_1750669132.png?x-oss-process=image/resize,h_300/format,webp/quality,q_80)
实时数据仓库的建设不存在普适方案,需根据业务场景的核心诉求进行架构设计。实践中,企业对实时性的需求可明确划分为两类:高时效性优先与高一致性优先。这两类需求如同天平的两端,过度倾斜任何一方都将导致架构失衡。
金融反欺诈、物联网设备监控等场景要求响应延迟严格控制在200ms以内。此类架构必须极致轻量化:
数据通道精简:源端日志通过Kafka等消息队列直连计算层,跳过传统ODS层缓冲,减少序列化开销。某银行信用卡风控系统采用此模式,从交易发生到风险判定仅需150ms。
计算逻辑简化:在Flink等流处理引擎中仅执行基础聚合(如滑动窗口计数、阈值判断),结果直接写入Redis或内存数据库。例如电网监控系统对千万级传感器数据仅保留最近5分钟均值,异常检测延迟控制在200ms内。
服务层预计算:指标预先聚合后直供前端查询,避免即时计算开销。但代价是牺牲深度分析能力——复杂关联查询需异步转移到离线链路补全。
这种架构的本质是用精度换速度。某证券交易系统为达到毫秒级风控响应,仅对持仓量、价格波动等核心指标进行实时计算,而客户画像分析等任务则延迟至批处理执行。 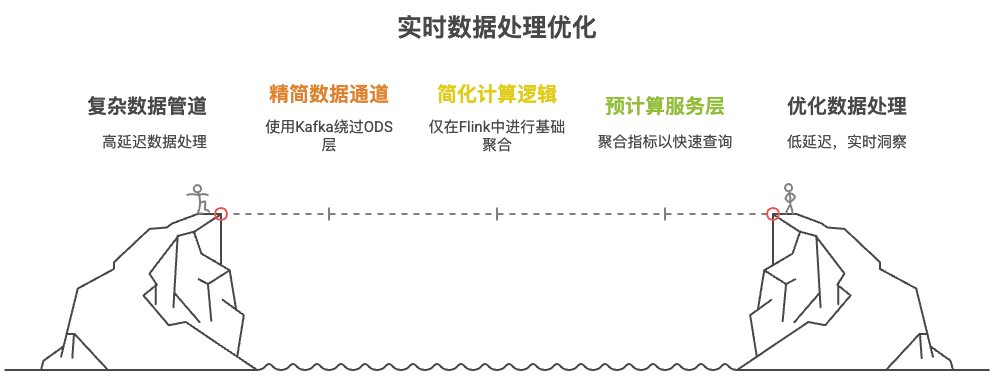
财务结算、用户画像等场景要求数据100%准确,技术方案需聚焦精准性保障:
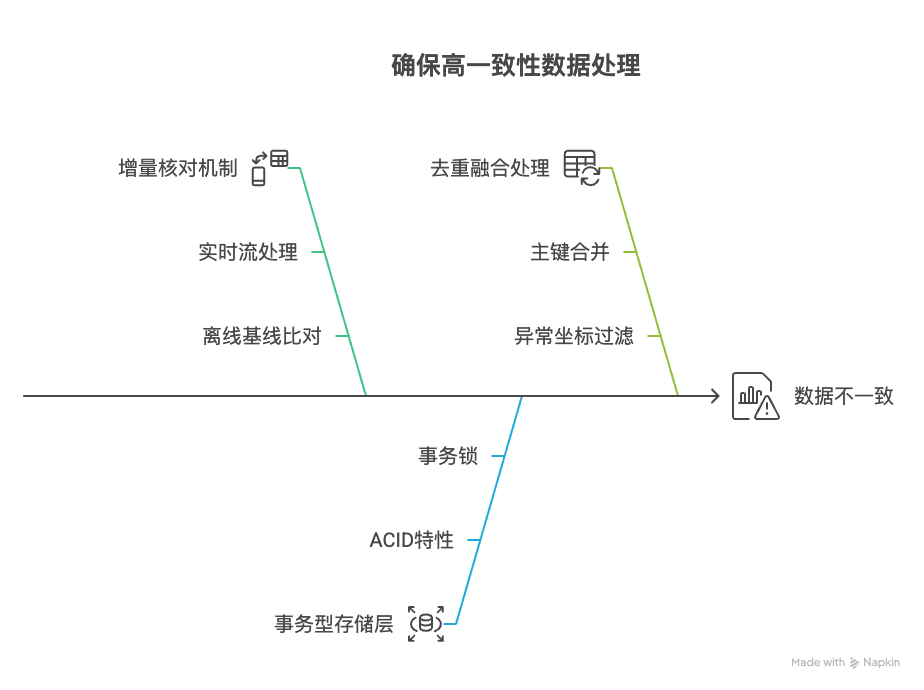
不同业务需针对性设计架构,关键决策依据如下:
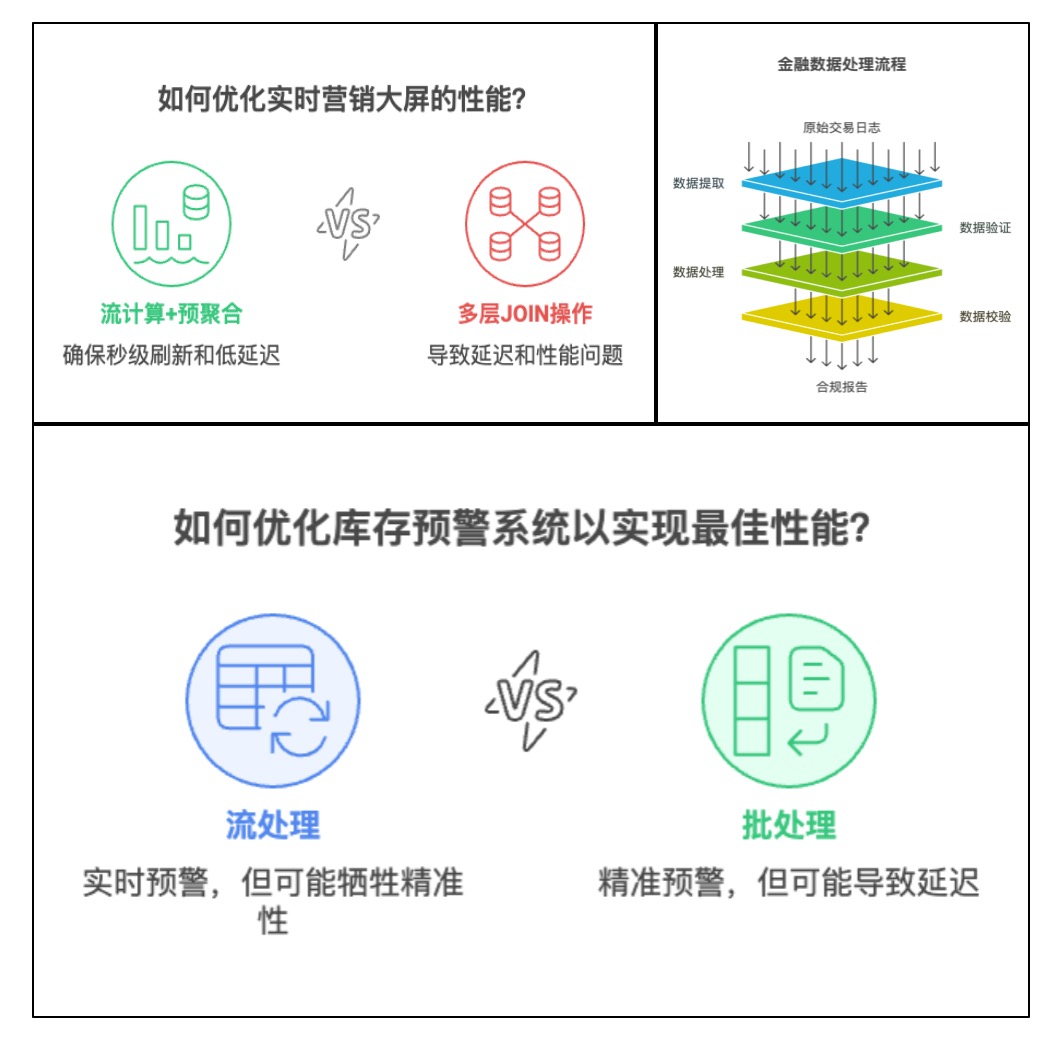
实时营销大屏:核心需求是秒级刷新,采用流计算+预聚合方案,避免多层JOIN操作。某电商大促期间,通过直接读取预计算的GMV指标,看板延迟稳定在1秒内。
监管合规报表:强一致性与可追溯性优先,以批处理为主框架,流计算仅辅助数据校验。金融机构需建立完整的数据血缘链条,确保每笔交易可回溯至原始日志。
库存预警系统:需平衡分钟级延迟与精准性,采用流批一体架构配合事务更新。仓库管理系统为库存变动设置行级锁,防止超卖同时将预警延迟压缩至20秒。
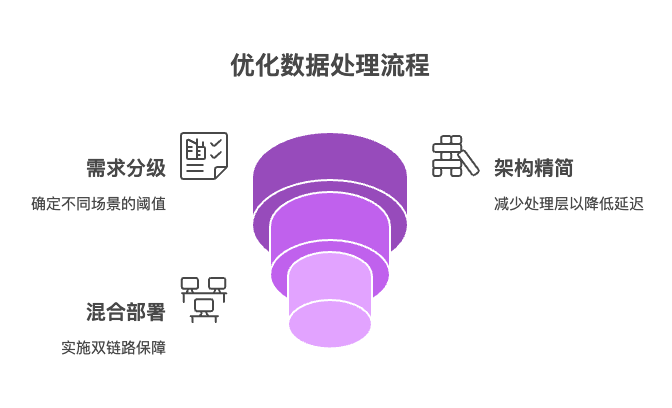
需求分级量化:明确各场景可容忍的延迟阈值(如风控≤200ms,报表≤5分钟)与误差范围(如结算系统误差率<0.01%)。
架构层级精简:高时效场景最多保留三层(接入层→处理层→服务层),剔除非必要的ETL步骤。某车联网平台将数据处理层级从5层压缩至3层,延迟降低40%。
混合部署策略:关键业务采用双链路保障。例如支付系统同时部署实时风控引擎(处理盗刷)与离线对账模块(修正资金差错),两者通过统一存储层交换数据。
本质规律:时效性与一致性存在天然矛盾——
最终决策应回归业务价值:实时数仓不是技术竞赛场,而是支撑商业决策的基础设施。当架构设计与业务目标对齐时,才能在速度与精准的天平上找到最优支点。






