_1746770295.png?x-oss-process=image/resize,h_300/format,webp/quality,q_80)
某大型能源科技公司,致力于为全球客户提供领先的清洁能源产品和服务,拥有多个新能源电池生产基地。该公司目前仍在建设年产量可达 30GWh 和 24GWh 的新能源电池项目。该公司所使用的数据系统分为工厂级 MES 层和产线层。
由于当前数据系统中存在多条产线,且每条产线使用的数据库种类不尽相同,包括 Oracle、HANA、SQL Server、MySQL 等,造成各产线中的数据采集标准不一致,难以进行数据的统一存储,从而导致产线中“数据孤岛”问题突出。
同时,当前系统的工厂级 MES 层在数据查询和分析性能上无法满足业务要求,严重制约数据价值的发挥。
建设数据湖项目,解决数据孤岛和 DB 计算效率慢的问题,以满足各种应用场景的需求。
数据孤岛严重,多产线数据标准不统一,数据集成困难;
数据处理和性能无法满足当前业务要求,无法发挥出数据价值。
产线 DB 多样。各产线使用的数据库不一致,数据采集方式及入库标准不一致,数据难以做到统一管理
技术栈复杂。需要通过 KapWare 中间件实现各产线数据与工厂层 MES 的数据通信
查询分析效率低。当前使用的数据系统不满足业务需求,在进行数据查询和数据分析时,不能及时响应操作,复杂查询延迟高, GP 一小时内无法出结果,Oralce 查询无响应
系统稳定性差。前端进行复杂 SQL 查询时,Oracle 无法满足分析性能要求,GP 也仅能满足基本分析性能要求。
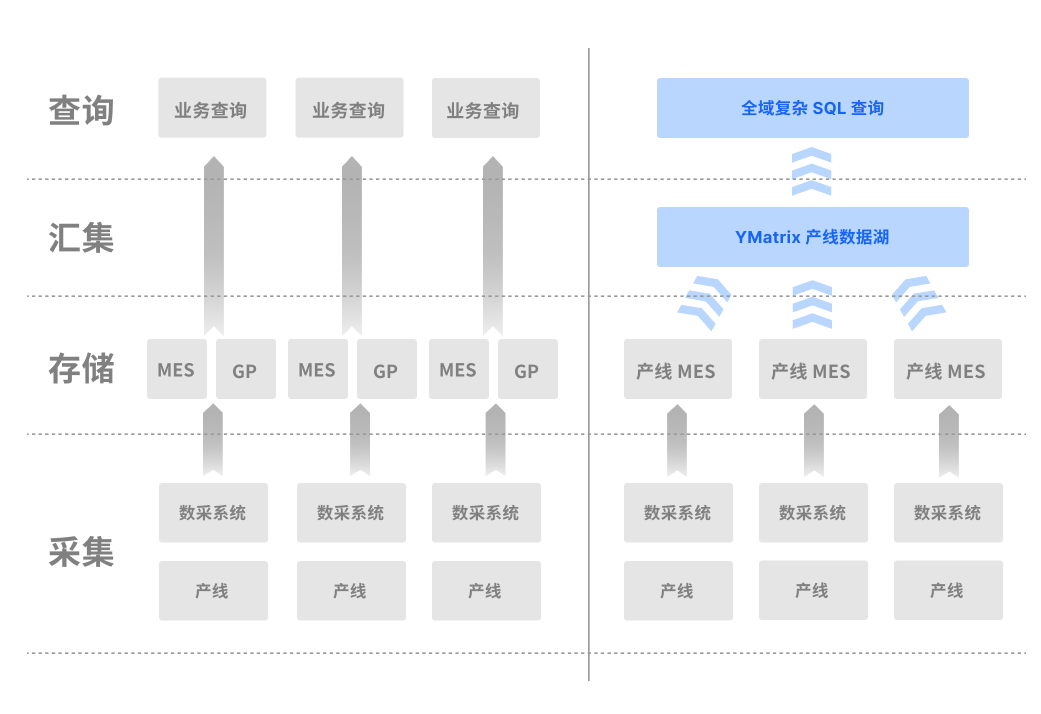
使用 YMatrix 建立产线数据湖,支持产线 DB 和产线历史数据的统一管理。
运用 MatrixGate 数据迁移工具将数据以并行的方式写入 YMatrix 中。
基于创新的存储引擎和计算引擎支持数据的迁移压缩和复杂 SQL 的批量计算,加速数据分析效率。
在 YMatrix 中可直接使用 SQL 查询库内数据,无需额外开发平台(Python)的支持,高效简洁。
同时,库内流计算支持实时数据分析,可满足可视化实时交互分析的需求。
架构简化,写入延迟低
迁移压缩效果好
复杂查询效率高
“放电-电芯-模组”VBA 报表的查询优化
多维度动力电池数据处理,包括制程、维修、重工、条码关联、原材料、流程、模组维修、电芯工序程序、模组工序、PACK 等开发工作。
使用 YMatrix 建立数据中台,建立数据入库标准,实现工厂级 MES 和产线 MES 的数据的统一入库。
使用库内 Python 智能算法替代库外 Python 处理程序。
在此基础上,通过创新的存储引擎和计算引擎助力数据查询效率的提高。
YMatrix 数据仓库提供独创的库内流计算技术,可实现数据流批一体处理,实现历史数据和实时数据的分析计算,支持多维数据报表查询,提升报表响应速度,为新能源电池的数据分析和追溯溯源提供稳定的基础支撑。
将 Python 数据处理程序内置入 YMatrix,实现库内 Python 计算,保障数据一致性。
10 + 表,百万级关联查询,数据返回< 3s
12 张表,24 亿行数据,查询秒级响应
多维追溯报表分析,效率提高 10 倍+
数据中台统一管理工厂级 MES 和产线级 MES,最大化发挥数据价值。






