
2021 年底,YMatrix 与国内某头部动力电池制造⼚商达成合作,助力其完成“制造业数据湖仓平台”的升级建设。该系统用以支撑全球电池溯源追踪、生产制造及售后运营分析等多项核心查询业务,其中单表的平均数据规模超百亿级。
在项目中,YMatrix 超融合数据库完成对原有 Greenplum 集群的替代:一方面承载由 ERP、MES 产生的传统关系型业务数据,使业务查询性能及作业效率显著提升,查询耗时最高缩短 79%,同时使系统稳定性及运维效率也得以大幅提升;另一方面,面向新兴的物联网业务,提供 PB 级数据存储能力,支持亿级每秒的写入性能,支持乱序、延迟等复杂写入,原生支持聚合、窗口等复杂时序查询。整体上,依托 YMatrix 的跨模态融通管理能力、全场景查询能力及库内 AI 能力,整个系统可不断敏捷延展,以支持更多的数据场景,查询分析运作效率更高。
在帮助集团侧完成改造的同时,项目也通过在分支工厂部署 YMatrix 集群,构建可支撑多系统的工厂统一数据基座,实现数据平台的云边协同架构,帮助客户建立起“集团总部-工厂分支”的总分数据管理体系。在业务规模不断高速增长的情况下,大幅缓解总部集群的负载压力。
目前 Greenplum 集群所承载的“全球电池溯源系统”是面向上下游合作伙伴开放的在线业务,但由于现有集群性能有限,在达到一定量级的并发连接下,会出现系统卡顿,甚至无法访问的情况。同时,当遭遇线上紧急需求时,如数据报表、紧急事件溯源分析等,系统作业效率有限,查询缓慢,甚至引发客诉。而且,为了保障系统的稳定运作,又需要较频繁进行定期维护,维护期间整个集群不可用,数据无法查询,对外业务中断,这也更进一步影响了整个平台的使用体验。现有 Greenplum 集群使用中的主要问题有:
在该集团的产线中,除了由常见的 MES、ERP 系统所产生的关系型数据,还有由数采单元面向设备、物料和流程采集到的时序、GIS 等类型数据,比如涵盖近百个指标的生产制造设备工况数据、已售出电池运行数据以及历史维修数据等。目前架构中是通过 MySQL 和 Greenplum 来承载时序数据,但 MySQL 及 Greenplum 并不具备专门针对时序场景的强化特性及功能,数据承载力和查询能力都十分有限:
在实际业务中,各系统各类型的数据将被综合利用,以判断生产和运行中的真实情况,并基于此,对生产设备预测性维护,生产工艺优化、产品运营告警等业务提供数据洞察支持。
客户曾尝试通过 Hadoop + 专用数据库的方式:第一步扩展对新数据场景(如时序)的支持,第二步在此基础上基于 Hadoop 构建大数据平台,以支持数据的综合分析需求。
但是,不断叠床架屋的引入专用系统来应对新场景,将造成系统整体复杂度的几何级数增长,致使后期维护迭代的成本飙升;同时,Hadoop 技术栈本身的自研门槛高,后期的运营维护、迭代开发以及使用操作都比较复杂,并且集群性能有限。
目前,该集团在全国拥有 20 多家子公司,每一家子公司的产线系统都需要高性能及可靠稳定的数据管理系统。在未来的 2-3 年内,预期整个集团将持续以倍数级扩充产能,产线数据量将翻倍增长,对数据管理的承载力、效率、成本和易用性都提出了更高标准。
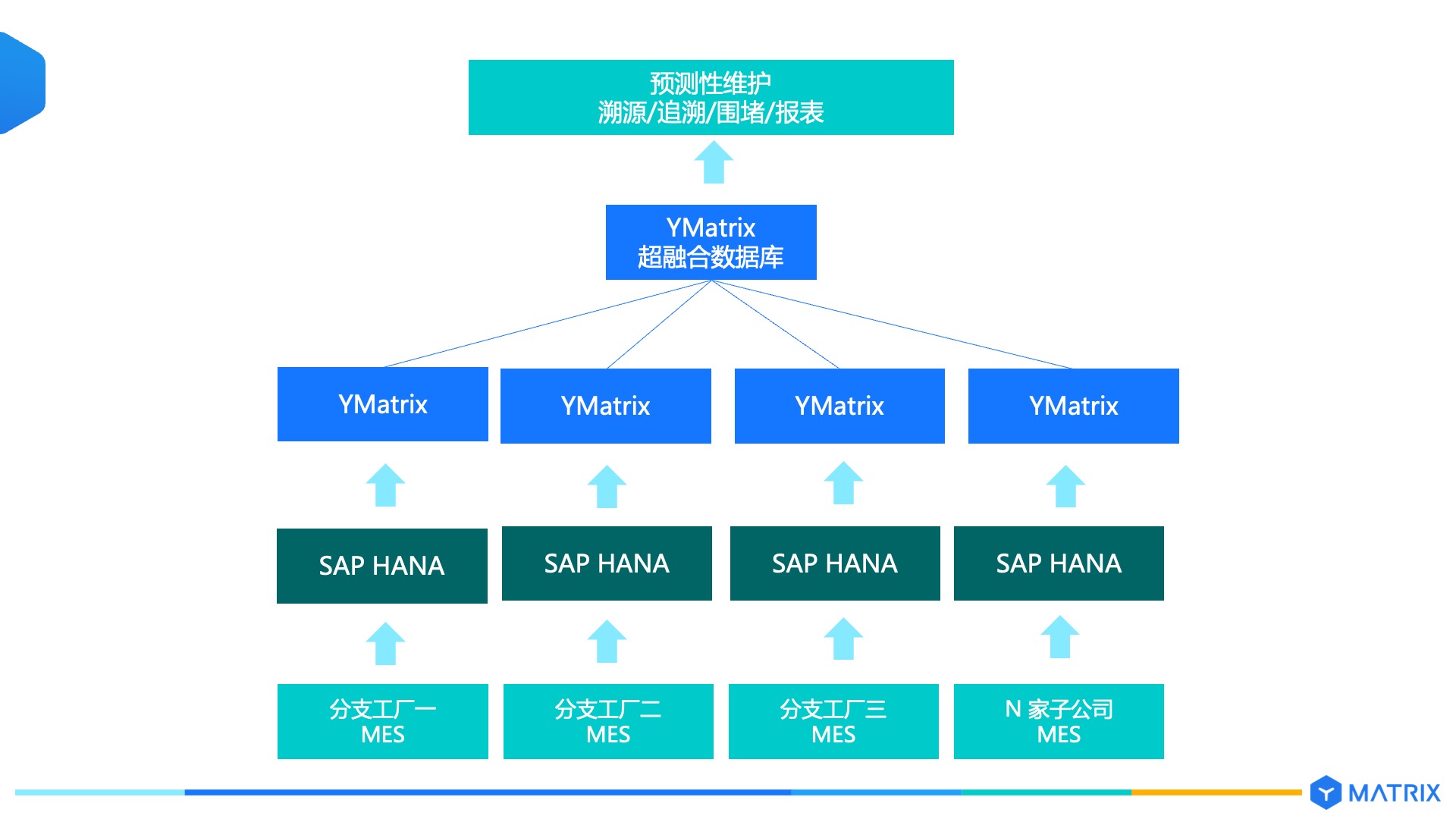
目前所有数据直接进入总部,对总部集群造成很大负载压力。除了持续扩容外,在不增加太多运维复杂度的基础上,客户迫切希望建立一套总分结合的“总部(云)+工厂(边)”协同架构,在增强整体数据承载能力的同时,也优化各子公司的数据平台能力,实现对整体数据管理与治理能力的升级。
由 YMatrix 替换 Greenplum 承建数据湖,对接产线 MES 系统( SAP HANA ) 及 ERP 系统(Oracle),用于将生产电池的一系列物料、用料、流程、设备等数据进行整合归集,并承载电池用料查询、生产流程步骤查询等业务分析作业。
替换 Greenplum 集群后,查询作业时间最高缩短 79%,系统 CPU 占用率明显下降,集群整体规模缩减超 30%, 提供图形化的在线扩容方案,业务持续性得到明显改善。
YMatrix 替代 MySQL 承接产线设备产生的运行状态时序数据: 1)承载高并发、大规模的时序数据写入 2)在产线复杂工况环境下,支持数据乱序、延迟写入,支持 ACID 以确保数据完整性; 3)提供明细查询、聚集查询、窗口查询、关联查询、多维查询等高级时序查询能力; 4)与 MES、ERP 系统(关系型数据)实现数据融通,在数据湖内实现数据的跨类型联合分析,而无需再并行建设专门的技术栈; 5)可进一步扩展 GIS、JSON 、图数据、视频/图像等多种数据类型,为支持更多数据场景奠定统一支撑平台; 6)提供库内 AI 能力,支持在湖内进行机器学习的建模及推理运算。
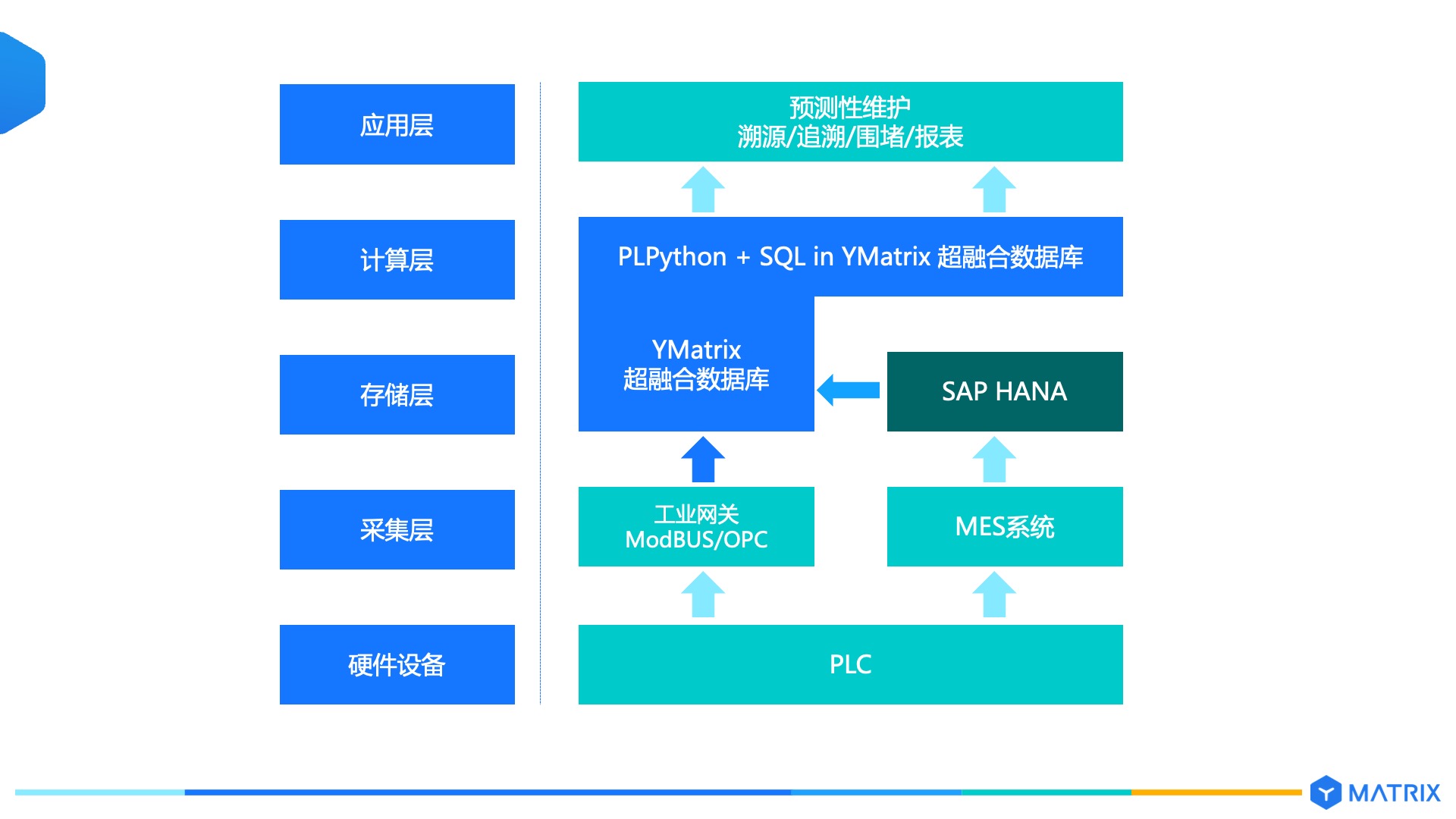
YMatrix 同时已完成在分支工厂的部署,作为分支工厂的独立数仓平台,承载工厂的 MES、ERP、PLM 等各系统数据,完成这些生产数据在本级的数据归集,同时进行预处理查询分析,筛选出符合总部需要的数据后在上传总部集群。
新构建的总部(云)和工厂(边)协同架构,在强化本地数据就近处理分的能力之上,有效降低了集团集群的负载,为后期业务的长期稳定运行及良性扩展奠定架构基础。
动力电池售后数据分析业务,需要对接来自外部整车厂回传的电池运行数据(电压、电流、温 度、充放电等指标),并汇总内部的生产数据进行综合分析,最终输出电池的运行分析报告,评估电池健康度,预测并提示故障概率,并反馈生产工艺的调整是否取得预期效果等。
售后大数据分析系统原采用 Kafka + MySQL + Flink + Spark 架构来,通过 MySQL 节点承接电池时序的写入和存储,然后将数据拉入独立的 Spark 集群中执行分析计算。
此次项目通过 YMatrix 架构替代了 Spark 及 MySQL 集群 ,通过 YMatrix 中的专用接入组件 MatixGate 自动消费 kafka 数据(无需 Flink ) ,将数据存放在 YMatrix 中,并通过库内 AI 能力在 YMatrix 库内完成建模计算(同样支持通过 Python 建模)。
整个数据流转的过程全部发生在 YMatrix 集群内部,大幅简化系统架构,且性能大幅提升,集团某分支工厂内的电池健康状况分析报告产出性能提升 10 倍。

用 YMatrix 替换现有 Greenplum 集群后,解决了目前集群性能不足、扩容服务器速度耗时长、报表查询等待过久等各项问题。原有平台⼀万 SFC 溯源查询平均耗时 509.26秒,新平台等量查询耗时78.1秒;原有平台五万 SFC 溯源查询平均耗时 2156.67秒,新平台等量查询耗时 453.57秒,为平台支撑的各项业务服务体验提供充沛的性能支撑。
同时,通过搭建更科学经济的“总部(云)+工厂(边)“协同架构,减少数据传输成本的同时,降低因组织结构庞大、产能持续壮大给总部集群带来的压力。
通过 YMatrix 超融合数据库,支持多模态数据的全场景查询分析需求,能够服务企业级用户未来 5-10 年可能存在的需求,帮助客户避免了产品叠加、或技术架构反复调整带来的技术风险和不必要成本。
集群规模节省超30%:在为⼤数据平台带来了上述优化与新功能的同时,在保证性能满⾜需求的前提下,使得客⼾每年在资源上的成本开销减少了⾄少30%。
节约对新产品、新架构的学习成本:YMatrix 研发团队是原 Greenplum 产品的完整建制团队,承袭了 Greenplum 分布式数据库产品的技术积累,为客户从 Greenplum 迁移和新架构学习提供了效率和便利。
YMatrix 提供大量图形化及自动化的运维能力,包括:在线扩容、自动数据平衡、数据生命周期管理、运维监控等,帮助用户降低操作门槛、获得更好的使用体验以及更加自动化的作业能力。
同时,YMatrix 通过数据超融合能力大幅精简了系统架构,也从根源上降低了运维复杂度,运维人员需要管理的技术栈变少,需要应对的底层技术问题更少,工作更加专注,作业更加高效。






