В процессе развития PostgreSQL исполнитель (executor) всегда оставался одним из ключевых компонентов, напрямую влияющим на производительность запросов. Поскольку в базы данных всё чаще переносятся задачи аналитики, тема повышения эффективности исполнителя становится постоянным предметом внимания сообщества PostgreSQL.
В прошлом году в своём выступлении на конференции PGConf India 2025 («Hacking Postgres Executor For Performance») Амит Ланготе (Amit Langote) детально рассмотрел подходы и практические методы оптимизации исполнителя PostgreSQL. В этом докладе он рассказал о недостатках стандартного исполнителя PostgreSQL и о том, как можно улучшить модель выполнения для повышения производительности базы данных под аналитическими нагрузками.
Расширяемость PostgreSQL всегда была одним из его главных преимуществ. Раньше мы часто говорили о расширении типов данных, методов доступа к индексам, FDW, плагинах, хуках и других возможностях. Недавно автор данной статьи представил на PGConf тему, связанную с YMatrix mxvector — «Как реализовать высокопроизводительный подключаемый векторизованный исполнитель». В этом докладе я хотел подчеркнуть, что расширяемость PostgreSQL позволяет не только добавлять новые функции, но и эволюционировать саму модель выполнения. mxvector — это практическая реализация данного подхода, создающая аналитический путь выполнения, более подходящий для сценариев OLAP/HTAP, без полной перезаписи стандартного исполнителя PostgreSQL.
Исполнитель PostgreSQL использует классическую модель tuple-at-a-time (построчная обработка), которую можно представить как модель «родительский узел постоянно запрашивает у дочернего следующую строку». Каждый узел работает как итератор: родитель вызывает метод next() у дочернего узла и получает строки одну за другой. Эта модель отлично проявляет себя в OLTP-сценариях, эффективно обрабатывая точечные запросы, транзакции и подобные нагрузки. В процессе выполнения база данных последовательно обрабатывает каждую запись, выполняя соответствующие вычисления, фильтрацию, проекцию и т. д. Однако при переходе к OLAP или HTAP нагрузкам построчная обработка становится недостаточно эффективной. Особенно в запросах, работающих с большими объёмами данных, обработка каждой отдельной записи порождает значительные потери производительности.
При обработке аналитических запросов стандартный исполнитель PostgreSQL выполняет множество операций: извлечение данных, вызовы функций, преобразования типов и т. д. Хотя затраты на каждую отдельную запись могут казаться небольшими, при росте объёма данных их накопленный эффект становится огромным, что резко снижает эффективность запросов.
Рассмотрим простой пример: фильтр c1 < 10. Стандартный исполнитель проходит через следующие шаги:
Оператор сканирования загружает одну строку из хранилища; данные хранятся в сериализованном формате heap tuple.
Извлекается значение c1, преобразуется в тип datum, помещается в таблицу параметров контекста вызова функции, и вызывается указатель на C-функцию int4lt() для выполнения сравнения.
Результат сравнения (тип bool) преобразуется обратно в обобщённый тип datum и возвращается.
Оператор сканирования преобразует возвращённое значение из формата datum в bool и определяет, удовлетворяет ли запись условию фильтра.
Псевдокод выглядит примерно так:

Даже для простой операции сравнения, которая могла бы быть выполнена одной инструкцией CPU, вокруг неё происходит множество дополнительных действий. По сравнению с самой инструкцией сравнения эти «обвязочные» операции могут составлять бóльшую часть затрат, превышая истинную работу в несколько или даже десятки раз. Когда такой процесс повторяется миллионы или десятки миллионов раз, пропускная способность аналитических запросов резко падает.
Почему же векторизованный исполнитель может кардинально повысить производительность? Рассмотрим наглядный пример: представим, что нам нужно отобрать все яблоки весом более 200 граммов.
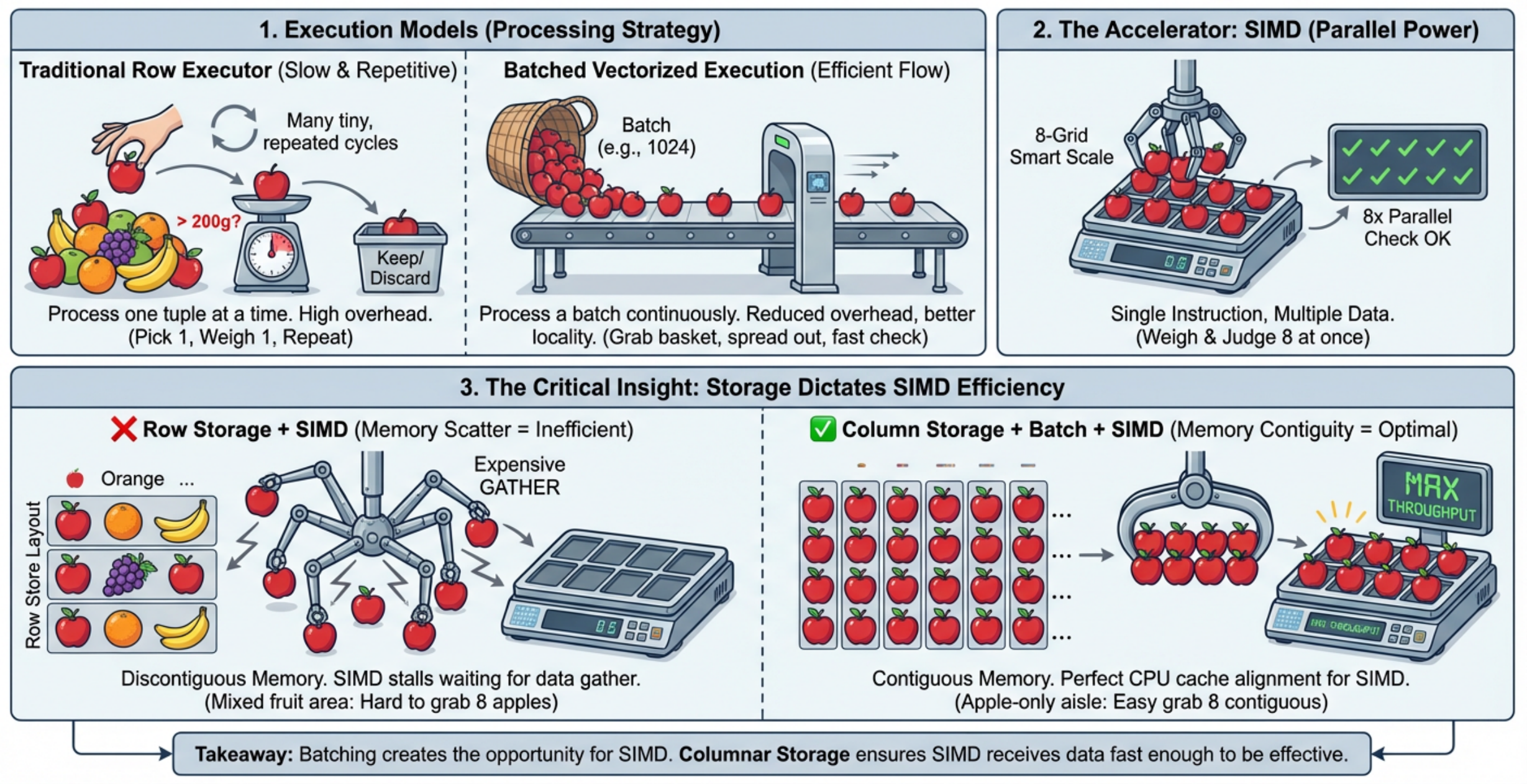
В традиционной модели выполнения это выглядит так: каждый раз берём одно яблоко, взвешиваем, проверяем, больше ли 200 граммов, затем откладываем и берём следующее. Цикл повторяется, пока не переберём все яблоки. Этот подход работает, но проблема очевидна: на каждое яблоко тратится полный цикл «взять, взвесить, проверить, отложить». Если яблок всего несколько — нормально, но когда их миллионы, эти повторяющиеся действия превращаются в огромные накладные расходы.
Значит, первое очевидное улучшение: не обрабатывать по одному, а брать партию.
Предположим, у нас есть корзина, в которую помещается сразу 100 яблок. Процесс меняется: вместо того чтобы для каждого яблока запускать полный цикл, мы обрабатываем всю партию непрерывно. Преимущество прямое: постоянные затраты на «взять/отложить» для каждого яблока распределяются на всю партию. В терминах баз данных это называется пакетной обработкой. Её суть не просто в том, чтобы брать больше данных, а в том, чтобы изменить гранулярность обработки с одной записи за раз на пакет записей, сократив количество повторяющихся вызовов функций, переключений состояний и преобразований данных.
Но на этом можно не останавливаться. Раз яблоки идут партиями, почему бы не взвешивать несколько яблок одновременно? Это подводит ко второму улучшению — SIMD.
Представим, что у нас есть особые весы, способные взвешивать 8 яблок за один раз. Тогда нам не нужно 8 раз взвешивать каждое яблоко по отдельности — одно взвешивание сразу даёт 8 результатов. Именно в этом суть SIMD: одна инструкция, несколько элементов данных. В базе данных, если мы получили пакет однотипных данных (например, массив int32), у CPU появляется возможность обработать несколько элементов за одну SIMD-инструкцию вместо скалярных вычислений по одному.
Однако для этого пакетная обработка и SIMD не происходят сами собой — нужны достаточно упорядоченные и однородные данные.
Вот здесь вступает третий ключевой фактор — физическое расположение данных (storage layout).
На левой нижней иллюстрации видно, что если фрукты свалены в беспорядке (яблоки, апельсины, бананы, яблоки, апельсины… виноград), то даже имея весы для 8 яблок, трудно их применить — сначала нужно из кучи выбрать яблоки. Это аналогично строчному хранению в базе данных: строка содержит несколько столбцов, и если запросу нужен только один столбец, всё равно приходится извлекать его из целой строки, что порождает дополнительные накладные расходы на доступ и декодирование.
Напротив, если все яблоки аккуратно сложены вместе, мы можем легко взять партию и направить её на «умные весы». В мире баз данных это соответствует колоночному хранению. При колоночном хранении данные одного столбца расположены непрерывно, что даёт несколько преимуществ:
запрос читает только нужные столбцы, сокращая ненужный I/O;
непрерывное хранение однотипных данных даёт лучшую сжимаемость;
последовательные данные лучше используют кэш CPU;
данные естественным образом представляются в виде массива, что удобно для пакетной обработки и SIMD.
Итак, колоночное хранение, пакетная обработка и SIMD — это не три изолированные концепции, а один усиливающий друг друга конвейер: колоночное хранение делает данные непрерывными, пакетная обработка — выполнение регулярным, а SIMD позволяет CPU обрабатывать много значений за раз. Другими словами, пакетная обработка создаёт возможность для использования SIMD, а колоночное хранение помогает SIMD раскрыть свой потенциал.
Резюмируем: основная идея векторизованного исполнителя — перевести единицу обработки данных с «построчной» на «пакетную» и сделать доступ к данным и вычисления более непрерывными, регулярными и дружественными к CPU. Ключевые составляющие:
Колоночное хранение — данные хранятся по столбцам, а не по строкам. Запрос читает только нужные столбцы, уменьшая загрузку ненужных данных, улучшая сжатие и работу с кэшем.
Пакетная обработка — за один раз обрабатывается пакет данных, а не одна запись. Сокращаются накладные расходы на повторные вызовы функций, переключения состояний и преобразования.
SIMD-ускорение — когда данные непрерывны, однотипны и упакованы в пакеты, CPU при помощи SIMD-инструкций может обработать несколько элементов за одну команду, увеличивая вычислительную пропускную способность.
Эти изменения уменьшают накладные расходы на каждую отдельную запись и адаптируют путь доступа к данным и вычисления к особенностям современных процессоров, повышая общую эффективность аналитических запросов.
Поняв ценность векторизованного выполнения, переходим к вопросу реализации. Существует три основных подхода.
Прямая модификация стандартного исполнителя — выглядит как естественный путь, но очень рискован. Стандартный исполнитель PostgreSQL — это зрелая, сложная и универсальная система. Прямое изменение для поддержки векторизации — высокоинвазивно, повлияет на OLTP-поведение, сложно гарантировать, что все SQL-сценарии не пострадают. Традиционный исполнитель критически важен для OLTP, и не хотелось бы разрушать его преимущества ради аналитической производительности.
Создание нового исполнителя внутри ядра — теоретически можно реализовать второй исполнитель непосредственно в коде PostgreSQL. Но это порождает другую проблему: архитектурная сложность, сложные границы с существующим исполнителем, плюс планировщик, исполнитель, выражения, хранилище — всё придётся поддерживать в двух вариантах, что ведёт к высоким затратам на сопровождение. Для системы, где стабильность и расширяемость так важны, этот путь тоже не идеален.
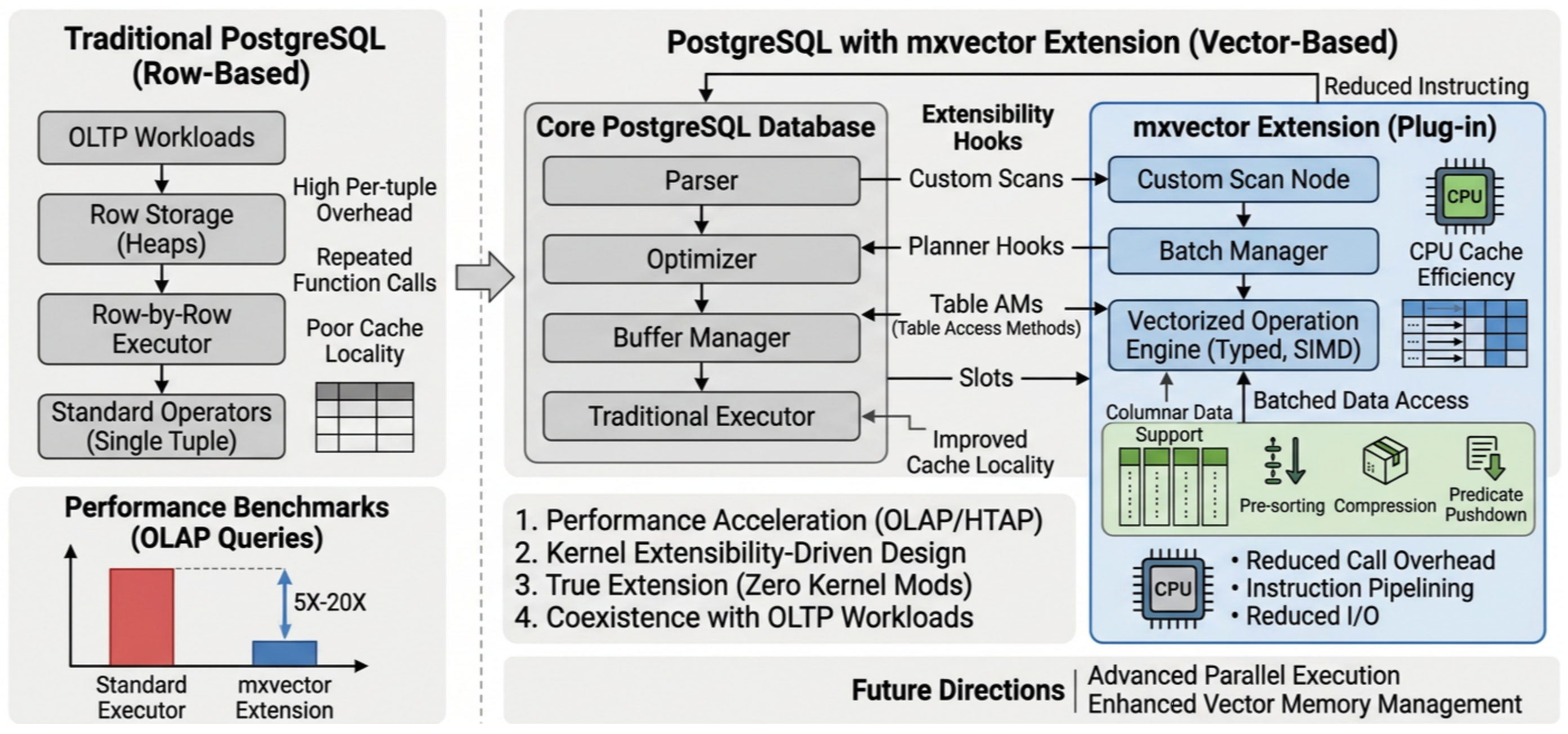
Создание подключаемого векторизованного исполнителя — именно этот путь выбрал mxvector. Преимущества: низкая инвазивность, активация по требованию, лёгкое сосуществование с традиционным исполнителем, удобство итераций и сопровождения, сохранение OLTP-сильных сторон PostgreSQL. Для PostgreSQL плагинность — это не просто элегантное инженерное решение, но и практически реализуемая архитектурная стратегия.
Короче говоря, мы не хотим, чтобы PostgreSQL стал лучше в аналитике ценой разрушения того, в чём он традиционно силён — OLTP.
Подключаемая архитектура: mxvector загружается как плагин (extension) и может сосуществовать со штатным исполнителем PostgreSQL. Это позволяет включать векторизованное выполнение для аналитических нагрузок, но для OLTP-сценариев использовать традиционный исполнитель.
Использование расширяемости PostgreSQL: mxvector реализован с использованием механизмов расширения PostgreSQL (хуки, CustomScan, AM adapter и т. д.) без изменения кода ядра PostgreSQL.
Совместимость с традиционным исполнителем: когда векторизованное выполнение невозможно, mxvector автоматически переключается на стандартный скалярный исполнитель, гарантируя корректное выполнение запроса.
Реализация mxvector опирается на несколько ключевых технологий.
План выполнения PostgreSQL состоит из узлов-операторов (executor node), таких как SeqScan, Sort, Agg, и т. д. mxvector требует собственных векторизованных версий: VScan, VSort, VHashJoin и других. Как же легально внедрить эти узлы в план PostgreSQL? Ответ — CustomScan. CustomScan предоставляет механизм создания пользовательских узлов выполнения, позволяющий расширениям подключать свои узлы к дереву плана и фреймворку исполнителя.
VPlanner отвечает за преобразование на уровне плана. Например, PostgreSQL может сгенерировать:
Limit
-> Sort
-> Seq Scanmxvector добавляет соответствующий векторизованный узел над каждым скалярным узлом, формируя структуру вроде:
VLimit
-> Limit
-> VSort
-> Sort
-> VScan
-> Seq ScanИсходные скалярные узлы называются shadow nodes(«теневые узлы»). Они никогда не выполняются, но сохраняют семантическую информацию и детали выполнения исходного плана. Например:
VLimit получает значения OFFSET/LIMIT из теневого узла Limit.
VSort — ключи сортировки из теневого узла Sort.
VScan — параметры сканирования из теневого узла SeqScan.
Этот подход критически важен, поскольку избавляет mxvector от необходимости заново реализовывать всю логику разбора семантики плана.
VNode — это векторизованная версия скалярного узла, создаваемая на основе API CustomScan и способная присутствовать в дереве плана PostgreSQL. Примеры:
VScan — векторизованное сканирование.
VSort — векторизованная сортировка.
VHashJoin — векторизованное хеш-соединение.
VLimit — векторизованный LIMIT.
Непосредственным дочерним узлом VNode является теневой узел (shadow), но он не выполняется. VNode извлекает семантическую информацию из теневого узла, а пакетные колоночные данные читает из своего векторизованного дочернего узла. Так достигаются две цели:
сохраняется семантика исходного плана PostgreSQL;
выполнение идёт по векторизованному пути mxvector (пакетно, колоночно, с SIMD).
В исполнителе PostgreSQL узлы обычно обмениваются данными через TupleTableSlot. Традиционный слот лучше подходит для передачи одной строки (tuple). mxvector же требует передачи:
колоночных данных,
пакетов записей,
данных без копирования (zero-copy).
Поэтому был реализован VSlot. VSlot наследует TupleTableSlot, но может передавать колоночные данные пакетами, а при необходимости автоматически преобразовывать их обратно в строки. Это позволяет ему обслуживать как векторизованный исполнитель, так и быть совместимым с традиционным. Короче, VSlot — это не просто мост совместимости, а высокопроизводительный канал передачи данных внутри mxvector.
Значительная часть логики SQL заключена в выражениях:
фильтры,
проекции,
арифметические выражения,
преобразования типов,
вызовы функций,
параметры агрегации.
mxvector преобразует эти скалярные выражения в векторизованные. Если для какого-либо выражения уже существует нативная векторизованная реализация — используется высокопроизводительный путь. Если нативной реализации пока нет — применяется резервный механизм (fallback expression), который эмулирует пакетную обработку через скалярные выражения. Благодаря этому mxvector может:
ускорять в первую очередь выражения с наибольшим выигрышем;
обеспечивать корректность для сложных или пока не поддержанных выражений;
не блокировать выполнение всего запроса из-за отсутствия поддержки конкретного выражения.
AM adapter служит мостом между существующими методами доступа к таблицам/индексам (table/index access method) и векторизованным исполнителем.
Традиционные AM часто больше ориентированы на строчное хранение, тогда как mxvector ожидает пакетные колоночные данные. Поэтому адаптер преобразует интерфейс доступа к данным, предоставляя те данные, которые нужны векторизованному исполнителю.
Одновременно с этим, колоночное хранилище YMatrix предоставляет более подходящую основу для векторизованного выполнения:
основано на API Table Access Method,
кодирование на уровне типов данных,
блочная микро-фильтрация на уровне метаданных (block-level micro-meta filtering),
упорядоченное сканирование (ordered scan),
агрегированное сканирование (aggregated scan),
автоматическая сортировка (automatic sorting).
Это означает, что слой хранения не просто хранит данные, а подготавливает их для векторизованных вычислений вышележащего уровня.
Традиционный исполнитель PostgreSQL отлично показывает себя в OLTP-сценариях, но сталкивается с существенными узкими местами при переходе к OLAP и HTAP. Векторизованный исполнитель за счёт пакетной обработки, колоночного хранения, SIMD и других методов предоставляет PostgreSQL новый эффективный путь выполнения.
С помощью векторизованного исполнителя mxvector, сохранив OLTP-производительность PostgreSQL, мы успешно внедрили подключаемый высокопроизводительный путь для аналитических нагрузок. Это решение использует мощные механизмы расширения PostgreSQL, позволяя улучшить аналитическую производительность без вмешательства в ключевые функции ядра.
В будущем мы планируем продолжить повышать производительность выполнения в PostgreSQL за счёт дальнейшей оптимизации управления памятью и параллельного выполнения, особенно в сценариях анализа больших объёмов данных и обработки данных в реальном времени, продвигая PostgreSQL к ещё более разнообразному и эффективному развитию.
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть II)
Эпоха ИИ: параллельные запросы — от «быстрого сканирования» к «быстрому вычислению»
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть III)
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть I)