
理想汽车是造车新势力中的佼佼者,也是全车数字化的引领者。充满未来感的数字座舱吸引了无数用户的关注,而其背后同样也隐藏着一套庞大的数据体系,记录着车辆运行中的各种实时状态。这些规模庞大的数据被上传、汇总并实施多维分析,结果被利用于售后服务、业务运营及生产优化等方方面面,帮助理想汽车实现全方位的数字化驱动。
目前,理想汽车的数据基础平台承载了超 60 万辆车的车机数据,每日新增的数据规模超过 100 亿规模/天。同时,随着车辆规模的增长,监测指标的细化,整体数据规模仍在持续高速扩张,平台面临着性能、成本和运维的三重挑战。
理想汽车于 2021 第四季度开始接触 YMatrix 超融合数据库,经过严密的测试后,开始启用 YMatrix 集群承载车机上传数据及相关的查询分析业务,目前集群已稳健运行一年。YMatrix 为理想提供了一套高性能、低成本且高效易用的时序数据解决方案:支持海量高并发数据的分批、乱序写入,历经生产环境 6 亿点/秒写入考验,同时也能保证数据的一致性(ACID);支持秒级扩容,业务 0 中断,提供 PB 级数据存储能力,帮助平台从容应对业务数据的高速增长;在服务器用量减少 2/3 的情况下,不但数据入库延迟大幅降低,而且系统查询性能也显著提升;同时简化了技术架构,使业务指标的开发时间大幅压缩,有效提升了开发运维效率。
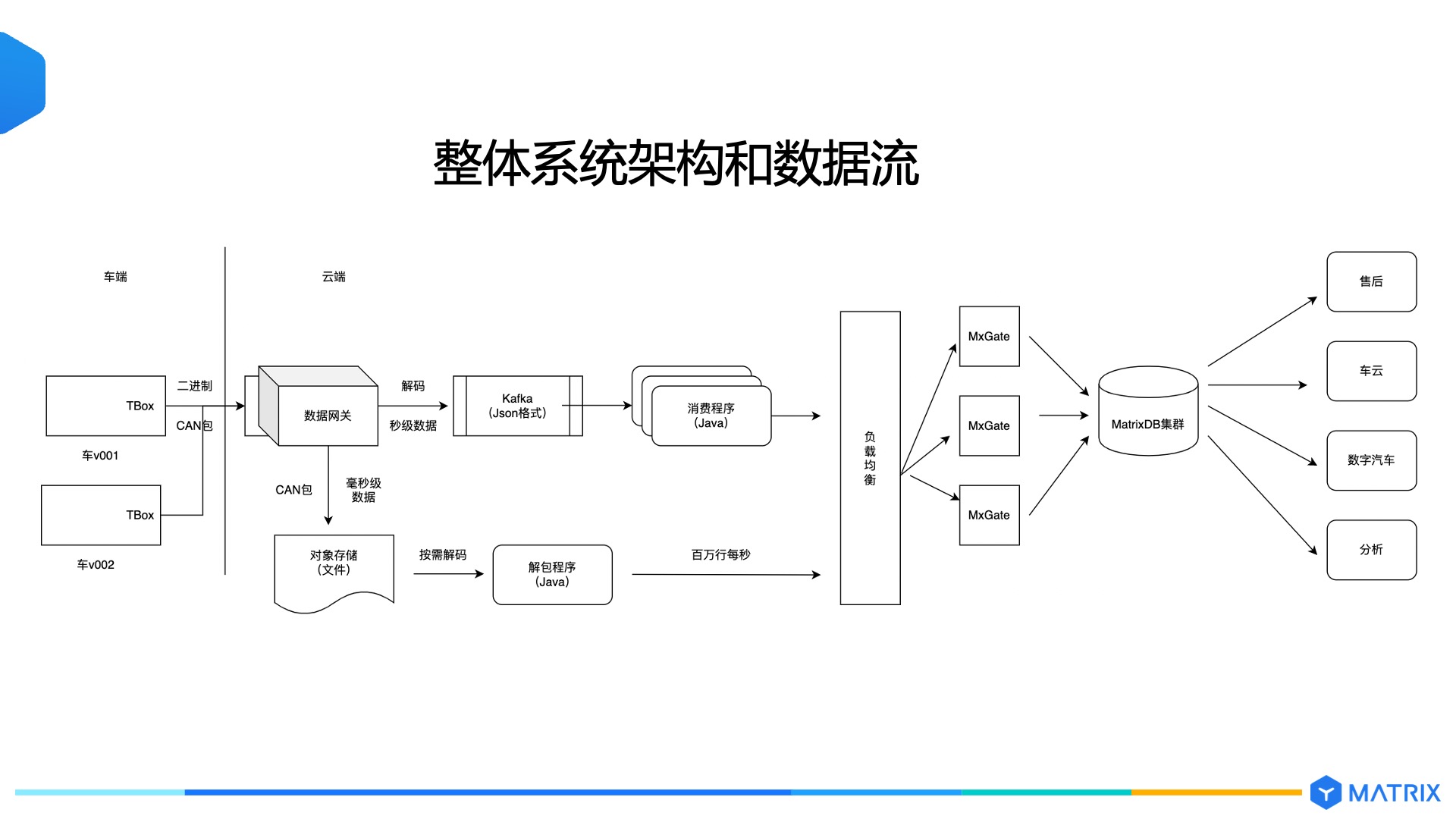
目前理想汽车在线运行的车辆超过 60 万,每辆理想汽车中都遍布有各种类型的传感器,监测超过 5000 多个车辆运行指标。这些指标,经由车内的 CAN 总线收集、统一时间戳、并汇总打包,最后通过移动网络 24 小时不间断地上传回云端数据平台。理论状态下所有数据会以时间序列有序上传,但真实的车辆运行环境十分复杂,当车辆会开进山区等移动信号无法覆盖的地区,车机数据的上报将中断,而一段时间后网络恢复,中断期间的数据需要补充上传,而且由于数据量比较大,采集频率不一样,有的数据需要分批上传。
可以看出,理想车机数据的写入十分复杂,面临着两大挑战:一方面是需要应对复杂的数据上传环境,平台端能够支持数据延迟、乱序、分批写入的情况;另一方面,相比一般 IoT 场景中单设备不超过 100 个监控指标的场景而言,理想单车单车超 5000 项指标,无疑将使数据规模指数级增长, 是真正的海量高并发写入场景,这需要数据库本身能具备极高的吞吐写入能力及稳定性。
YMatrix 超融合时序数据库在时序数据写入方面,为理想数据平台提供了如下特性:
基于以上特性,YMatrix 帮助理想数据平台,在真实的生产环境中经受住峰值 6 亿点/秒的超大规模写入考验,并将写入延迟从过去的 2 小时大幅压缩进 10 秒内,真正实现海量数据的随写随用。对比一般的时序场景(通常在每秒10 万点以内),这一写入规模超过了 1500 倍,可谓是时序写场景的巅峰,充分印证了 YMatrix 卓越的数据写入能力。
更进一步,得益于 YMatrix 强大的能力,平台帮助业务端实现了对毫秒级数据的分析能力。在业务侧,更细的时间粒度能够提供更精准的信息,从而更加准确的定位问题并进行分析归因,但对比日常使用的秒级数据,也意味着数据规模 1000 倍的提升。过去受制于 OpenTSDB 集群的写入瓶颈制约,毫秒级数据会产生业务端难以忍受的数据延时,而目前通过 YMatrix 则可以支持低延时的毫秒级数据入库,从而使毫秒级的数据分析业务真正落地。
理想基础数据平台面临的另一项挑战,是随着在线运行的车辆快速增长,数据量也将持续增长,同时来自业务端的查询需求也同步增长,平台始终面临着不断扩容的压力。依照目前的业务增速估算,每半年就需要进行一次扩容。除了产生直接的硬件投入,每次扩容都是一次复杂而痛苦的过程,还有可能对业务正常运行产生干扰。因此,在确保性能和功能的前提下,平台需要寻找更具经济性的集群构建方案,以及能最高限度保障业务连续运行的技术方案。
YMatrix 在承载同等规模数据的情况下,仅通过 14 节点集群就实现了对原有 50 节点 OpenTSDB 集群的替换,使集群服务器用量减少 2/3,首先在硬件投入上帮助平台实现了有效的成本控制。同时, YMatrix 超融合数据库提供了一套平滑扩容方案,在业务不中断的情况下,可以实现集群规模的平滑扩展,整个过程可完全通过 UI 可视化界面进行操作,为运维人员提供更加简便、直观、流程化的操作体验,扩容不再是意外不断的闯关之旅,而成为有章可循的 SOP (标准流程)。另外, YMatrix 也提供了超过 100 项的核心运维监控指标,覆盖写入性能、查询性能、集群状态等多个方面,为运维人员精准掌握平台运行状态,以及故障定位、归因分析提供了丰富的监控数据支撑。
平台原有的 OpenTSDB 不支持聚集查询、窗口查询等复杂时序查询,因此类似的复杂查询需要通过在 Hive 及 Flink 集群中独立编程来实现,代码开发具有一定的技术门槛,后期的维护成本也较高。YMatrix 则原生支持全面的时序场景查询功能,如聚集查询、窗口函数、跳变查询、差值查询等等等,业务开发人员可通过标准的 SQL 语言就可以直接通过 YMatrix 获得查询结果,指标开发时间从原来的几天,大幅缩减到 1 小时以内。 同时,YMatrix 也使查询性能得到大幅提升,如单个指标明细查询等常用查询,耗时缩减至 1 秒内,最大降幅超过 90%。
“面对海量数据、复杂的网络环境及严苛的性能要求,YMatrix 稳定支撑了我们的车机信号采集处理业务:在服务器用量减少 2/3 的情况下,不但数据入库延迟大幅降低,而且系统查询性能也显著提升。” 理想汽车基础平台负责人聂磊如是说。
面向未来,理想技术数据平台希望能进一步发挥 YMatrix 的超融合特性,开发利用 YMatrix 的 OLAP 能力,完成对 Hive 数仓的替换,从技术角度进一步简化平台架构,从业务角度实现时序数据与其他类型的融通管理,助力更加深入的数据价值探索。






