mars3 enables block skip optimization based on BRIN information. By default, BRIN can skip irrelevant blocks during SeqScan; this parameter can disable that optimization. |
| mars3.enable_btree_bloomfilter | on | Enables B-tree bloom filter checks. |
| mars3.enable_btree_minmax | on | Enables B-tree min/max boundary checks. |
| mars3.enable_inorderscan | on | mars3 provides sequential scan paths with sort keys. |
| mars3.enable_post_customscan_vectorize | on | Deprecated. Was originally added to support vectorization for bitmap scans generated by ORCA. |
| mars3.force_allocate | off | Forces allocation of segment and run slots. Must normally be false; only used in emergency situations when runs or segments reach their upper limit and cannot write data, enabling reserved slots for data merging. |
| mars3.freeze_in_compact | on | Performs freeze operations during the compaction process. |
| mars3.inplace_freeze_columnstore | off | Enables inplace freeze functionality for columnstore. |
| mars3.mars3_autoprobe_blacklist_size | 1000 | Maximum capacity of the automatic probe blacklist, i.e., the maximum number of tasks that can be skipped. |
| mars3.max_insert_threads | 2 | Maximum number of threads available for a single insert operation (range: 0-6). 0 disables multi-threading. Default is 2. |
| mars3.punish_inorderscan | 1.15 | Adds a penalty factor to the cost of mars3 inorderscan (range: 1.0-10.0), affecting the optimizer's probability of choosing sequential scans. |
| mars3.test_print_index_info | off | Used only for testing; prints additional index information. |
| mars3.trace_run_life | on | Prints lifecycle information for internal mars3 runs, used for problem analysis. Default is true. |
| mars3.update_modcount | off | Enables updating of modcount (modification count). |
| mars3.verify_rangefile | on | Performs data verification when columnstore outputs rangefiles. Default is true. |
| mars3_auto_analyze_projection | on | When performing automatic analysis, only analyzes order by columns to reduce analysis overhead. |
| mars3_brin_buildsleep | 0 | Sleep time (in milliseconds) before index construction. Range: 0-600. Used for testing and debugging. |
| mars3_orderkey_contain_partkey | on | Partitioned mars3 tables must include the partition key (partkey) in the order key. |
| optimizer_enable_mars3_indexscan | on | ORCA optimizer enables mars3 index scans. |
CREATE EXTENSION matrixts;
CREATE TABLE t(
time timestamp with time zone,
tag_id int,
i4 int4,
i8 int8
)
USING MARS3
WITH (compresstype=zstd, compresslevel=3,compress_threshold=1200,
mars3options='rowstore_size=64,prefer_load_mode=normal,level_size_amplifier=8')
DISTRIBUTED BY (tag_id)
ORDER BY (time, tag_id);Partitioned Table
CREATE EXTENSION matrixts;
CREATE TABLE t(
time timestamp with time zone,
tag_id int,
i4 int4,
i8 int8
)
USING MARS3
WITH (compresstype=zstd, compresslevel=3,compress_threshold=1200,
mars3options='rowstore_size=64,prefer_load_mode=normal,level_size_amplifier=8')
DISTRIBUTED BY (tag_id)
PARTITION BY RANGE (time)
(
START ('2026-02-01 00:00:00+08')
END ('2026-03-01 00:00:00+08')
EVERY (INTERVAL '1 day')
)
ORDER BY (time, tag_id);The three general compression algorithms lz4, zstd, and zlib need to be specified in the WITH clause during table creation. Example:
=# WITH (compresstype=zstd, compresslevel=3, compress_threshold=1200)| Parameter Name | Default Value | Minimum Value | Maximum Value | Description |
|---|---|---|---|---|
| compress_threshold | 1200 | 1 | 8000 | Compression threshold. Controls how many tuples in a single table are compressed at once. It is the upper limit on the number of tuples compressed within the same unit. |
| compresstype | none | - | - | Compression algorithm. Supports zstd, zlib, and lz4. |
| compresslevel | 0 | 1 | - | Compression level. Smaller values compress faster but yield worse compression ratios; larger values compress slower but achieve better compression ratios. The valid value ranges vary by algorithm: 1. zstd: 1-19 2. zlib: 1-9 3. lz4: 1-20 |
When compresstype is specified with a default value but compresslevel is not specified, compresslevel defaults to 1. When compresslevel > 0 but compresstype is not specified with a default value, compresstype defaults to zlib.
The following parameters are used to adjust the size of Runs in L0 and can also indirectly control the size of Runs above L1.
| Parameter | Unit | Default Value | Value Range | Description |
|---|---|---|---|---|
| rowstore_size | MB | 64 | 8 – 1024 | Controls when an L0 Run switches. When the data size exceeds this value, it will switch to the next Run. |
The following parameters are used to specify the data loading mode in MARS3.
| Parameter | Default Value | Value Range | Description |
|---|---|---|---|
| prefer_load_mode | normal | normal / bulk | Data loading mode. normal indicates standard mode, where newly written data is first written to RowStore Runs in L0. After accumulating to rowstore_size, it is written to ColumnStore Runs in L1. Compared to bulk mode, this incurs one extra I/O operation, and columnar conversion becomes asynchronous instead of synchronous. It is suitable for high-frequency, small-batch write scenarios with sufficient I/O capacity and low latency requirements. bulk indicates batch loading mode, suitable for low-frequency, large-batch write scenarios. Data is written directly to ColumnStore Runs in L1. Compared to normal mode, it saves one I/O operation, and columnar conversion becomes synchronous instead of asynchronous. It is suitable for low-frequency, large-batch data writes with limited I/O capacity and low latency sensitivity. |
The following parameter is used to specify the amplification factor for Level sizes.
| Parameter | Default Value | Value Range | Description |
|---|---|---|---|
| level_size_amplifier | 8 | 1 – 1000 | Level size amplification factor. The threshold for triggering merge operations at a Level is calculated as: rowstore_size * (level_size_amplifier ^ level). The larger this value, the slower the read speed and the faster the write speed. The specific value can be determined based on scenario characteristics (write-heavy vs. read-heavy, compression ratio, etc.). Note: Ensure that the number of runs in each Level does not become excessive, as this can impact query performance and even prevent new data insertion. |
MARS3 supports terminating compaction tasks that are blocked while holding locks during DROP/TRUNCATE TABLE.
pg_rewind supports incremental repair for MARS3 tables.
MARS3 supports DEFAULT BRIN.
Supports concurrent ALTER TABLE SPLIT PARTITION, with concurrent reads and writes during the split (temporarily does not support AOCO tables, stream tables, or cases where the parent table has triggers).
MARS3 supports threaded insertion (currently only effective when prefer_load_mode = normal/bulk and the data volume exceeds rowstore_size). Not all inserts trigger threaded insertion; it is only triggered when a single insert exceeds rowstore_size. Additionally, threaded insertion may lead to increased memory usage.
MARS3 relaxes the order restrictions when creating btree indexes in unique mode.
MARS3 supports DELETE operations in unique mode scenarios.
MARS3 supports btree inorder scan.
MARS3 supports incremental analyzedb and incremental mxbackup.
MARS3 adds two new GUCs, mars3.default_storage_options and mars3.default_btree_options, for specifying default MARS3 storage parameters.
Adds ORCA support for MARS3 indexes.
Enhances MARS3's analyze logic, adopting row-based sampling.
Adds support for DROP INDEX on partitioned tables for MARS3 (#ICGEOH).
MARS3 supports ROI indexes.
MARS3 supports automatic conversion of btree/brin indexes to mars3_btree/mars3_brin indexes.
MARS3 partitioned tables support DROP INDEX.
How YMatrix Domino Replaces Lambda, Kappa, Flink, and Spark with One Engine🚀
YMatrix HTAP Transforms Month-End Closing for a 16,000-Store Pharma Chain
How YMatrix Powers SVOLT’s Smart Factory Transformation
Dahshenlin: Achieving Real-Time Finance-Operations Integration with a Modernized Data Foundation
SERES × YMatrix: 3-Hour Migration of 2.13TB, 50% Faster Multi-Scenario Queries