
过去十几年,各类数据库技术都有长足发展,很多产品都在自身原有优势基础之上不同程度的探索能力延伸的边界。
但是,因为缺乏一致性,企业数据管理相关的技术架构复杂程度已到达历史最高。现运行中的数据库和大数据产品过于复杂,反复叠加后造成运维成本较高,难以被更多产业用户采纳,尤其是处于数字化初期阶段、技术积累和技术人才密度有限的企业。
与此同时,由于智能硬件渗透率提升、业务复杂度和数字化程度提升等客观变化,所有产业都在数据库产品的性能和功能上有了更高阶、更多元的需求,比如对时序类、知识图谱类数据的管理,对复杂数据分析的需求等。
在这种大趋势之下,超融合数据库出现,将交易型数据库(OLTP)、分析型数据库(OLAP)和大数据/数据湖能力融为一体,采众家之长集于一身,并通过集成更加完备的功能,形成一种新的技术形态。
新一代技术栈将为推动“技术平民化”,加速企业数字化提供重要基础。
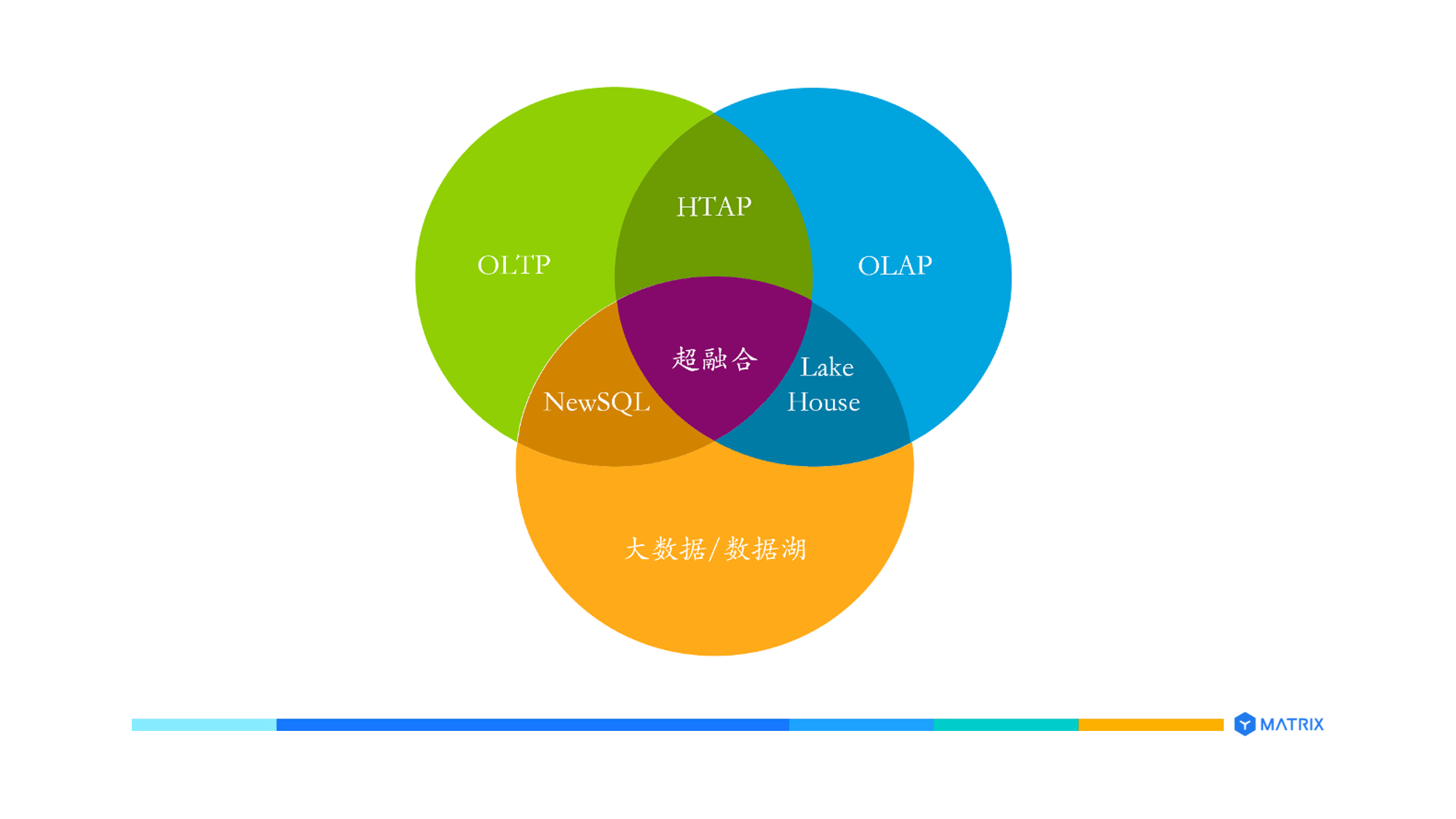
数据平台的目标是支撑业务、提高开发运维效率,提升企业的竞争力。最直接的使用者是业务开发人员,开发人员开发出通用的业务系统(譬如 CRM、ERP、BI、报表和可视化系统),或者专用的业务系统(譬如某电商的推荐系统、某银行的客户画像系统),供业务人员或用户使用。
目前,各个行业的业务复杂度、敏捷度都在不断提升,所以对业务人员提出更高要求的同时,间接也对企业的数据管理能力提出了更高要求。
伴随企业经营发展,数据规模和数据类型逐步增加后,带来的数据管理需求、实时入库和查询分析的需求增长旺盛,传统主流数据库的功能和性能已经满足不了这些需求。
在接下来的几年里,物联网将以前所未有的速度发展,大量智能化终端被投入使用后,尤其是机器之间的交互,将导致数据量呈指数级增长,对数据管理提出新的标准和要求。根据艾瑞咨询测算,中国物联网连接量将从 2019 年的 55亿个增长至 2023 年的 148 亿个,年复合增长率达到 28.1%。IDC 预测,2025 年中国每年产生的数据量将增长48.6ZB。
然而,面对这个变化,**传统数据库产品却普遍缺乏基于机器学习的高性能实时复杂分析能力(in-database machine learning),也无法实时预测并支持业务决策,更别提为企业提供增长所需要的基本数字化、智能化能力了。
不恰当的、或过时的数据管理策略,会间接影响终端用户的体验,甚至造成用户流失、企业增长或商业决策缺乏数字化基础等问题。企业急需找到在性能、功能上满足 5-10 年需求,同时不对运维成本大幅增长的新一代数据产品。
现在数据中心部署的数据产品大体可分为四大类:
交易型数据库(OLTP):支撑在线交易业务,典型查询涉及数据行比较少,数据频繁增删改查,数据库追求高并发、低延迟。典型的产品有Oracle、DB2、SQL Server、PostgreSQL、MySQL 等。
分析型数据库(Olap):支撑在线分析业务,典型查询涉及大量数据行,数据以插入和查询为主,数据清洗后一般不更新或者偶尔更新,数据库追求复杂查询的性能。典型的产品有 Teradata、Greenplum、Snowflake 等。这类产品也称为数据仓库。
专用数据库:支撑某种特定数据处理业务场景,典型产品有时序数据库、图数据库、Gis 数据库、文本检索产品等。
大数据/数据湖(Data Lake):大数据从 2005 年左右发展起来,起初主要产品是 Hadoop,后来发展成为包含众多产品的技术栈。近几年有人提出“数据湖(Schema On Read)”来描述一种技术和数据处理理念,即数据先写入数据湖,然后通过数据治理使之成为可分析的数据。典型的产品有 Hdfs、Hive、Impala、Tez、Kudu、Presto、Drill、Flink、Spark等。
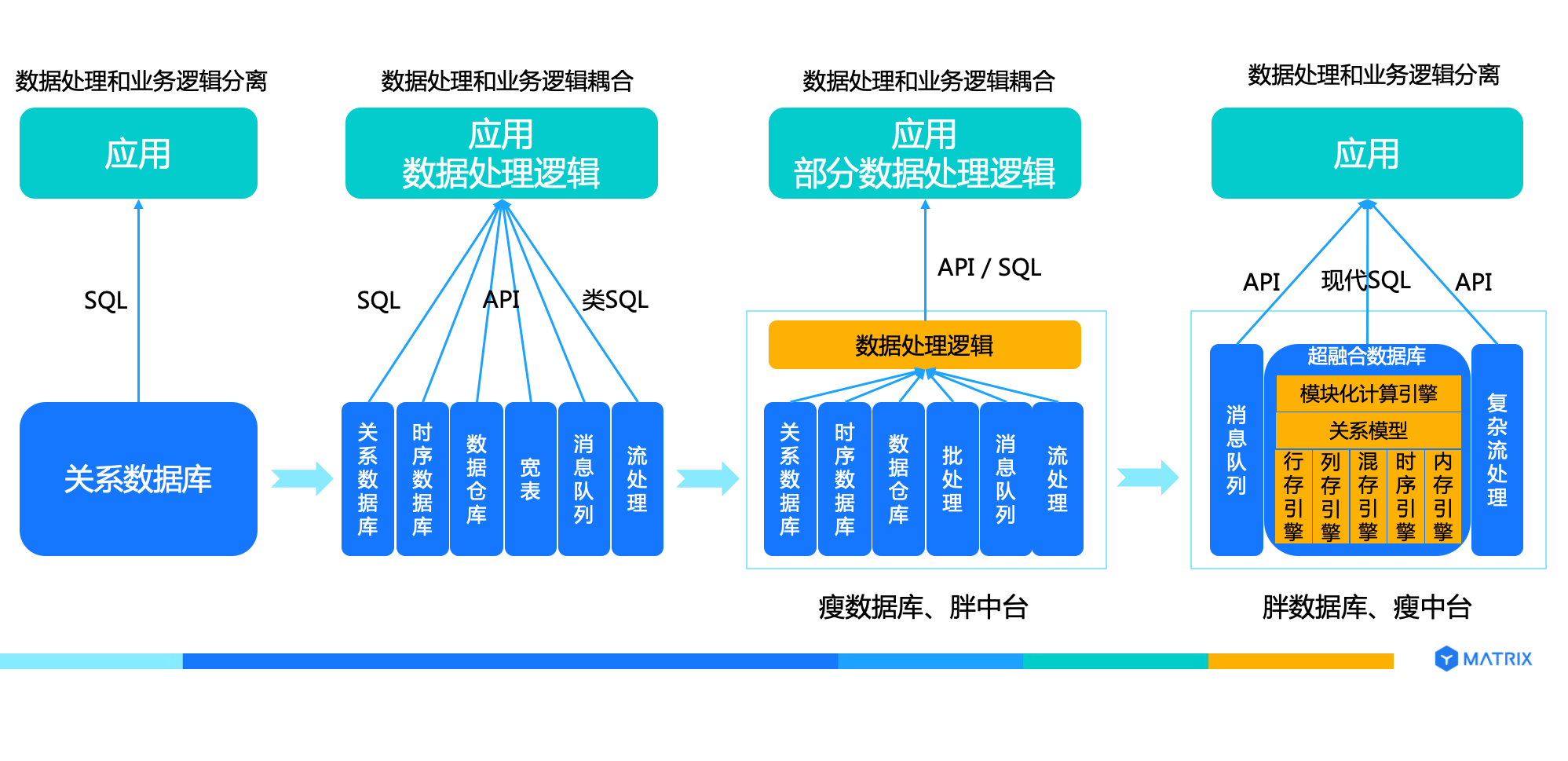
所以,由此衍生出一个问题,四大类产品之间需要频繁的数据搬运,整个技术栈非常复杂,如下图所示:
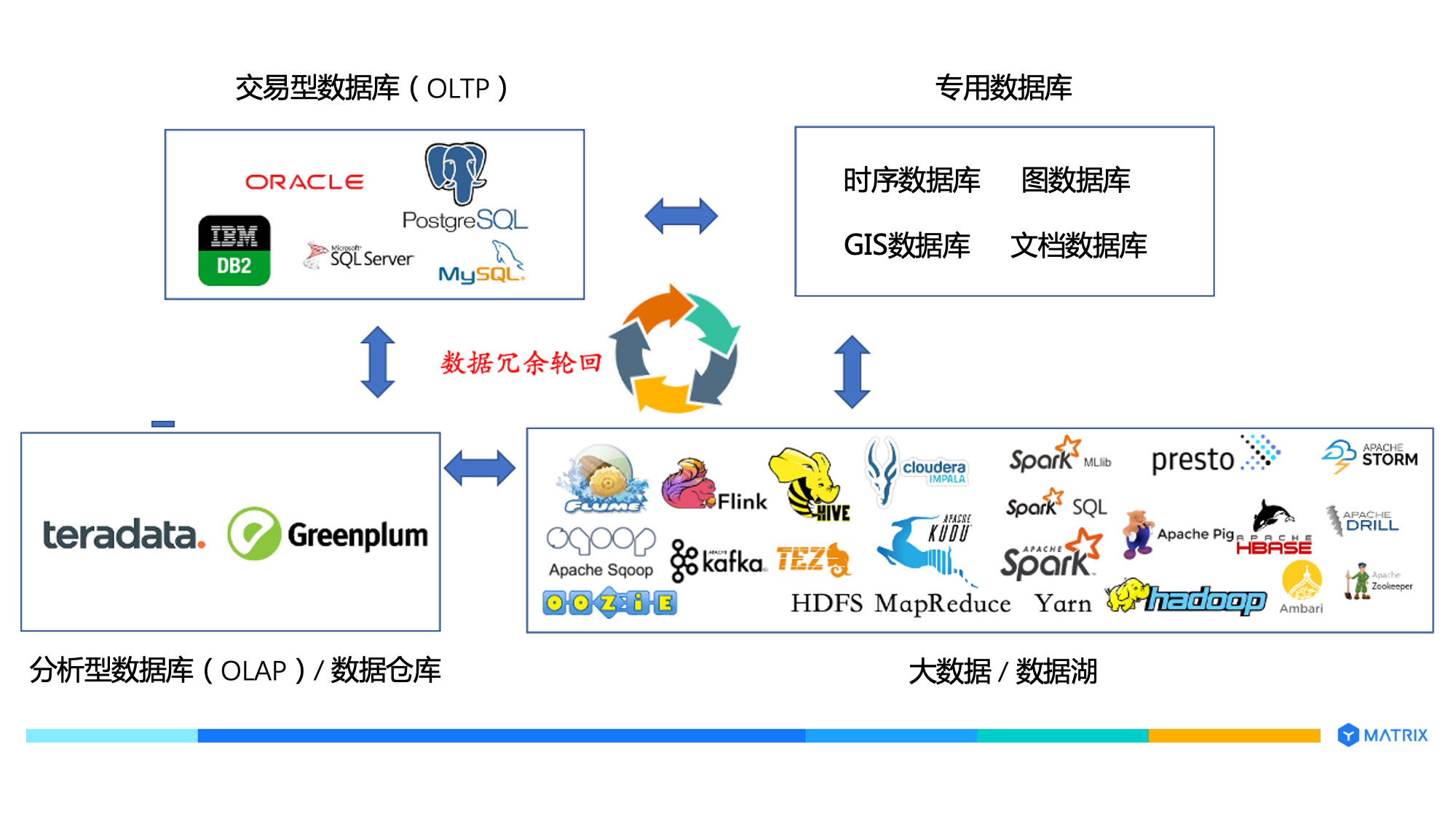 这种数据架构有诸多问题:
这种数据架构有诸多问题:
事实上,交易数据库从上世纪 70 年代就开始出现,用来解决文件、文档存储和管理数据时的效率低下和数据孤岛问题。
这个时代处于移动互联网爆发前期,被行业内称为VOS 时代,命名由引领行业发展的产品三剑客首字母缩写构成,它们分别是 Veritas(存储软件)、Oracle(数据库)、Solaris(操作系统)。其中,代表性的数据库产品除了Oracle 外,还有 IBM DB2、微软的 SQL Server。它们都是交易型数据库。
之后20多年,这类数据库是商业数据处理应用的核心,也是“one size fits all”的时代。
2005 年左右,互联网蓬勃发展,出现了一批新数据应用,其典型特点是 Volume(数据量大)、Velocity(数据增长快+实时处理要求高)、Variety(数据种类和来源多样)、Value(数据价值密度降低,比如点击网页的动作),交易类数据库没能快速适应互联网应用对数据处理的新诉求,于是出现了一批新产品。
其中,最耀眼的明星就是新的数据库技术栈 Hadoop,架构中的 HDFS 解决高可用廉价存储问题,MapReduce 解决批处理并行计算问题,HBase 解决宽列数据高效读写问题。
在此期间,一些商业化产品陆续冒头,试图解决一两个特定的问题,比如 MongoDB 通过文档模型解决灵活性和读写效率问题,ElasticSearch 解决文本检索问题,InfluxDB 解决时序数据处理问题,Flink 解决流数据处理问题。人们统称这一类产品为“NoSQL”,是 “one size does not fit all” 的时代。
随着时间推移,架构和产品复杂度不断上升后,数据中台概念推向市场。大数据架构师和开发人员根据需求,把各种产品组合在一起来解决业务问题。由于产品众多,把这些产品整合在一起的挑战很大,故而出现了“数据中台”厂商提供这种整合的数据平台服务。
但是发展到今天,拨开大多数数据中台的层层封装,核心以开源软件为主。虽然数据一定程度上回收复杂度,提升开发人员的效率,但由于缺乏强大的查询优化和执行引擎,故而很多可以使用现代 SQL 实现的能力,却需要用代码实现,这一定程度制约了开发人员的效率。此外运维的复杂度没有降低,反而随着集成的产品增加而增加。
与此同时,之前仅仅解决一两个特定问题的产品开始提供越来越多的能力,产品之间的界限越来越模糊。各种数据产品越发庞杂,新产品形态呼之欲出。
譬如,Kafka 提供了 KSQL,ElasticSearch 也支持SQL,Spark 提供了 DeltaLake,MongoDB 开始支持 Schema Validation 和分布式事务,Greenplum支持 OLTP 业务、JSON 半结构化数据和库内机器学习(In-database machine learning),PipelineDB 在关系数据库内支持流数据处理,ElasticSearch 支持机器学习等。
超融合数据库在这种形势下应运而生,博采 OLTP数据库、OLAP 数据库和大数据/数据湖众家之长集于一身,形成一种新的技术形态。
超融合架构的核心是灵活和强大的模块化与插件化,可以支持不同的场景,譬如可插拔存储器可以使用行存引擎支持 OLTP、使用列存引擎支持 OLAP、使用 LSM 存储引擎支持时序数据场景,通过多态存储架构可以同时支持存算一体和存储计算分离,通过自定义类型、自定义函数和自定义聚集支持库内机器学习(in-database machine learning)等。
同时,超融合数据库产品还能不断扩展,支持多模数据类型,包括关系数据、时序数据、GIS 数据、JSON 数据、文本数据、图片等。
超融合数据库是技术发展的自然走向。2011年,451Research 提出的 NewSQL 是 OLTP 和大数据的融合;2015年,Gartner 提出的 HTAP 是 OLTP 和OLAP 的融合;2020年,Databricks 提出的Lakehouse 是数据仓库和数据湖融合,都是对超融合技术趋势的探索。预计不远的 2022 年,超融合数据库技术将实现产品化和商业化。
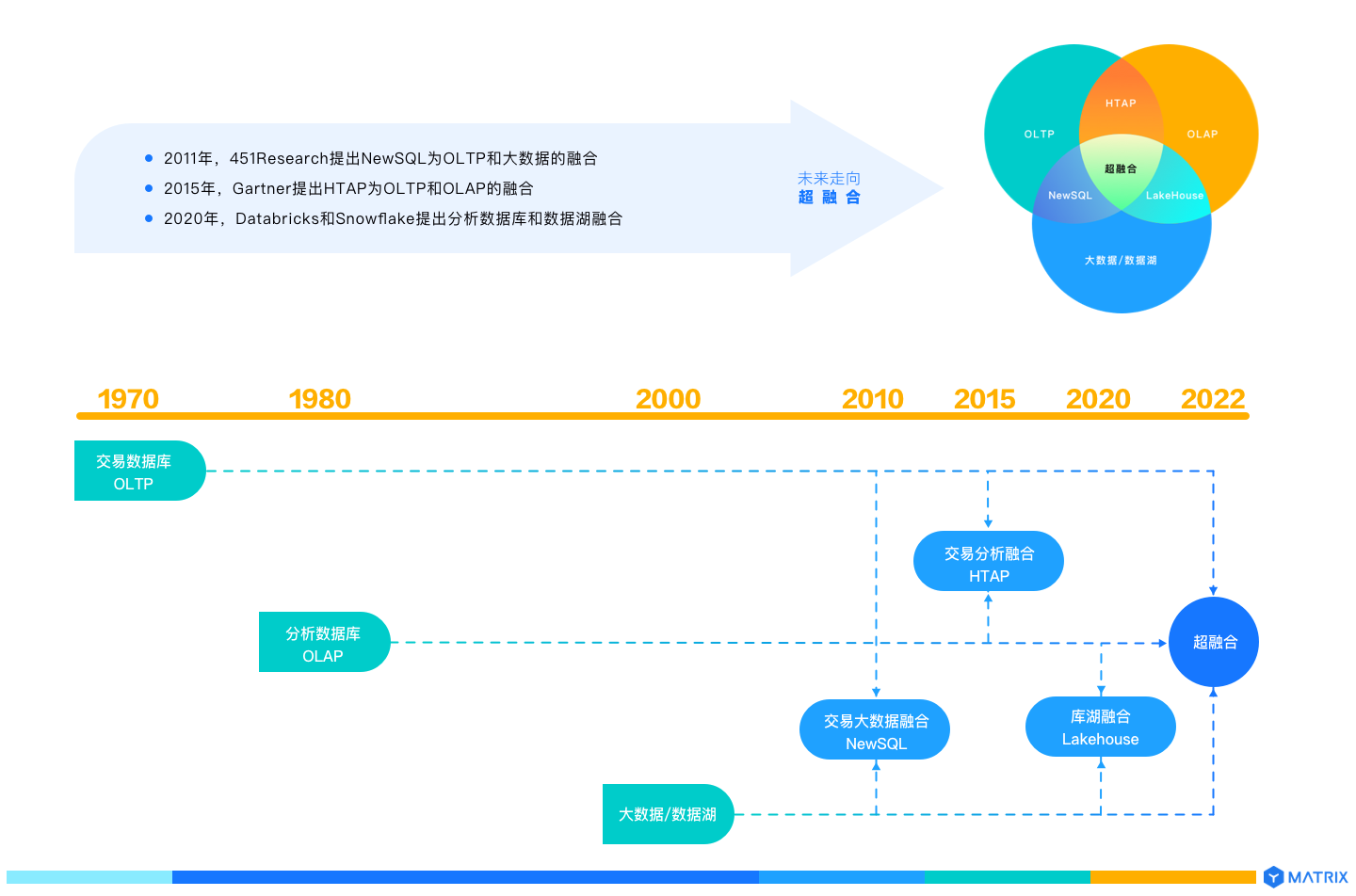 对比分散型数据库架构,超融合数据库通过融合多种技术于一体,可以很好的解决上面提到的四类问题:
对比分散型数据库架构,超融合数据库通过融合多种技术于一体,可以很好的解决上面提到的四类问题:
架构简洁:大大简化技术栈,降低系统复杂度,降低运维复杂度,提升开发效率。
性价比高:超融合数据库是轻量级的一站式基座,无需采购和运维众多单品数据库产品,就可以实现多模数据的多场景操作,大幅降低产品开销和运维开销,避免数据过量冗余存储和数据在不同系统之间的冗余流动。
业务迭代和创新:精简的技术栈帮助开发人员将精力集中在业务逻辑上,而不是数据处理上,业务迭代更快,为业务创新赋能。
提升用户体验:精简的技术栈易于驾驭,故障率低,最终用户体验好。
此外,超融合数据库还可以提供卓越的性能,比如更好的实现计算贴近数据,避免因为移动数据降低运行速度,同时支持分布式计算,以 YMatrix 自研产品为例,比传统的单机 Python 和 分布式 Spark + Hadoop 方式快 10 倍以上。
对于运维能力弱、不具备足够技术储备用户来说,比如正在加速推进数字化的新兴产业和传统产业,超融合数据库的采购和部署成本非常低,一个产品满足大多数数据管理需求,不需要采购大量不同产品,或反复经历选型到学习使用的繁杂过程,让管理者更轻松的启用数据库,解决数据管理能力强弱的问题。
从数字化升级的成本角度来看,对于绝大多数客户,数据量为百 TB 或者数百 TB 级别的,完全可以只使用一套数据库集群来处理 OLTP、OLAP 和大数据分析业务。架构开发省力、运维省心、老板省钱、业务迭代和创新迭代省时。下图一目了然的展示了超融合数据库架构的优势:
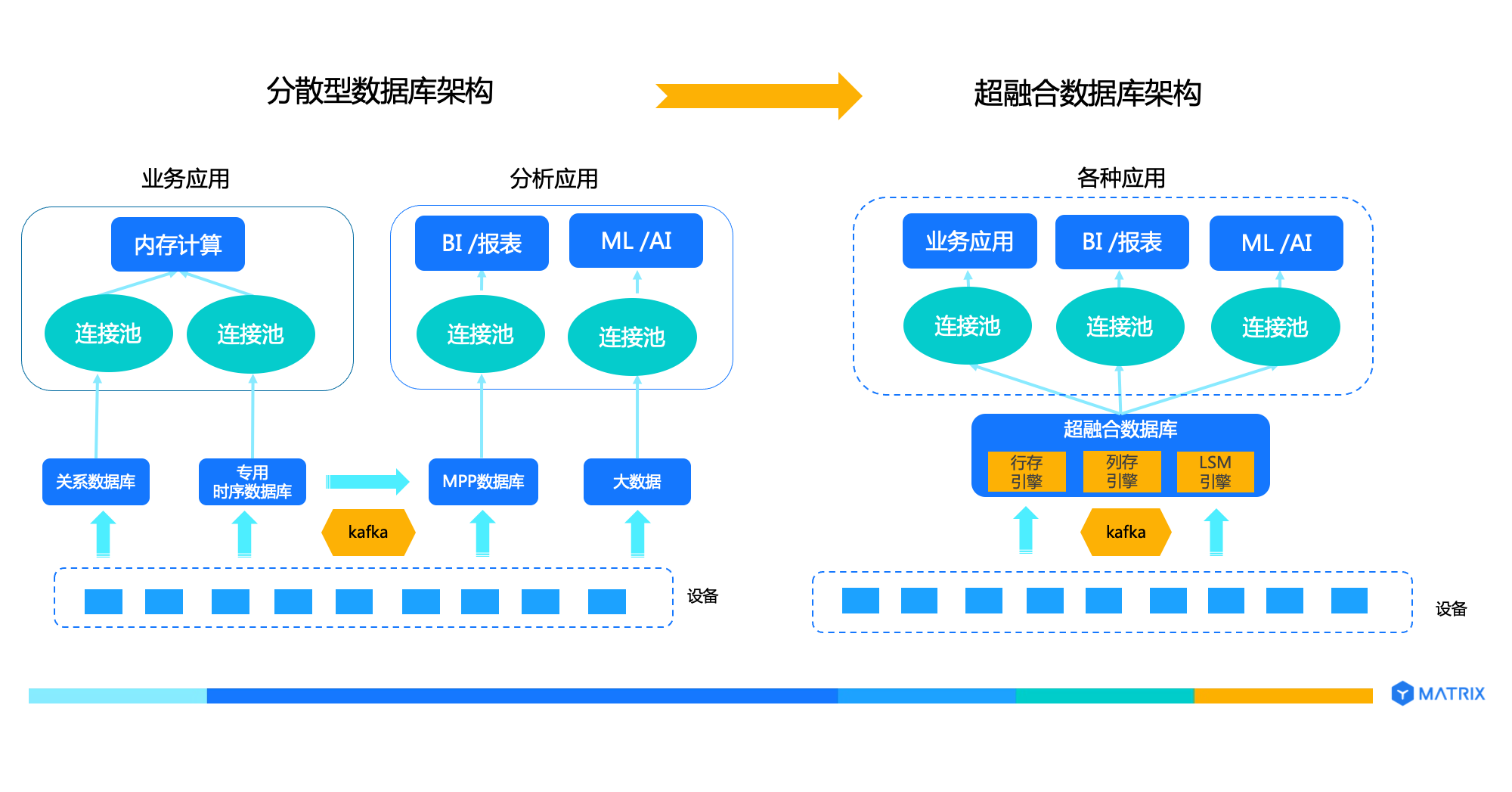 但是需要特别注意的是,如果数据量很大,譬如10PB 级别,一套数据库集群来处理全部业务是不现实的,此时可以使用多套超融合数据库来实现,不同的数据库集群偏向处理某种业务或者某类业务,集群之间可以高效互联互通。
但是需要特别注意的是,如果数据量很大,譬如10PB 级别,一套数据库集群来处理全部业务是不现实的,此时可以使用多套超融合数据库来实现,不同的数据库集群偏向处理某种业务或者某类业务,集群之间可以高效互联互通。
目前,超融合数据库不会替代专注优化极端场景的的数据库,例如双11、春晚微信红包等数据处理需求系统。但是,**随着超融合数据库的成熟与更新,绝大多数数据处理场景可以以超融合数据库为核心,替代以往笨重低效的“胖中台”,建设经济高效的“胖数据库、瘦中台”。
本文提到的“胖”、“瘦”比喻如何在整个系统内划分功能边界,不带有褒贬色彩。 其次,胖与瘦是相对的,本质是复杂度切分,是把什么样的复杂度留给谁,或者说谁选择解决什么样的复杂度:
在“one size fits all”时代,数据处理的复杂度由交易数据库承担,开发效率高,运维简单;
在大数据时代,数据处理的复杂度分散在数据库和应用中,应用开发效率变低,运维变复杂;
数据中台(或者数据处理平台)出现后试图把分散在应用中的复杂度收回来由数据中台承担,但是目前还没有出现很好解决这一问题的产品和解决方案;
超融合数据库,把数据处理平台体系内需要整合多个产品才能解决的问题集成到一个产品内,最大合理限度的把复杂度留给数据库,解放开发和运维人员。
过去五十多年,数据库经历了层状数据库、网状数据库、关系数据库、对象数据库、XML 数据库、KV 数据库、文档数据库、列族数据库、时序数据库、图数据库、内存数据库、并行数据库和分布式数据库等不同技术和产品的洗礼,很多优秀技术沉淀下来。
发展到今天,模块化、可插拔的数据库基础技术已经比较成熟,在这样的技术能力之上,通过插拔存储器、执行器、优化器等方法在超融合数据库中支持不同的数据类型,包括结构化数据、时序数据、GIS 数据、JSON 数据、Text 等,支持不同的业务场景,包括交易业务、分析业务和流数据处理业务,把数据处理逻辑再次打包到数据库中,通过现代 SQL 与应用进行对话,让开发运维人员聚焦到业务逻辑而不是数据处理逻辑上:
开发省力:超融合数据库替代多个不同的数据库,并提供现代 SQL 能力,开发人员不需要从不同数据库中读取数据到内存再进行计算合并聚集关联等,而是直接使用现代 SQL 能力进行数据处理,一条 SQL 语句抵数千行代码,大大提升效率,降低错误率。
运维省心:运维管理一套数据库而不是多套数据库,无需在不同数据库之间搬运数据,安装配置、监控告警、安全保护、备份恢复、扩容、升级等工作量大幅降低。
 我们认为,复杂度最大合理限度,应该留给数据库,而不是对应产品的使用者。所以,超融合将是数据时代的又一次变革性跨越。
我们认为,复杂度最大合理限度,应该留给数据库,而不是对应产品的使用者。所以,超融合将是数据时代的又一次变革性跨越。






