
据 EV-volumes 统计显示,2021 年全球电动汽车销量达到 675 万辆,电动汽车在全球轻型汽车销售中的全球份额为 8.3%,而 2020 年这个数字仅为为 4.2%。由于疫情的爆发,全球汽车市场在2021年仅增长了 4.7%,但是电动车的市场依然保持了高增长,增长幅度达到了 108%。

世界汽车行业正在经历前所未有的大变局。汽车正由原本的交通工具转变成链接各个生态的移动终端。德勤分析认为,一个智能化产品的价值与用户在其中投入的时间有着密不可分的联系。在不远的未来,随着智能驾驶的落地,用户在车内的出行时间将被解放出来。因此智能网联汽车也将成为下一个被争夺的焦点。在此驱动下,各大车企纷纷开始着手智能化战略的部署。
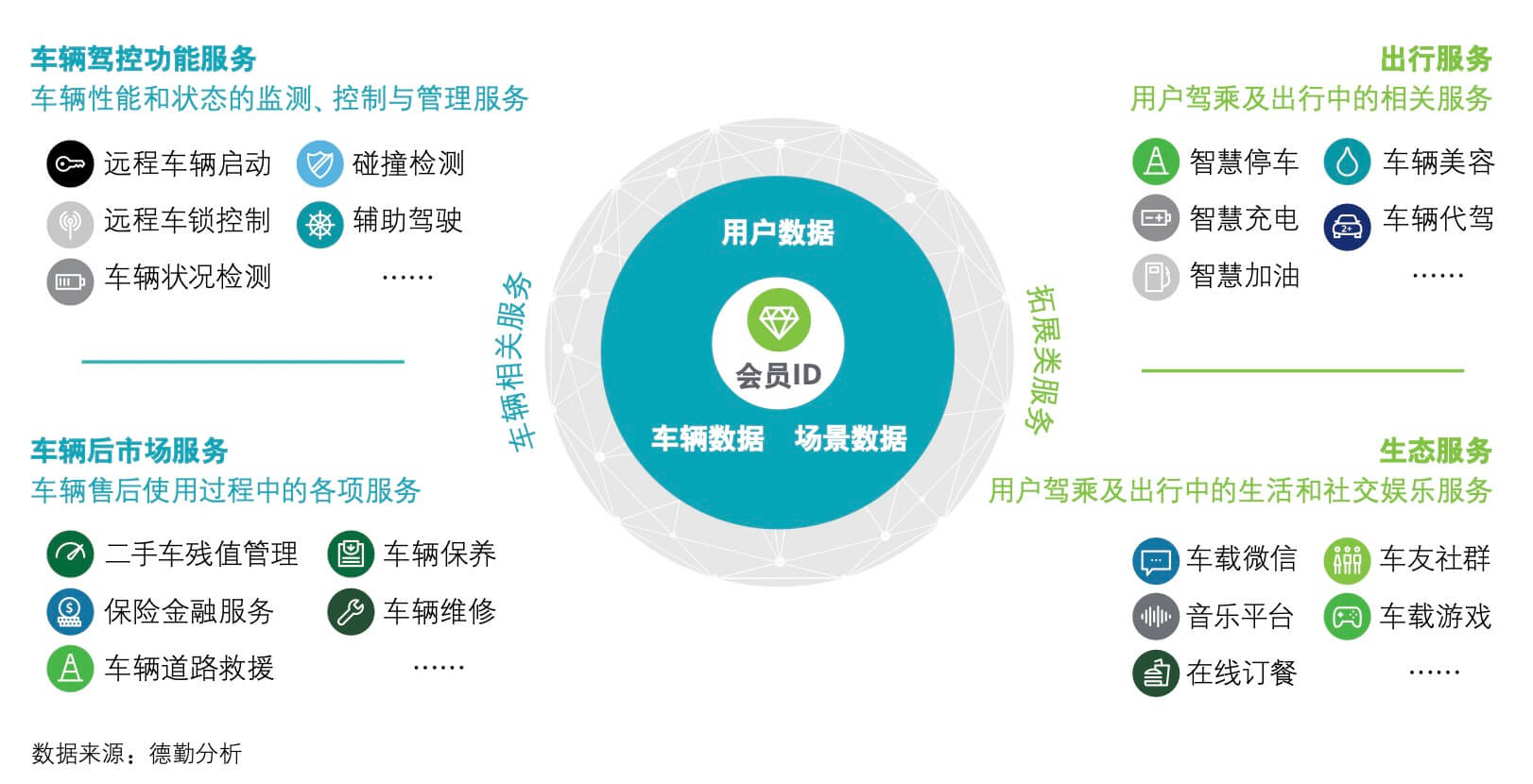
就像数字化是智能化的前提一样。实现车辆的智能化是目的,而车辆的网联化是前提与核心手段。不管是智能交互、智能驾驶还是智能服务,都离不开对车辆本身的运行数据与用户行为数据的分析与学习。车辆数据已经成为车企的核心资产,通过数据的采集、存储、分析来支撑从售前、售后、故障分析到产品研发、数字汽车、自动驾驶等全公司核心业务,业务的每一个环节都可以看到数据驱动。
现有的工业大数据解决方案源自于互联网行业。数据相比于传统的互联网更加集中,密度更大、应用场景也更广,因此涉及到的技术栈也更多。

典型的车辆网通过类似上图的基于 Hadoop 的架构来处理和分析数据规模最大的车机信号数据,通过 Redis 保存每辆车的最新状态并支持高并发查询、使用 OpenTSDB 存储信号并提供明细查询,使用 Flink/Spark 进行实时告警和计算,对于分析场景使用 Hive/HDFS 存储数据并关联分析,实时计算和离线分析的结果再存入 MySQL/PostgreSQL 给业务使用。 客户在使用以上架构时面临如下挑战:
复杂的技术栈需要资深的大数据专家,而大数据专家在市场上是稀缺人才,不仅费用高昂,而且难以招募到高级人才。很多时候招募到合适的人才,培养半年后被高薪挖走。
对于每一条记录,需要从 Kafka 中重复消费、存储和处理。每种存储都需要单独的一份消费解析实例, 每天几十亿的数据规模,一份消费实例就对应着 10 多个虚拟机的计算资源。消费后, 数据在 OpenTSDB 中保存一份,HDFS/Hive 中保存一份。在每天增量数据压缩后也到TB级别的情况下,多保存一份就意味着增加大量的成本。
在当前的架构下,几乎所有的实时计算部分都需要写 Spark 或者 Flink 程序完成,业务创新日新月异,对实时计算的需求难以快速响应,与此同时,需要数据支撑部门投入人力开发、优化和维护这样的程序,人力成本高,开发周期长。
车辆数据有明显的高峰和低谷, OpenTSDB 等系统数据入库效率低吞吐小,如果按照高峰期规划系统资源,将造成极大的浪费;如果按照平均吞吐部署,则高峰期数据延迟明显,通常会延迟 1-2 个小时,需要借助晚上数据低谷期将数据补回来。同时,查询效率低,尤其在业务需要的大范围信号提取上响应可达分钟级,不得不从 API 层限制数据访问的提取时间范围在 30分钟或者 1小时内。
受限于实时计算的特性和系统资源限制,许多业务尤其是业务看板,只能通过离线计算的方式进行, 而离线方式只能在晚上通过批处理的方式针对前一天的数据进行计算。业务部门和车主无法得到当天或者最新的统计数据,极大的影响了业务推进和客户体验。
Hadoop 产品对于系统资源的粗放使用,导致同样的数据量类似的计算需要数倍的计算资源,数据的重复处理和存放让机器资源再次翻倍。随着汽车保有量的增加,需要持续不断的扩容所有集群,使得车企不堪重负。
为支持一个业务,需要在不同数据库产品间倒腾数据,开发接口,无形中增加很多开发和维护的成本,也对开发和运维人员增加了门槛和麻烦,进而减少了他们在核心业务上的投入时间。
YMatrix 超融合数据库基于 PostgreSQL 与 Greenplum,支持标准 SQL 语言,同时针对时序数据的高效存储和高性能查询要求实现了突破性的优化。在分析能力上,用户可以通过持续聚集功能预先定义物化视图、固定和滑动窗口等方式来完成实时计算,通过事务保障入库的同时完成计算过程,既免去了轮询式计算的资源开销,又保障了实时计算的正确性和一致性。通过对数据的订阅发布与事件的推送,也能满足触发式的场景需求。比如非空最新值的计算,可以通过数据库内置的 last_not_null 函数和自动持续聚集实现,报警、实时计算等可以通过简单的 SQL 快速实现,而不需要开发和维护代码。 基于 YMatrix 的丰富特性和强大性能,用户仅需要一个数据库就可以支撑车联网,数据一次消费一份存储, 适应现在的已有需求和快速响应新增需求。YMatrix 丰富的特性减少了开发人员的工作量, YMatrix 的高性能分析特性,也让许多不可能变为现实,例如大范围的明细数据提取以及实时的看板,在其他架构中不易实现,而在 YMatrix 中可以提供给业务部门使用。
架构的简单并不意味着功能会打折扣。YMatrix 将复杂留给数据库开发人员,让用户可以更专注于自身业务的搭建。下图是一个围绕 YMatrix 搭建大数据平台的典型功能结构。
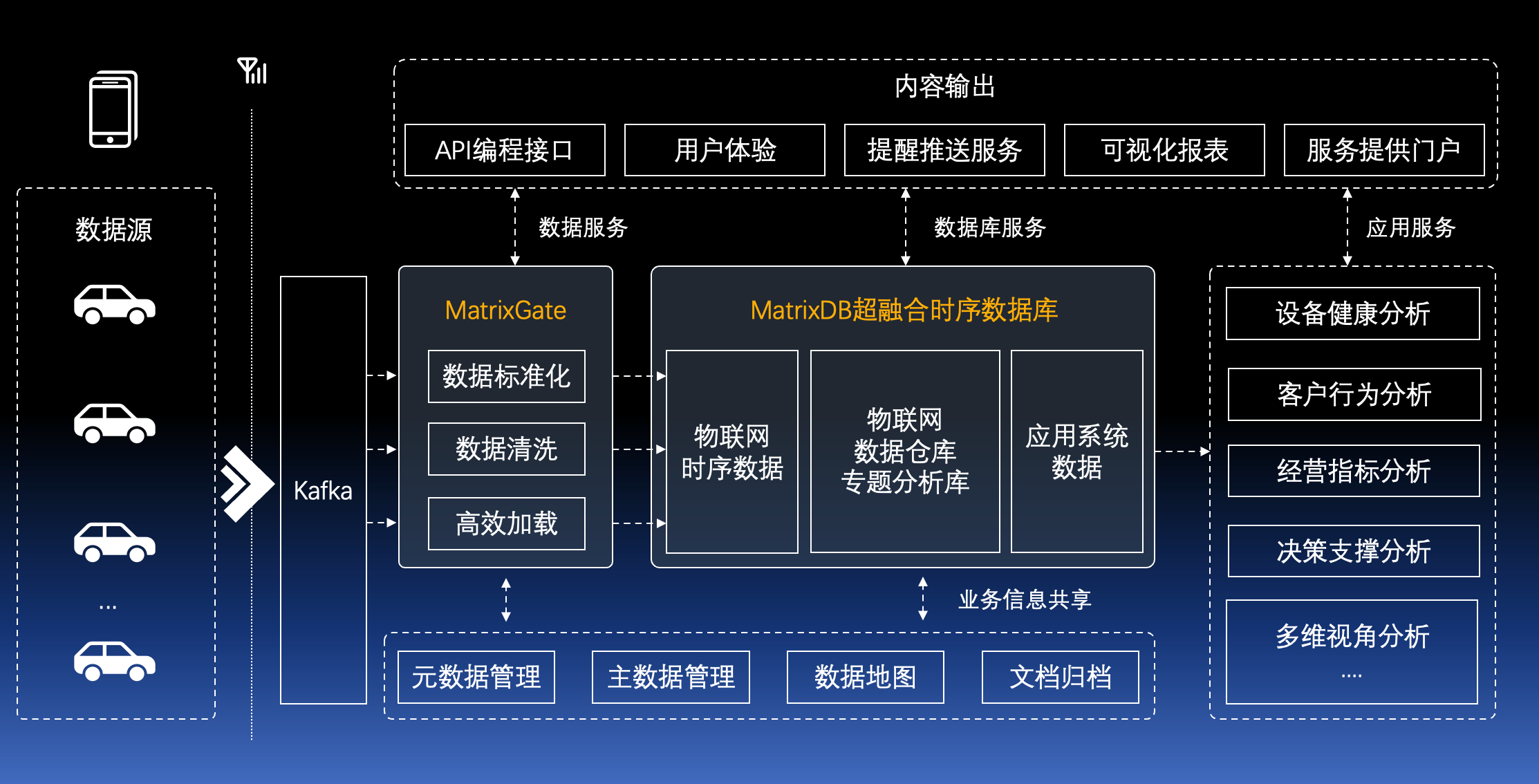
通过大幅减少消费、存储和计算部分,进而减少机器成本; 通过快速 SQL 替代自行开发的功能,减少开发人员的负担;开发和运维人员的学习成本也极低
相比于原本大幅减少了不需要的组件,系统架构简单稳定,运维难度大大降低。架构简洁,懂 SQL 就可以搞定大数据。
传统大数据架构中数据需要在不同的组件间传递,这会带来额外的损耗,数据的高峰到来时往往会引起数据延迟。MatrixGate 可以提供持续稳定的数据高速传输通路,将数据批量高效的整合成 MatrixDB 最适应落盘的格式,进而达到零延迟入库的使用体验。
MatrixDB 可以在数据接入层、计算层和存储层提供内置的高可用,任意环节都有多实例和多副本机制,任意节点和软件故障不影响集群使用。在接入层,可以在多台机器启动多个 MatrixGate 实例,搭配负载均衡,可以承接海量数据的高速实时入库;在计算和存储层,主节点和数据节点都内置基于事务日志流式复制的高可用机制。
针对时序数据特征而设计的自动排序和行列混合存储, 在明细和聚合查询时可以最小化存储 IO 开销,结合分块数据裁剪、并行计算、JIT 等计算加速技术,YMatrix 可以提供极低延迟和极高并发的查询性能,
MatrixDB 的高性能计算和线性扩展特性,可以帮助用户实现实时和离线计算的一体化,将实时数据和离线数据只存一份、存储在一个数据库中,无论是实时计算还是离线计算,都可以通过功能丰富的 SQL 快速高效的实现,极大的提升效率和节省成本。
某造车新势力从 2021年11月起大规模测试 YMatrix,接入实际线上数据,并通过模拟翻倍等方式压测数据接入、明细查询、跳变查询、非空最新值、实时和离线分析等特性,对 YMatrix 的高性能和稳定性赞誉有加。 在生产环境,约14 万辆车,平日每天 60亿条数据、压缩后 1.2TB,节假日可以增加到每日 2TB。 15 台服务器的 YMatrix 集群可以支撑原来下列节点的作用并提供更好的性能:
借助于 MatrixDB 的强大功能,用户也开启了很多新特性给业务使用:
大范围信号探索: 此前只能开放售后 30分钟到 1小时小范围时间段的信号探索查询,并限制信号数量在 50 以下,导致售后在使用时,需要反复多次调用后台服务,浪费大量时间;现在可以开放多达一天300个信号的探索查询,并保持在毫秒级响应。 欢迎业务创新: 此前无法满足业务的创新速度,而不得不拒绝或者延迟很多实时计算的需求,现在可以通过SQL实现快速响应业务创新。
“只有MatrixDB可以做到” --- 用户评价
属于智能网联汽车的未来即将到来。车企在规划转型方向与业务定位的同时,也要从实现技术角度深入思考。基于互联网行业经验的传统大数据架构无法很好的承载未来海量时序数据的分析与处理。选择更合适的工具,让专业的人干专业的事,才能在激烈的竞争中占得先机。






