
12 月的新能源汽车销售市场异常火热,特别是理想汽车,凭借新车 L8/L9, 斩获 SUV 品类销冠,并成为首个单月交付量超过 2W 的“造车新势力”。
如此亮眼的“逆袭”表现,理想的制胜策略到底是什么?而“互联网造车”崇尚的数据驱动,又究竟如何发挥作用?作为数据驱动的底层基础设施,数据库对车企是否真的至关重要?
本文希望通过 YMatrix 与理想汽车的合作案例,探讨这些问题。
刚刚过去的 12 月,新能源汽车销售市场一片红火。
虽然不是传统金九银十的销售旺季,但进入 2023 年,施行 13 年之久的新能源车购置补贴政策将正式落幕,大批观望需求在政策关门前集中释放,造成年底的一波销售热潮。
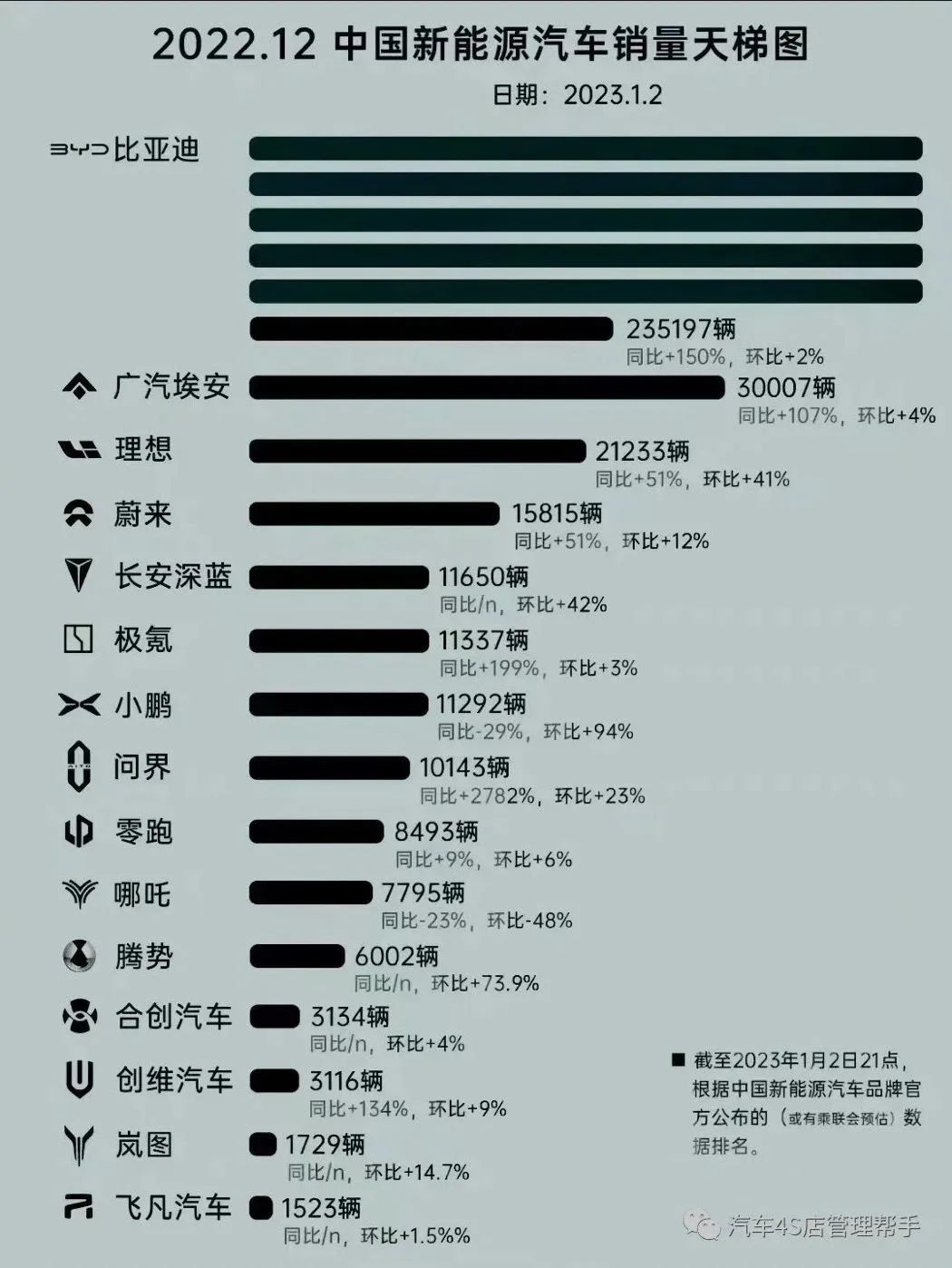 12 月新能源汽车销量
12 月新能源汽车销量
比亚迪代表的传统车企持续稳健增长,而前三个季度略显疲态的“新势力”们,也在 12 月打出了翻身仗。
“蔚小理” 在 12 月均实现了较大的环比增长,理想更是代表造车新势力,第一次实现单月交付量突破 2W 大关。
更值得关注的是,根据新车上险量数据,理想 L8、L9 两款新车加冕 SUV 市场上的王者,击败一众一线大品牌。
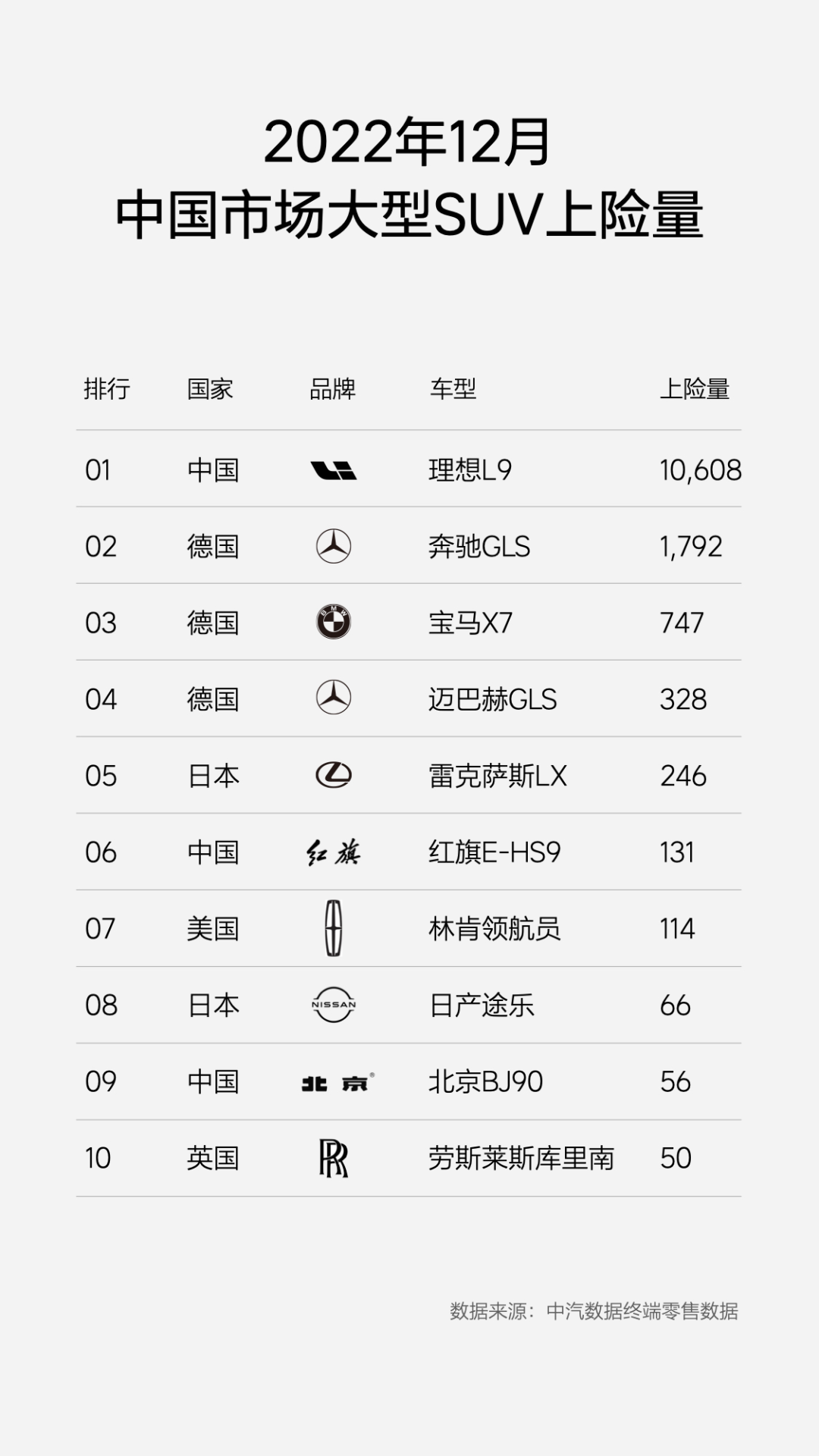
12 月 SUV 上险量数据
诸多迹象都表明,新能源已经进入新的市场阶段:新能源车的市场渗透率已经超过了 27%,比规划中 25% 的发展节奏更快,2023 年增速预期放缓;购置补贴已正式落幕,促使价格竞争更加激烈;磷酸锂矿价格一路上涨,推动电池价格不断走高 ......
来自市场侧和生产侧的不确定性都在增加,全行业将告别集体性的狂飙突进。各大厂商需要拿出十八般武艺,轮番上阵,在每个可能的地方,提效率、抠成本,在更多目前还不可能的领域,搞创新、求突破。
在这样的背景下,理想汽车近期实现“逆转”的业绩表现,更显突出。
年中发布的全新车系 L9、L8 ,无疑是理想 2022 年的重要节点。进入第四季度,L9 与 L8 成为主力交付车型,而正是在这个阶段,理想不仅扭转了前三个季度交付持续下跌的局面,更是不断刷新单月交付纪录,一举奠定了全年超越蔚来的局面。
"理想L9,500万以内无对手的家用 SUV "。
这句引爆热搜话题的广告语,直白地说明了理想"为家庭用户造车"的差异化定位。
小编依然记得,秋季某日开车回家路上,见得前方一辆新款理想。还未识别出是什么车型,但通过后车窗,能清晰看到从中顶悬挂下来一块硕大的屏幕,上面正播放着《小猪佩奇》的片段。
一块大屏在当下并不新鲜,而打动小编的,则是这块大屏恰如其分的出现时机及位置,以及屏幕上闪现的内容。
回家路上,一家三口,各美其美。
 理想 L9 座舱示意图
理想 L9 座舱示意图
这种对需求的精准捕捉和塑造,建立在广泛的运营交互基础上。一方面,与用户高频的互动需要运营手段来维护;另一方面,也需要通过长期互动积累下的运营数据,洞察需求细节;更重要的是,如何将这些数据洞察,转化成生产中的标准流程?这些都需要通过一套数字化运营体系来实现。
得益于自身的互联网基因,理想从初期就建立起一套完善的数字化运营体系:前端有各种 web 化的业务应用(如面向车主的 App、 售后服务所需的管理平台),通过 API 接驳到各个类型的业务/数据中台,获取业务赋能和相关资源,而最底层则是大规模的分布式集群化基础设施。
但汽车毕竟比虚拟的互联网更加复杂,牵扯更加复杂的业务流程、更密集的线下实体资产、更多变的工况环境。面向庞杂的汽车工业体系,如何设计一套数字化运营体系,理想也面临着诸多新挑战。
正是在这样的契机下,YMatrix 与理想汽车不期而遇。
彼时,YMatrix 提出超融合数据库理念,以时序数据场景为切口,希望为用户提供一套既能“放心存”(多种数据类型的高性能写入与高效率存储),又能“随心用”(全场景的数据查询与算法分析)的统一数据基座。而理想汽车数据平台团队,则在寻找新的技术方案,以全面升级基础数据平台的业务保障能力。
双方在理念上的契合,随即转化为夜以继日地碰撞、磨合与通力协作。项目面临着诸多挑战:
首先,如何存储下更加庞大的“大数据”,比互联网数据再大出几个数量级的“大数据”。理想目前对每台车都要回收几千个数据指标,这些数据按照一定时间频率源源不断上传。只要有车辆运行,就会有大量的数据产生。目前基本每隔几个月,数据总量就会翻倍。另外,不同于互联网相对平稳的运行环境,车辆则运行在复杂多变的真实环境中,数据的采集和上传会遇到各种极端工况,数据的延时、乱序、丢失、找回,增补等情况有可能随时发生,需要能灵活应对。
具体到底层的数据库,需要特别关注性能、存储效率和扩容便利性。例如:数据的写入速度、对复杂写入场景的支持、数据入库后的存储压缩比、分层存储策略等等;同时,面对高速增长的业务需求,持续不断地进行扩容将不可避免。那么扩容操作是否会影响正常的业务运行、影响多长时间、操作是否简单可控,这些都是需要回答的问题。
其次,如何更加敏捷地响应业务需求,做到赋能业务,而不是成为发展瓶颈。一个典型的场景是:当业务遇到一个具体问题,业务团队会提需求,需要迅速地定位、分析、归因、并最终落实解决方案;分析团队则给出分析方案和算法,而数据团队需要能迅速的提供数据接口,以最快的速度响应。
这时,底层数据库的性能是基础保障,各类查询性能一定要做到极致;另外,开发难度要低,从数据库到数据接口,越是简单直接、越是标准通用、越是有充足的监控与运维保障,对数据开发团队来说效率会越高。
围绕着这些挑战与需求,经过双方数月的共同努力,项目最终于 2022 年初顺利上线,并平稳运行至今。
YMatrix 在承载同等规模数据的情况下,仅通过 14 个节点集群就实现了对原有 50 节点 OpenTSDB 集群的替换,使集群服务器用量减少 2/3。
同时, YMatrix 提供了一套平滑扩容方案,在业务不中断的情况下,可以实现集群规模的平滑扩展,整个过程可完全通过 UI 可视化界面进行操作,为运维人员提供更加简便、直观、流程化的操作体验,扩容不再是意外不断的闯关之旅,而成为有章可循的 SOP (标准流程)。
另外, YMatrix 也提供了超过 100 项的核心运维监控指标,覆盖写入性能、查询性能、集群状态等多个方面,为运维人员精准掌握平台运行状态,以及故障定位、归因分析提供了丰富的监控数据支撑。
另一方面,平台原有的 OpenTSDB 不支持聚集查询、窗口查询等复杂时序查询,因此类似的复杂查询需要通过在 Hive 及 Flink 集群中独立编程来实现,代码开发具有一定的技术门槛,后期的维护成本也较高。YMatrix 则原生支持全面的时序场景查询功能,如聚集查询、窗口函数、跳变查询、差值查询等等等,业务开发人员可通过标准的 SQL 语言就可以直接通过 YMatrix 获得查询结果,指标开发时间从原来的几天,大幅缩减到 1 小时以内。同时,YMatrix 也使查询性能得到大幅提升,如指标明细等常用查询,耗时缩减至 1 秒内,最大降幅超过 90%。
回到开头我们的问题:数据库能帮助新能源车企赢得下半场吗?
数据库当然不能,但数据能。
让数据成为第一生产要素,是理想和 YMatrix 共同的理念。
理想通过车辆运行数据数据,捕捉最细微的用户需求、驱动业务迭代,对已成形的运营体系不断提升效率;而在生产端,数量庞大的产线和设备数据也在源源不断地产生,基于这些数据构建的智能制造体系,将有无限的想象空间。这也许就是理想赢得未来激烈竞争的要素之一。
YMatirx 则希望通过自己的技术和代码,让各种场景中的数据找到自己最佳的“栖身之所”,打造数据基座,激发数据汇聚的力量,帮助企业更高效的生产数据、更简单的使用数据、更深度的挖掘数据。
2023 年已经到来,后疫情时代,不确定性并未完全消散。新能源汽车迎来变局,而更多产业也将选择通过数字化转型来应对变化,让数据成为第一生产要素的理念,会在更多企业落地生根。YMatrix 希望与这些企业携手,共同探索产业数字化之路。






