
在 PostgreSQL 的发展过程中,执行器一直是其核心组件之一,它直接影响到数据库的查询性能。随着越来越多的数据分析任务被引入到数据库中,如何提升执行器的性能,成为了 PostgreSQL 社区持续关注的主题。
去年,Amit Langote 在 PGConf India 2025 上的分享《Hacking Postgres Executor For Performance》中,深入探讨了 PostgreSQL 执行器优化的思路与实践。在这篇分享中,他介绍了 PostgreSQL 标准执行器的一些不足,以及如何通过改进执行模型来提升数据库在分析型工作负载下的性能。
PostgreSQL 的可扩展性一直是它最重要的优势之一。过去我们经常谈数据类型扩展、索引访问方法、FDW、插件、Hook 等能力。最近笔者在 PGConf 上分享了一篇关于 YMatrix mxvector 的主题 —— How to implement high performance pluggable vectorized executor,在这次分享中,我想分享的是 PostgreSQL 的扩展能力,不只可以扩展功能,也可以支撑执行模型的演进。mxvector 正是在这个方向上的一次实践,在不重写 PostgreSQL 执行器的前提下,构建一条更适合 OLAP / HTAP 场景的分析型执行路径。
PostgreSQL 的执行器采用的是一种经典的 tuple-at-a-time 模型 (逐行处理),可以把它理解成一种“父节点向子节点不断要下一条数据”的模型。每个节点都像一个迭代器,父节点调用子节点的 next(),一条一条地把数据拉上来。这种模型在 OLTP 场景下表现非常好,可以高效处理点查、事务处理等工作负载。在执行过程中,数据库会按顺序处理每一条数据记录,逐个执行相应的计算、过滤、投影等操作。但是,当工作负载转向 OLAP 或 HTAP 场景时,逐行处理的方式显得不够高效,特别是在需要处理大量数据的查询中,每一条数据的处理都会带来显著的性能损耗。
在处理分析型查询时,PostgreSQL 标准执行器会经历大量的操作,比如提取数据、函数调用、数据类型转换等步骤。这些步骤虽然在单条记录的处理过程中看似开销不大,但随着查询数据量的增加,它们的累计开销会变得相当庞大,导致查询效率大幅下降。
让我们看个简单例子,比如想计算 c1 < 10 这样的过滤条件计算,标准执行器会经历如下流程:
扫描算子从存储中加载一行,数据以 heap tuple 这样的序列化格式存储;
从 heap tuple 中提取出 c1 的值,转换成 datum 类型,将其填充进函数调用上下文结构体中的参数表,并调用指向 C 函数 int4lt() 的函数指针来完成比较;
然后将 bool 类型的比较结果转换成 datum 泛型并返回;
返回到扫描算子后,其把返回值从 datum 泛型格式转换回 bool 格式,从而得知过滤条件是否满足。
伪代码如下:

可以看到,即便是一条简单的比较运算,一条 CPU 指令即可完成,然而在执行这一条指令的前后则进行了大量额外的操作,相较于真正的比较指令,这些外围操作可能占据更主要的成本,甚至达到数倍到数十倍的量级,当这样的流程被重复几百万、几千万次时,就会显著影响分析型查询的吞吐。
那么为什么向量化执行器可以大幅提升性能呢?让我们看一个形象的例子,假设现在我们要分拣出所有重量超过 200 克的苹果。
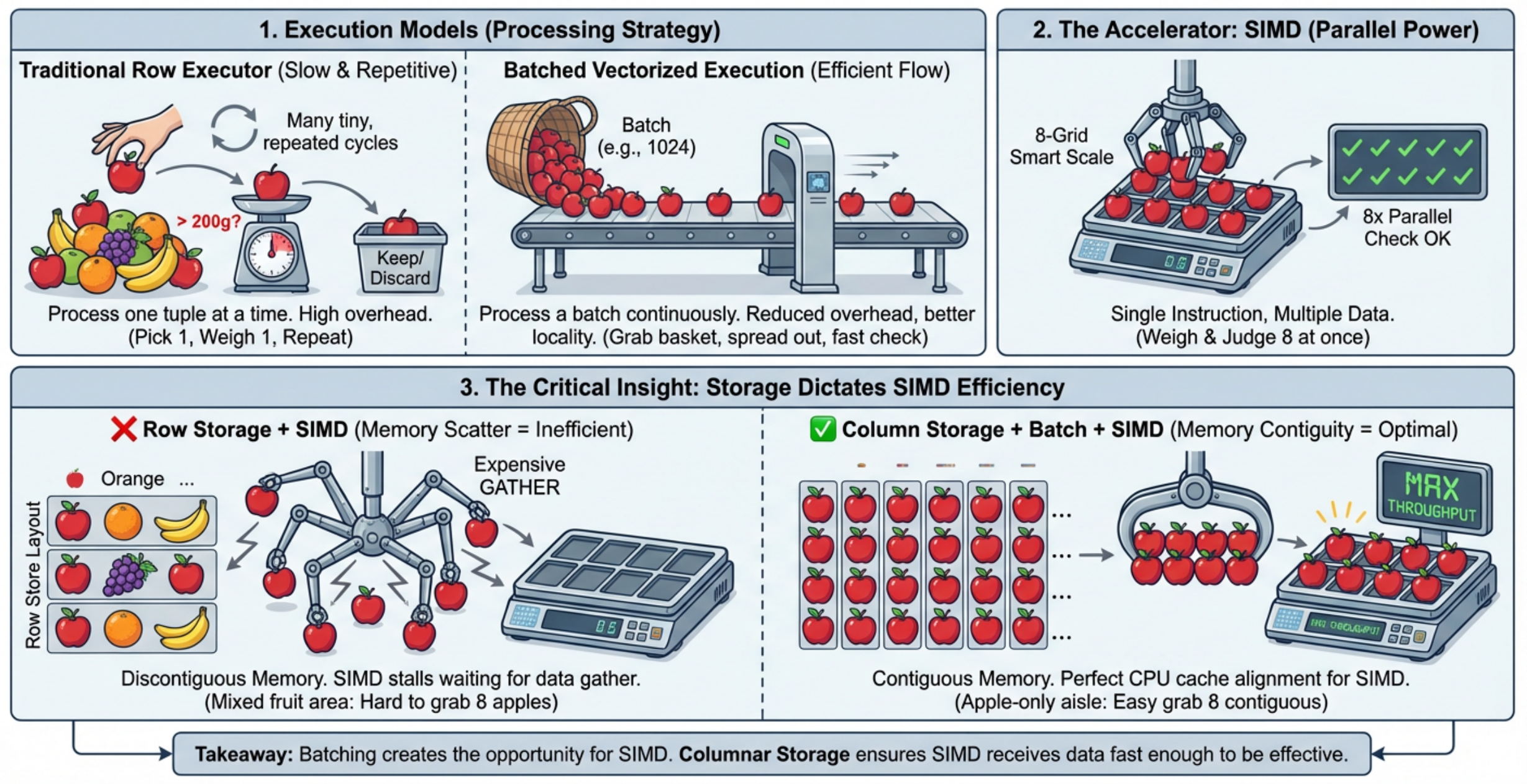
在传统执行模型下,对应的做法就像是:每次拿起一个苹果,称一下重量,判断是否超过 200 克,然后放下,再拿起下一个苹果,不断重复,直到完成所有分拣任务。
这个流程当然可以完成工作,但问题也很明显:每处理一个苹果,都要重复一次“拿起、称重、判断、放下”的完整流程。如果只有几个苹果,这种方式没什么问题;但如果有几百万个苹果,这些重复动作本身就会变成巨大的开销。
于是,我们自然会想到第一步改进:能不能不要一次只处理一个,而是一次处理一批?
假设现在我们有一个篮子,一次可以拿起一篮苹果,比如 100 个。这样一来,处理流程就发生了变化:我们不再围绕单个苹果反复启动一套动作,而是把一批苹果集中起来连续处理。这样带来的好处很直接:原本每个苹果都要重复承担的“拿起 / 放下”等固定开销,现在可以被一整批苹果共同分摊。这对应到数据库中,就是批量化处理。它的核心价值不是简单地多拿了一些数据,而是把执行粒度从一条记录一次变成一批记录一次,从而减少大量重复的函数调用、状态切换和数据转换开销。
但批量化之后,我们还可以继续追问:既然苹果已经是一批一批地来了,能不能一次称多个苹果,而不是仍然一个一个称?这就引出了第二步改进:SIMD。
假设现在我们拥有一台特殊的秤,它一次可以同时称 8 个苹果的重量。这样我们就不需要对这 8 个苹果分别称 8 次,而是一次称重,直接得到 8 个结果。这正是 SIMD 想表达的核心思想 —— 一条指令,同时处理多个数据。对应到数据库中,如果我们已经拿到了一批同类型的数据,比如一批 int32 数值,那么 CPU 就有机会通过 SIMD 指令一次处理多个元素,而不是一个一个做标量计算。
不过,到这里还有一个关键问题:批量处理和 SIMD 并不会凭空发生,它们需要数据本身足够规整。
这就引出了第三个关键点:存储布局。
在图的左下角可以看到,如果水果是杂乱无章存放的,比如苹果、橙子、香蕉、苹果、橙子、葡萄……混在一起,那么即使我们有一台可以一次称 8 个苹果的秤,也很难直接发挥作用。因为在称重之前,我们还得先从一堆混杂水果里把苹果一个个挑出来。
这就类似数据库中的行存布局:一行中包含多个列,查询如果只关心某一列,也往往需要先从整行数据中把目标列提取出来。这个过程会带来额外的数据访问和解码成本。
相反,如果所有苹果都整齐地放在一起,我们就可以很自然地一次拿起一批苹果,并直接交给那台秤处理。对应到数据库中,这就是列存的重要性。在列式存储中,同一列的数据连续存放。这样有几个好处:
查询只需要读取真正关心的列,减少不必要的 I/O;
同类型数据连续存放,更容易获得较好的压缩效果;
连续的数据更有利于 CPU cache;
数据天然接近数组形式,更适合批量处理和 SIMD 计算。
所以,列存、批量化和 SIMD 并不是三个孤立的概念,而是一条逐步增强的链路:列存让数据更连续,批量化让执行更规整,SIMD 让 CPU 一次处理多个值。换句话说,批量化创造了使用 SIMD 的机会,而列存让 SIMD 更容易真正发挥效果。
现在,让我们小结一下:向量化执行器的核心思路,是将数据处理单元从“逐行处理”转换为“批量处理”,并尽可能让数据访问和计算过程都变得更加连续、规整、CPU 友好。具体来说,它主要依赖三个关键能力:
列存储:数据按列而不是按行存储。查询时可以只读取需要的列,减少不必要的数据加载,同时提升压缩率和缓存友好性。
批量化处理:一次处理一批数据,而不是一条记录一条记录处理。这样可以减少重复的函数调用、状态切换和数据转换开销。
SIMD 加速:当数据已经连续、同类型、批量化之后,CPU 就可以使用 SIMD 指令一次处理多个数据单元,进一步提升计算吞吐。
这些改变不仅减少了每条记录上的重复处理开销,也让数据访问和计算路径更加适合现代 CPU,从而提升分析型查询的整体执行效率。
理解了向量化执行的价值之后,下一个问题是如何实现?大体有三种路线。
直接修改标准 executor:这种方式看起来最统一,但风险很高。PostgreSQL 标准 executor 是一个非常成熟、复杂且通用的系统。直接修改它来支持向量化,侵入性强,会影响 OLTP 行为,很难保证所有 SQL 场景都不受影响,尤其是 PostgreSQL 的传统 executor 对 OLTP 场景非常重要,我们不希望为了分析型性能破坏它原有的优势。
在内部新增一套 executor:理论上可以在 PostgreSQL core 里再做一套 vectorized executor。但这会引入另一个问题:架构复杂,与现有的 executor 的边界难定义,其次 planner / executor / expression / storage 都要处理两套逻辑,后续维护成本高,这对于 PostgreSQL 这样强调稳定性和扩展性的系统来说,这条路也不够理想。
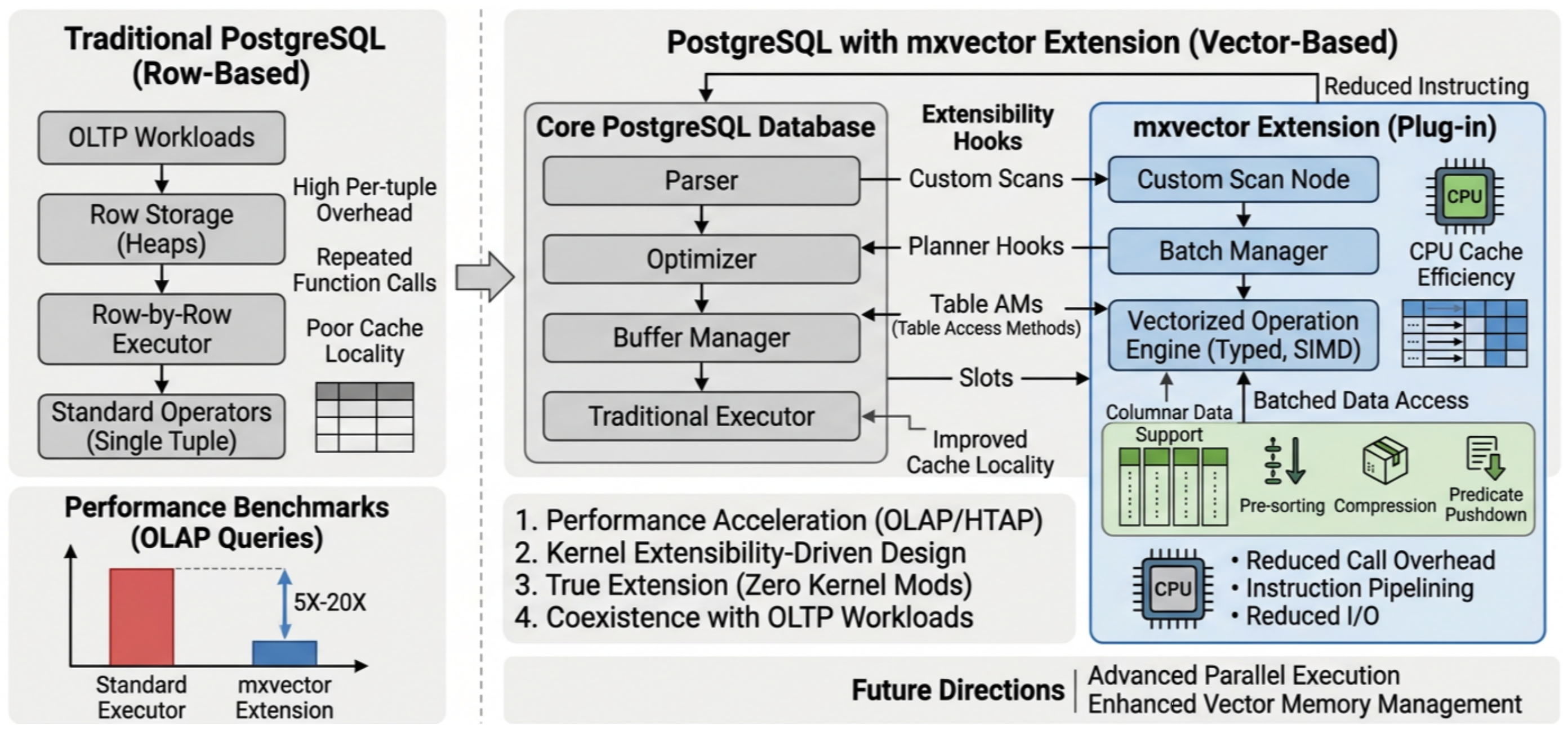
第三种便是构建可插拔的 vectorized executor,这也正是 mxvector 选择的路径。其优势是:低侵入,按需启用,更容易与传统 executor 共存,并且便于迭代和维护,不会破坏 PostgreSQL 原有 OLTP 优势。对于 PostgreSQL 来说,pluggability 不只是工程上的优雅选择,更是现实可行的架构选择。
简而言之,我们不希望为了让 PostgreSQL 更擅长分析,就破坏它原本最擅长的 OLTP。
可插拔设计:mxvector 作为一个插件加载,可以和 PostgreSQL 现有的执行器共存。这样可以在分析型工作负载下启用向量化执行,而在 OLTP 场景下依然使用传统执行器。
利用 PostgreSQL 扩展性:mxvector 基于 PostgreSQL 的扩展机制 (如 Hook、CustomScan、AM adapter 等)实现,无需改动 PostgreSQL 核心代码。
与传统执行器兼容:当向量化执行不可用时,mxvector 会回退到标准的标量执行器,确保查询能够正确执行。
mxvector 的实现主要依赖于以下几个关键技术。
PostgreSQL 的执行计划由各种 executor node 组成,比如 SeqScan、Sort、Agg 等,mxvector 需要自己的向量化版本,比如 VScan、VSort、VHashJoin 等,那么这些节点如何合法进入 PostgreSQL 的 plan tree?答案便是 CustomScan,CustomScan 提供了一种自定义执行节点机制,使扩展可以把自己的节点挂到 PostgreSQL 的计划树和执行器框架中。
VPlanner 负责计划层面的转换。例如 PostgreSQL 原本生成:
Limit
-> Sort
-> Seq Scanmxvector 会在每个 scalar node 上方叠加对应的 vectorized node,形成类似结构:
VLimit
-> Limit
-> VSort
-> Sort
-> VScan
-> Seq Scan这里 scalar nodes 被称为 shadow nodes。这些 shadow nodes 并不会真正执行,但保留了原始计划中的语义信息和执行细节。例如:
VLimit 从 Limit shadow 中获取 OFFSET / LIMIT
VSort 从 Sort shadow 中获取排序键
VScan 从 SeqScan shadow 中获取扫描相关信息
这种设计非常关键,可以避免 mxvector 重新实现所有 plan 语义解析逻辑。
VNode 是 scalar node 的向量化版本。它基于 CustomScan API 构建,可以出现在 PostgreSQL plan tree 中。
例如:
VScan 负责向量化扫描
VSort 负责向量化排序
VHashJoin 负责向量化哈希连接
VLimit 负责向量化 limit
VNode 的直接子节点是 shadow,但 shadow 不实际执行。VNode 从 shadow 中读取语义信息,然后从自己的 vectorized child 中读取列式批量数据。这实现了两个目标:
保留 PostgreSQL 原始计划语义
执行时走 mxvector 的批量化、列式、向量化路径
PostgreSQL executor 中,节点之间通常通过 TupleTableSlot 传递数据,传统 slot 更适合传递一条 tuple。而 mxvector 需要传递的是:
columnar data
batch data
zero-copy data
所以它实现了VSlot,VSlot 继承自 TupleTableSlot,但可以按批量传输列存数据,也可以在需要时自动转换回 row。这让它既能服务向量化执行器,也能和传统执行器兼容。因此 VSlot 的定位可以概括为:不只是兼容桥梁,更是 mxvector 内部的高性能数据通道。
SQL 中大量逻辑都体现在表达式里:过滤条件、投影表达式、算术表达、类型转换、函数调用、聚合参数。
mxvector 需要将这些 scalar expression 转换成 vectorized expression。如果某些表达式已经有原生向量化实现,就走高性能版本,如果暂时没有原生实现,则使用 fallback expression,通过 scalar expression 模拟批量执行。
这使得 mxvector 可以做到:
对高收益路径优先加速
对复杂或暂未支持表达式保证正确性
避免因为覆盖度不足导致整个查询无法执行
AM adapter 的作用是在已有的 table/index access method 与向量化执行器之间建立桥梁。
传统 table/index AM 往往更偏 row-oriented,而 mxvector 期望的是 batched columnar data,因此需要 adapter 将底层数据访问方式转换成向量化执行器需要的数据接口。
与此同时,YMatrix 的列存引擎提供了更适合向量化执行的数据基础:
基于 Table Access Method API
type-based encoding
block-level micro-meta filtering
ordered scan
aggregated scan
automatic sorting
这意味着存储层不仅仅是在存数据,而是在为上层向量化计算准备数据。
PostgreSQL 的传统执行器在 OLTP 场景下表现非常出色,但在 OLAP 和 HTAP 场景下存在显著的性能瓶颈。向量化执行器通过批量处理、列存储、SIMD 等技术,为 PostgreSQL 提供了一条新的高效执行路径。
通过 mxvector 向量化执行器,我们在保持 PostgreSQL OLTP 性能的同时,成功为分析型工作负载引入了一个可插拔的高性能执行路径。这个方案利用 PostgreSQL 强大的扩展能力,使得我们可以在不影响核心功能的情况下,提升 PostgreSQL 在分析型场景下的性能。
未来,我们希望通过进一步优化内存管理和并行执行,继续提升 PostgreSQL 的执行能力,特别是在大规模数据分析和实时数据处理的场景中,推动 PostgreSQL 向更加多元化、高效的方向发展。
推荐阅读










