在数据驱动的时代,企业依靠数据分析做出更明智的决策。但并非所有的分析需求都是一样的。有时,你需要立刻知道正在发生什么,以便立即行动;有时,你需要深入挖掘历史数据,寻找长期趋势和模式。这就引出了数据分析领域的两个核心范式:离线分析和实时分析。
离线分析 (Offline Analytics / Batch Processing): 顾名思义,这种分析发生在数据“离线”之后。它通常针对已经存储在数据库、数据仓库或数据湖中的历史数据进行。分析任务是按计划(如每小时、每天、每周)批量执行的,结果往往有一定延迟(通常是小时级、天级甚至更长)。常见的例子包括生成每日销售报表、月度财务总结或季度用户行为回顾。
实时分析 (Real-time Analytics / Stream Processing): 这种分析则追求极低的延迟(秒级、毫秒级),处理的是正在持续不断产生的数据流。它旨在提供对当前状况的即时洞察,支持需要快速响应的场景。例如,监控在线交易以检测欺诈、跟踪物流车辆的位置更新、或根据用户当前行为调整推荐内容。
理解这两种分析方式的本质区别、各自的适用场景以及优缺点,对于构建有效的数据架构和支撑业务目标至关重要。
核心对比:场景驱动,优劣分明
选择离线分析还是实时分析,关键在于你的业务场景需要什么样的数据时效性和处理深度。让我们分别看看它们的主战场、优势和面临的挑战。
实时分析:把握当下,快速行动
典型应用场景:
- 风险监控与即时拦截: 金融机构需要毫秒级识别并阻止可疑交易(如盗刷、欺诈);网络安全系统需实时检测并响应异常流量或攻击。
- 物联网与设备监控: 工厂生产线传感器数据流需要实时监控,一旦设备指标异常(如温度过高、振动异常)立即告警,预防故障。智能汽车实时收集并分析行驶数据。
- 个性化用户体验: 电商平台或内容平台根据用户当前浏览、点击行为实时调整推荐的商品或信息流,提升转化率和用户粘性。
- 运营状态实时可视与告警: IT运维监控系统实时显示服务器状态、应用性能指标,一旦出现宕机或性能瓶颈立即通知运维人员。
- 动态定价与供需调整: 网约车平台根据区域内实时供需(车辆和乘客位置)动态调整价格;外卖平台根据订单和骑手分布优化调度。
核心优势:
- 即时性: 提供近乎实时的洞察,让你能对正在发生的事情做出快速反应。
- 快速响应: 支持自动化决策和即时干预(如阻止欺诈、触发告警)。
- 提升用户体验: 通过实时个性化(推荐、广告)显著改善用户感受。
- 风险控制: 在损失发生前及时识别并处理风险。
面临的挑战与局限:
- 技术复杂度高: 构建和维护实时数据处理管道(涉及消息队列、流处理引擎等)比批处理更复杂。
- 基础设施成本高: 需要持续运行的计算资源来处理源源不断的数据流,硬件和运维成本相对较高。
- 数据处理规模受限: 为了追求低延迟,通常无法处理极其庞大的历史数据集,往往需要对流数据进行采样、聚合或窗口计算。
- 数据一致性保障难: 在高速流动下确保每条数据只被处理一次且结果准确(Exactly-Once语义)是重大挑战。
- 对管道稳定性要求极高: 任何环节(数据采集、传输、处理)的中断都可能影响实时结果的准确性。
离线分析:深度挖掘,复盘历史
典型应用场景:
- 历史趋势分析与报表: 生成销售业绩月报、年度财务报表、市场活动效果分析报告等。
- 用户行为深度洞察: 分析用户长期行为路径、构建精细用户画像、进行客户分群(RFM模型等)。
- 数据挖掘与机器学习: 训练复杂的预测模型(如销量预测、用户流失预警)、执行关联规则挖掘、进行大规模聚类分析等,这些通常需要遍历大量历史数据。
- 数据仓库构建与管理: 整合来自不同业务系统的历史数据,形成统一的企业级数据视图。
- 审计与合规报告: 基于完整、准确的历史数据生成满足监管要求的审计报告。
核心优势:
- 处理海量数据能力强: 专为处理存储在硬盘上的TB/PB级历史数据集而优化,可以运行非常耗时的复杂任务。
- 计算深度和复杂度高: 支持执行复杂的SQL查询(涉及多张大表关联Join)、运行迭代算法(如机器学习训练)、进行深度统计分析。
- 成本相对较低: 可以利用夜间或业务低峰期的闲置计算资源进行批量处理,资源利用率高,总体成本更优。
- 技术栈成熟稳定: 批处理技术(如SQL on Hadoop, MPP数据库)发展多年,生态成熟,工具丰富。
- 数据一致性和准确性易保障: 处理的是静态快照数据,更容易保证计算结果的精确性和一致性。
面临的挑战与局限:
- 结果滞后: 最大的缺点是无法提供即时洞察,分析结果反映的是过去某个时段的情况(T+1或更长)。
- 无法支持实时响应场景: 对于需要秒级响应的业务需求(如实时反欺诈)无能为力。
- 数据新鲜度依赖调度: 数据的“新度”取决于ETL/ELT数据抽取、转换、加载任务的调度频率。
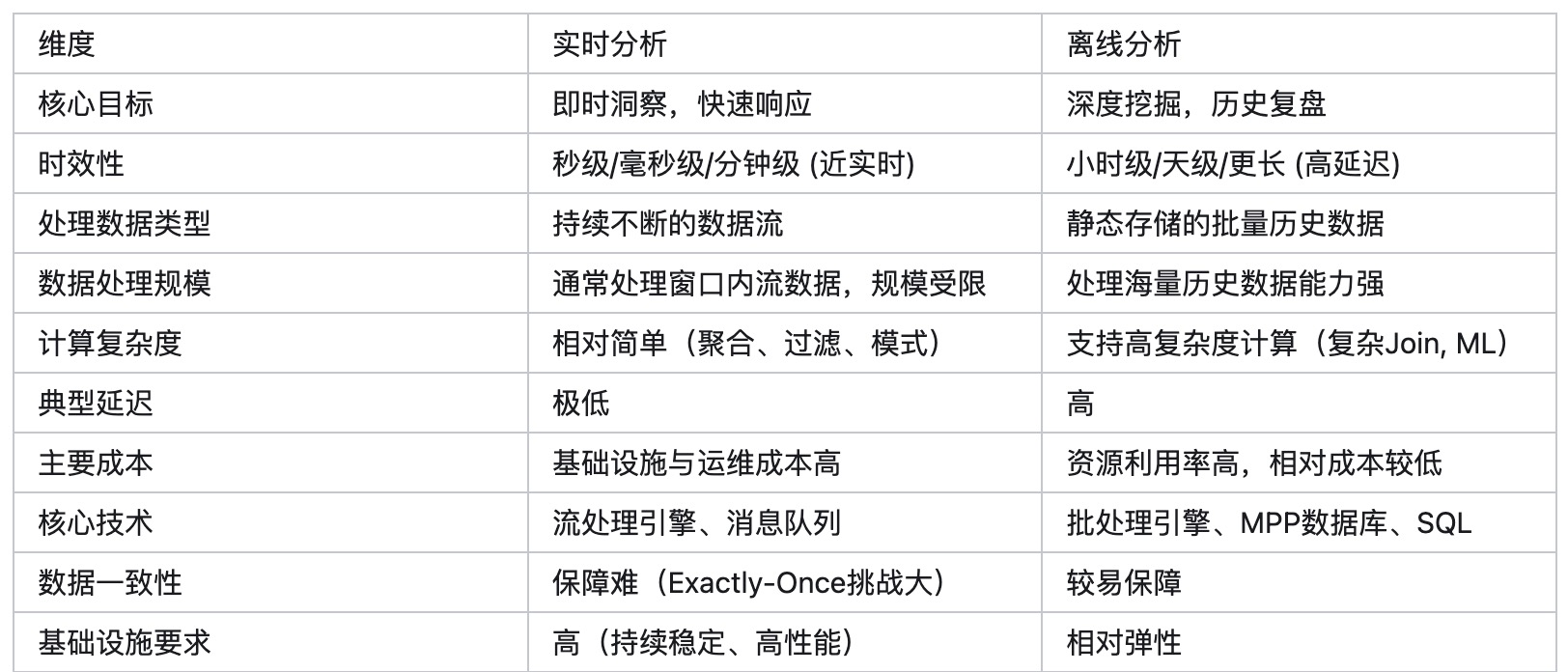
关键维度对比表:
如何选择?业务需求是根本
看到这里,你可能想问:那我到底该选哪个?答案是:没有绝对的好坏,只有最适合你当前业务需求的方案。 选择的关键在于深入理解你的业务场景:
时效性要求有多高?(核心问题)
业务决策或行动必须在秒级/分钟级内完成? -> 优先考虑实时分析。
业务可以接受小时级、天级甚至更长的延迟? -> 离线分析通常足够且更经济。
数据规模有多大?
需要分析的是持续不断涌入的流数据? -> 需要实时/流处理能力。
需要分析的是海量(TB/PB级)的历史存档数据? -> 批处理/离线分析引擎是强项。
分析任务有多复杂?
主要是简单计数、聚合、阈值告警? -> 实时分析可以胜任。
需要复杂的多表关联、深度数据挖掘、机器学习模型训练? -> 离线分析更合适。
预算与资源如何?
对成本敏感,且能接受延迟? -> 离线分析成本优势明显。
业务价值巨大,即时性带来的收益远超投入? -> 值得投资实时分析架构。
对数据一致性和准确性的要求?
要求极高的精确性和强一致性(如财务报告)? -> 离线分析更容易满足。
可以接受一定程度的近似结果或最终一致性(如实时大盘监控)? -> 实时分析更可行。
融合之道:混合架构
聪明的你可能已经发现,很多企业的需求是混合的:既需要实时监控关键业务指标并快速响应,也需要定期深度分析历史数据以优化长期策略。这催生了混合架构的流行,旨在结合两者的优势:
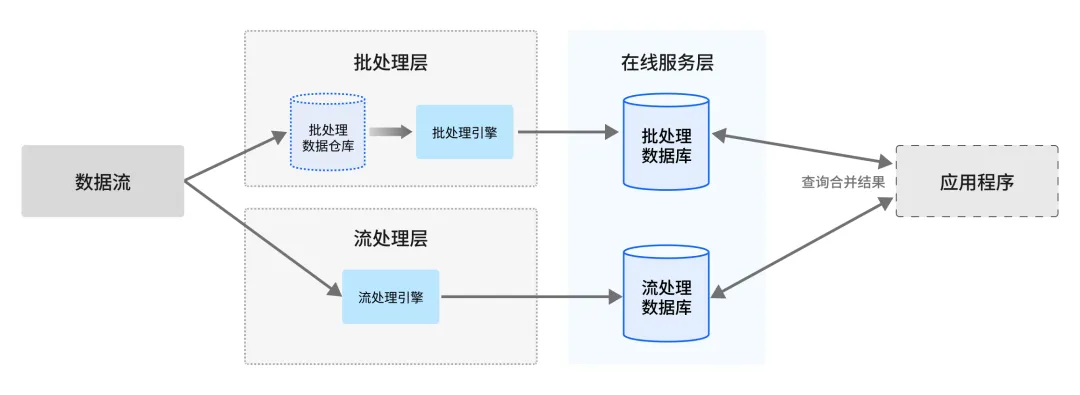
Lambda架构: 这是经典的混合模式。它同时维护两条数据处理路径:
- 速度层 (Speed Layer): 使用流处理技术处理实时数据,提供低延迟但可能近似的视图。
- 批处理层 (Batch Layer): 使用批处理技术处理所有历史数据,生成精确、完整的视图。
- 服务层 (Serving Layer): 合并速度层和批处理层的结果,提供最终查询服务。批处理层的结果会周期性地覆盖修正速度层可能存在的误差。
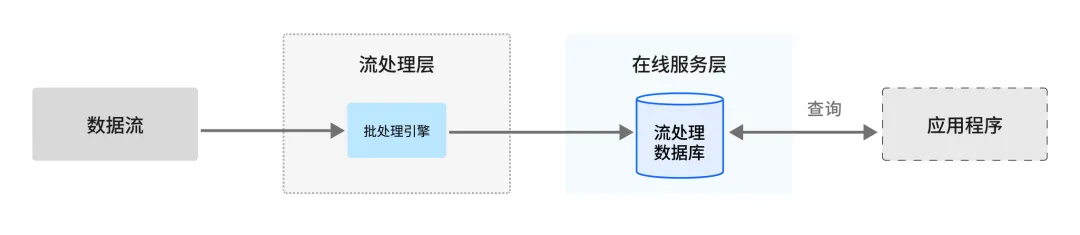
- Kappa架构: 可以看作是Lambda架构的简化版。它主张统一使用流处理来处理所有数据(无论是实时数据还是重新播放的历史数据)。通过将历史数据也视为流(从持久化存储中重放),简化了架构,但对流处理引擎的能力要求极高(需支持精确状态管理和高效重播)。
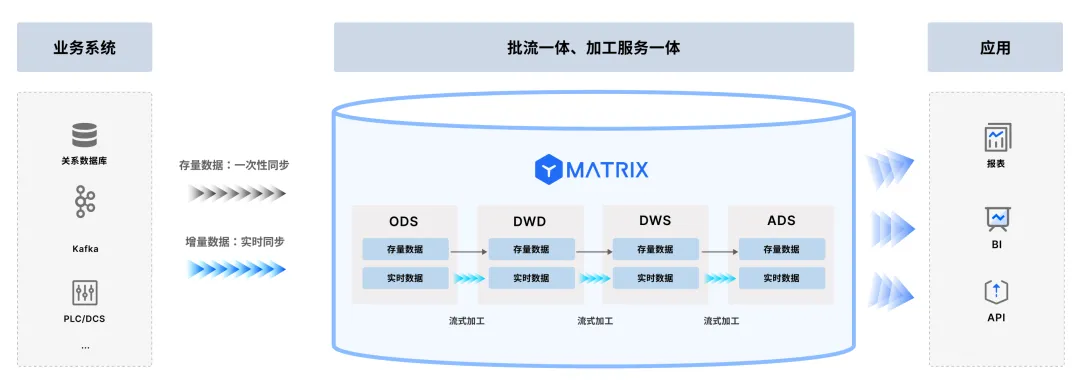
 现代的数据平台技术也在向流批一体 (Stream-Batch Unification) 方向发展,旨在提供统一的编程模型(如SQL)和底层执行引擎,能够同时处理实时流数据和历史批量数据,大大简化了混合架构的开发和运维复杂度。选择具备此类能力的平台,可以更灵活地应对多样化的分析需求。
现代的数据平台技术也在向流批一体 (Stream-Batch Unification) 方向发展,旨在提供统一的编程模型(如SQL)和底层执行引擎,能够同时处理实时流数据和历史批量数据,大大简化了混合架构的开发和运维复杂度。选择具备此类能力的平台,可以更灵活地应对多样化的分析需求。
结论
实时分析如同敏锐的“神经末梢”,让企业能够感知当下,快速反应,抓住转瞬即逝的机会或规避即时风险。离线分析则如同强大的“大脑”,专注于深度思考和长远规划,从历史中提炼智慧,优化整体策略。
它们并非相互取代的关系,而是数据分析拼图中不可或缺的两块。成功的现代数据架构,往往需要根据具体的业务场景,巧妙地组合运用实时分析和离线分析,甚至在可能的情况下利用流批一体技术来简化架构。
最终建议: 在规划数据分析方案时,回归业务本质,问清楚“我们需要多快知道答案?”以及“我们需要知道多深?”。答案自然会指引你选择离线分析、实时分析,或是结合两者的智慧之道。
欲了解更多相关信息,请访问“YMatrix超融合数据库”官方网站







