

现今,随着 AI 应用的不断落地,AI 正从外围辅助工具,逐步深入企业真实业务流程。从智能客服、知识库问答,到运维助手、风控分析、设备诊断,企业对 AI 的期待已经不再停留在回答问题,而是希望它参与判断、追溯原因、解释结果。随之而来的,是数据检索问题变得愈发复杂。
企业用户关心的,也不再局限于能否找到几段相似内容。他们会继续追问:
这个答案是否符合业务规则?
是否基于最新数据和正确口径?
相关线索之间是否存在关系路径?
日志、工单和历史记录里有没有证据支撑?
在这种情况下,单纯找到几段语义相似的文本,已经很难满足真实业务里的检索需求。企业 AI 检索真正要解决的,是如何让 AI 在业务数据、关系上下文、文本证据、语义线索和分析结果之间建立起连接,让 AI 能够真正理解业务。
换句话说,企业需要的不是某一个单点检索工具,而是一条能够承载复杂业务问题的混合检索链路。
以车联网或工业 IoT 场景为例,一个运维 Agent 可能会收到这样的问题:最近 24 小时,哪些设备出现了异常波动?这些异常是否集中在某个区域、某个固件版本,或者某一批传感器上?相关日志里有没有相同错误码?维修记录里有没有类似描述?历史上有没有相似故障?
看起来只是一些自然语言提问,但当真正执行时,其背后会被拆成一连串数据动作:
需要先按时间、区域、设备型号、指标阈值做过滤;
再沿着设备、传感器、固件、维修工单去查关系;
再从日志和维修记录里找错误码、关键词和文本证据;
如果不同工程师对同一类问题用了不同说法,还需要用语义检索找到历史相似案例;
最后,系统还要把结果按区域、版本、设备批次做聚合和排序,判断异常是否有共性原因。
所以,企业 AI 检索不是简单地查找相似内容,它需要把业务规则、关系链路、文本证据、语义线索和分析判断放在同一条问题链路里。
在这条链路背后,涉及的是多种不同类型的检索与计算:结构化过滤、图遍历、全文检索、语义检索,以及聚合、排序等分析型查询,其特点也很明显:数据类型多、查询路径长、上下文强,而且往往需要在持续更新的数据上完成多轮筛选和判断。
传统架构在面对这类混合检索场景时,往往会采用多系统拼接的方式,以前文所述的设备诊断问题为例进行拆解,应用层可能要向多套系统发起查询:
首先在关系数据库里,查找结构化指标数据,找出最近 24 小时异常波动的设备;
然后到搜索引擎里查日志和工单。以 Elasticsearch 为例,可能需要按设备 ID、错误码、告警文本等条件继续检索,并根据相关性排序;
接着再到向量库里做相似召回,查历史维修记录里有没有语义相近的故障描述;
如果还要判断这些异常是否集中在同一批传感器、同一固件版本或同一次升级之后,应用还要到图系统里做关系遍历。
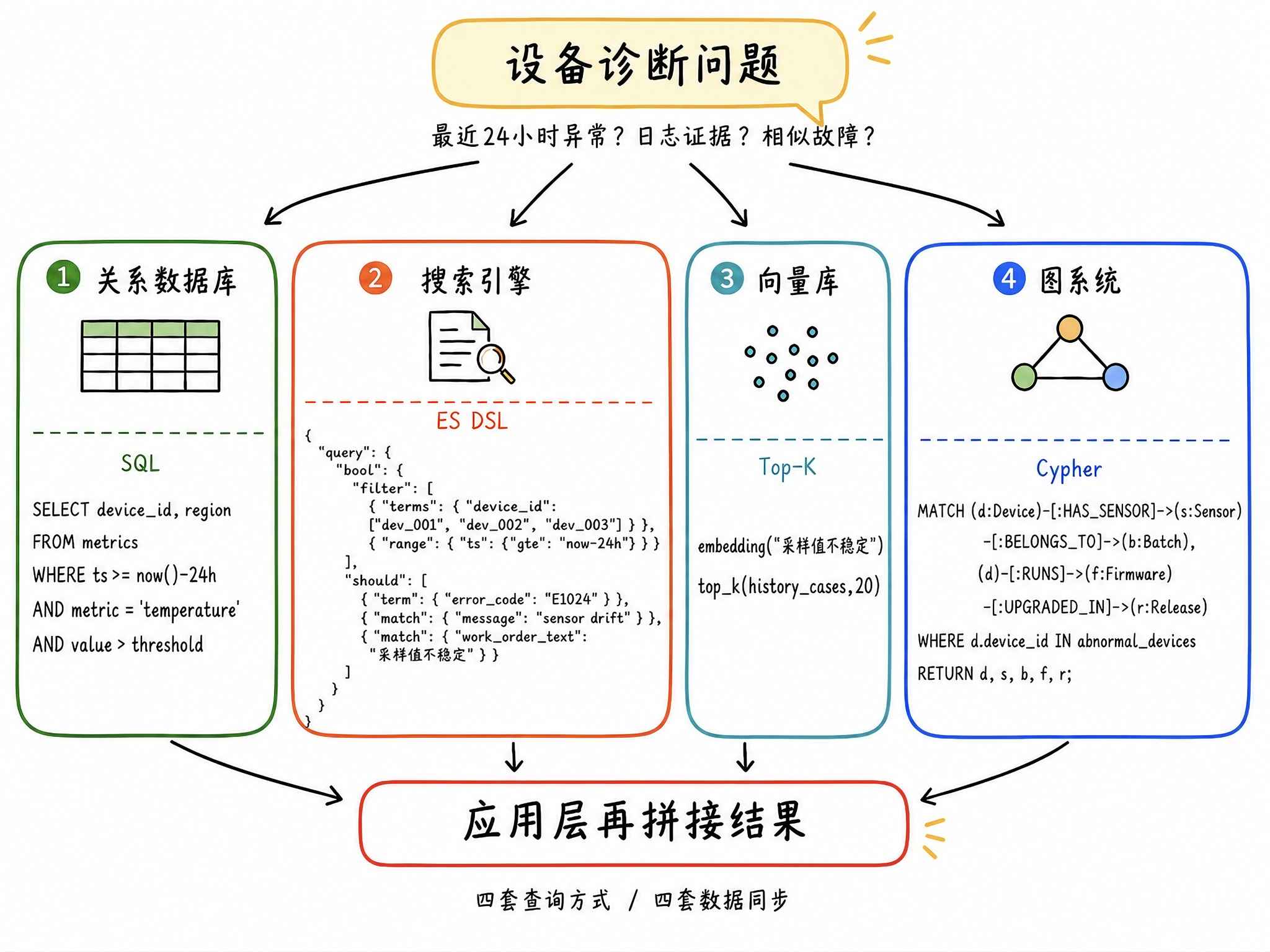
这种方式看似分工清楚,实际会带来很长的检索链路和新的数据孤岛。同一份业务数据需要在多个系统之间反复同步和搬迁,权限、安全策略和数据口径也需要分别维护。一旦数据持续更新,或者查询需要跨越多个系统完成过滤、关联、召回和分析,结果一致性、实时性和可解释性都会变得很难保证。
所以,企业 AI 检索需要解决的,不只是多拼接几个检索组件,而是如何把结构化过滤、关系遍历、全文检索、语义召回和分析判断放到一个统一、可治理的数据底座里。
这也正是 YMatrix 希望攻克的难题。
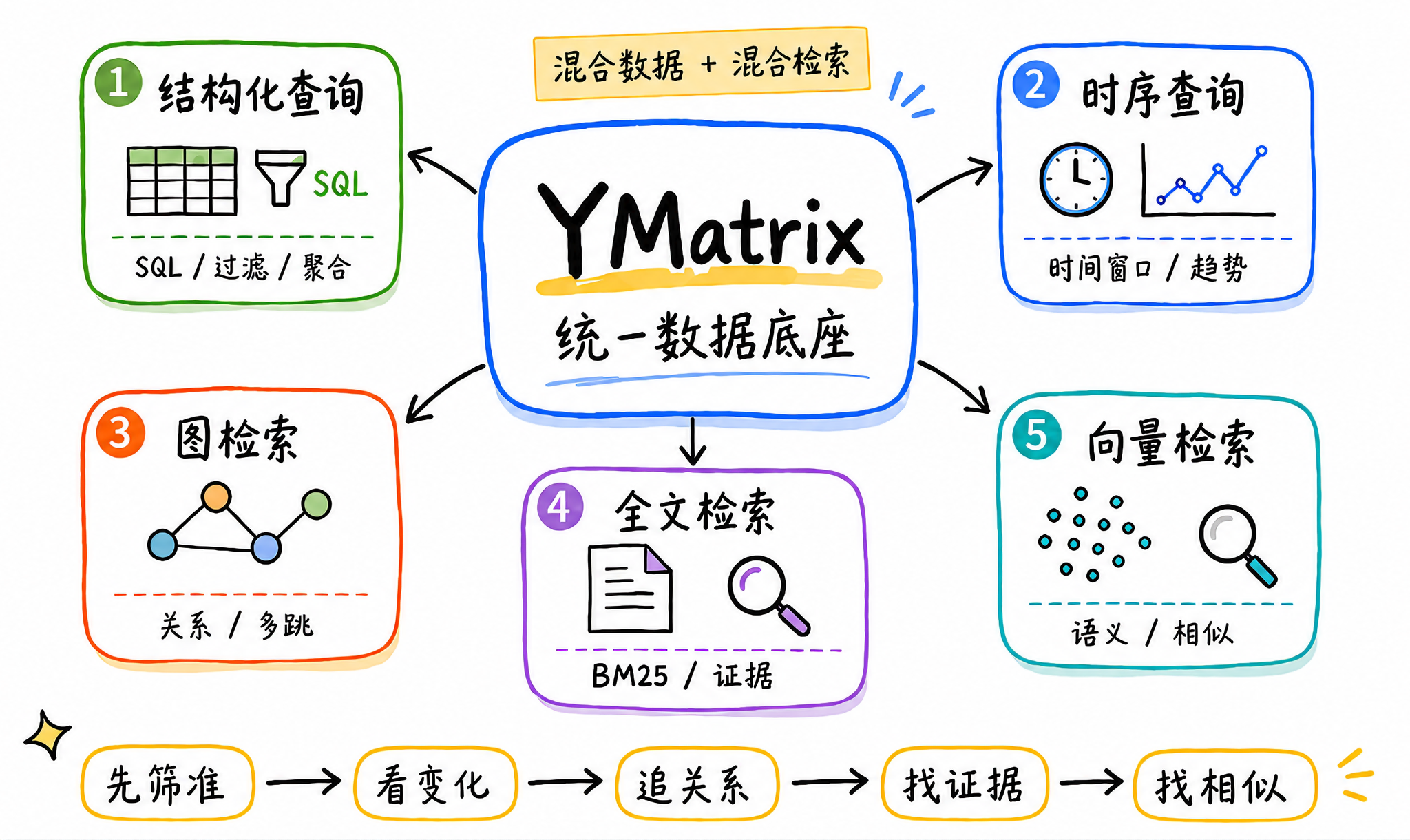
面对前文提到的问题,YMatrix 给出的答案是,基于一个统一的数据底座,让业务规则、时间变化、关系路径、文本证据和语义经验,围绕同一份业务数据协同工作。这样一来,便无需在多套系统之间反复搬运和拼接数据,而是可以在更完整的业务上下文中完成检索、分析和判断。
落到数据库能力上,这条链路对应的不是某一种单点能力,而是一组能力的协同:
业务规则,需要结构化查询来承接;
时间变化,需要时序查询来分析;
实体关系,需要图检索来表达;
日志、工单、文档中的证据,需要全文检索来定位;
历史案例和相似问题,需要向量检索来召回。
YMatrix 要做的,就是让这些能力在同一个数据库引擎中围绕同一份数据发生关联,可以概括为五个步骤:先筛准,看变化,追关系,找证据,找相似。
企业 AI 的很多问题,第一步不是语义召回,而是确定查询边界。
"最近 24 小时"、"某个区域"、"某批设备"、"某个固件版本"、"异常值超过阈值",这些条件都需要结构化查询来承接。YMatrix 天然支持 SQL、多表关联、聚合、窗口函数、Lateral 等复杂分析能力,可以先把自然语言问题收敛到明确的数据范围里。同时,YMatrix 的向量化执行引擎面向列式存储和分析型查询设计,通过批量处理、减少函数调用、利用 CPU 缓存和 SIMD、按列加载等方式提升执行效率。
对 AI 场景来说,这类能力支撑的是先筛准、再分析,可以避免 AI 在过大的数据范围里盲目召回。这一层解决的是:AI 看到的数据范围是否正确。
很多企业 AI 问题,都不是静态查询。
设备诊断要看指标是否异常波动,运维分析要判断故障从什么时候开始扩散,风控场景要识别某类行为是否在短时间内集中出现。这里需要的不只是"查到一条记录",而是围绕时间窗口、趋势变化、异常点和聚合结果继续分析。
YMatrix 长期面向时序与实时分析场景构建能力,支持高并发写入、乱序和分批写入、时序函数 (诸如 last_value、time_bucket 等)、冷热数据分级以及集群水平扩展。
对 AI 场景来说,这类能力可以把持续变化的数据纳入同一条检索链路,让问题从"有没有异常"走向"异常何时发生、如何扩散、是否集中在某类设备或区域"。这一层解决的是:AI 能不能理解数据的时间变化。
企业 AI 面对的很多问题,并不是单条记录能解释清楚的。
一台设备可能关联多个传感器,一个传感器属于某个批次,一个批次对应某个固件版本,固件版本又可能关联某次升级、某类工单和某个区域。要判断异常是否具有共性原因,AI 不能只看某个点,还要沿着实体之间的关系继续追问。
YMatrix 提供原生图查询能力,可以通过 SQL 入口调用图查询,在同一数据库上下文中完成图模式匹配、多跳遍历、变长关系遍历、最短路径、路径计数、标签过滤和环路检测等操作。同时,YMatrix 在图执行层面引入 GraphBLAS / LAGraph、VLE rewrite、matrix pruning、count-only fast path 等优化,用于减少不必要的路径展开和中间结果生成。
这意味着 AI 可以从"某个异常设备"继续追溯到"相关传感器、同批次设备、固件版本、历史工单和相似故障链路"。这一层解决的是:AI 能不能把分散线索串成关系路径。
AI 给出的答案,不能只停留在语义相似,还需要能回到具体证据。
在日志、工单、维修记录、知识库和业务文档中,很多关键信息并不是结构化字段,而是错误码、告警文本、处理描述和人工备注。YMatrix 原生支持面向现代搜索场景的全文检索能力,其中,基于 BM25 的相关性排序,让系统不再局限于只判断是否包含某个词,而是进一步判断哪些文本更值得优先查看。
对 AI 场景来说,这意味着答案可以从"模型推测"回到"业务证据":哪些日志出现过相同错误码,哪些工单记录过类似描述,哪些文档里写过处理步骤,都可以在同一条查询链路中被继续追溯。这一层解决的是:AI 的回答能不能找到可核对、可解释的文本依据。
企业数据里的同一类问题,往往不会用同一种说法表达。
在故障记录里,有人写"指标抖动",有人写"采样值不稳定",也有人写"周期性偏移"。如果只依赖关键词匹配,很多历史经验会被漏掉。YMatrix 支持向量数据存储与相似度检索,可以将文本、知识片段、历史工单、故障案例等内容转化为向量,并基于语义相似度召回相关结果。
在能力上,YMatrix 支持精确与近似最近邻检索,支持常见距离计算方式,并可通过 HNSW、IVFFlat 等索引方式提升大规模向量检索效率。
对 AI Agent 来说,这意味着它可以在不同表述、不同文档和不同历史记录之间找到语义相近的经验,而不必依赖完全一致的关键词。这一层解决的是:AI 能不能找到不同表达背后的相似经验。
有了这五类能力,关于前面的设备诊断问题,在 YMatrix 中便可以被组织到同一个 SQL 上下文里,这不仅简化了应用开发链路,也可以减少数据同步、结果对齐和权限维护的复杂度:
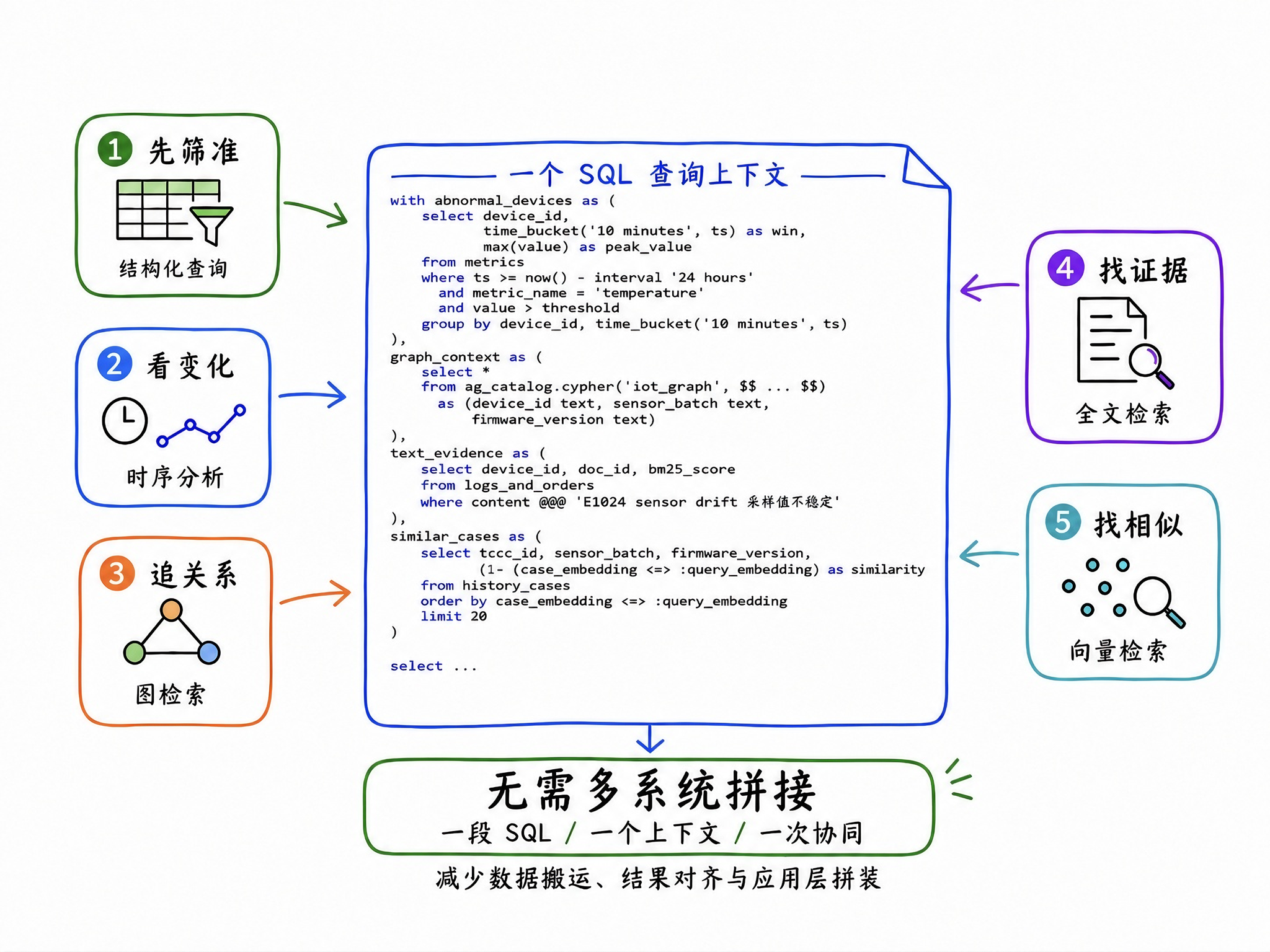
AI 时代,企业需要的不是系统堆砌,而是一个能把业务规则、时间变化、关系路径、文本证据和语义经验连接起来的一体化数据底座。
YMatrix 的核心价值,是用一体化数据库引擎承载这条混合检索链路,让结构化查询、时序分析、图检索、全文检索、向量检索和分析能力围绕同一份数据协同工作,打造 AI 时代下的统一、可信、可治理的数据底座。
推荐阅读










