
MatrixDB 是一款关系型时序数据库,数据模型采用关系模型。
用关系模型存储时序数据有很多优点:
时序数据是结构化数据,很适合使用为时序优化过的关系数据库存储和处理
时序场景期望数据的正确性(ACID),以确保数据不错不重不丢,关系型数据库在事务方面支持更好
时序数据库需要强大的分析能力,关系型数据库在做复杂查询方面更有优势,如:连接、聚合、分组、窗口等
关系模型固然好用,但在做时序采集时也面临一些挑战,考虑如下场景:
要采集的指标过多,超过了 PostgreSQL 的最多 1600 列限制
不同型号设备采集指标集合差别较大,导致在回传数据时有大量列值为 NULL
无法预知指标集,即表 schema 可能要经常变
针对如上问题,MatrixDB 技术团队开发了 mxkv 自定义数据类型,提供了 kv 键值存储结构,完美解决了如上场景的问题。
如下图所示,mxkv 是一个键值类型,内部可以存储任意数量的键值。键数量无限制,并且可以任意增加新键。对于不确定的指标将其存在 mxkv 字段里即可。实际存储空间开销取决于键值数量和大小。
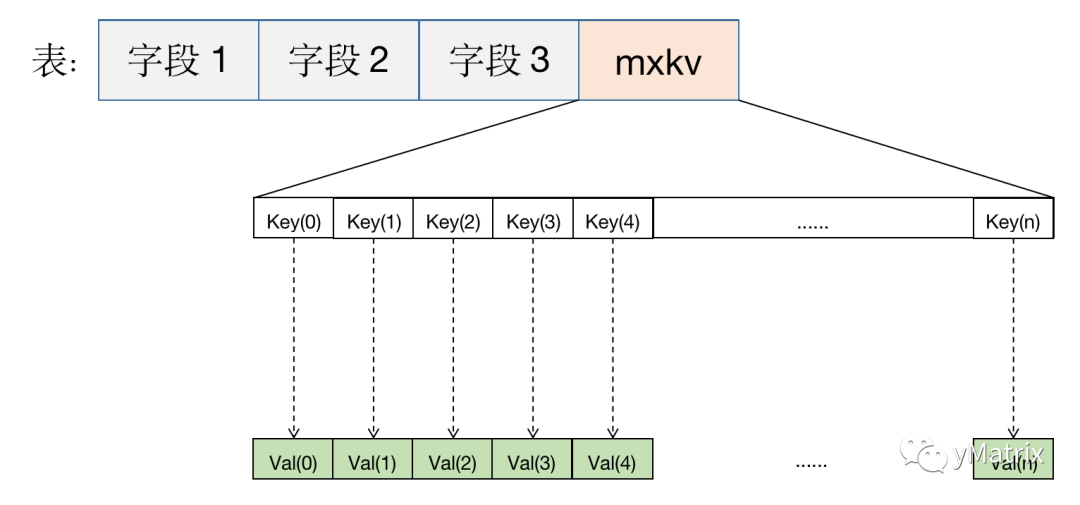
mxkv 自定义数据类型包含在 MatrixTS 扩展中,首先要创建扩展:
create extension matrixts;验证 mxkv 是否已经开启:
mxadmin=# select '{}'::mxkv_text;
mxkv_text
-----------
{}
(1 row)如上所示,mxkv 已开启。
创建一张新表,并在新表中定义 mxkv 的整型 value 数据类型 mxkv_int4,来存储 value为 整型的 kv 数据:
CREATE TABLE data(
time timestamp with time zone,
tag_id int,
kv mxkv_int4
)
Distributed by (tag_id);在使用 mxkv 类型前,为了压缩与查询性能优化,首先要做键名导入,来提前确定数据中包含的键名集合。
mxkv 提供了 UDF mxkv_import_keys来完成键名导入。
有两种导入方式:
mxkv 的交互形式和 json 一致,手动提供 json 形式的 kv 样例,mxkv 会自动提取键值并完成导入。
如下 SQL 会提取 json 中的键名 'a' 和 'b' 并导入:
mxadmin=# select mxkv_import_keys('{"a": 1, "b": 2}');
mxkv_import_keys
------------------
a
b
(2 rows)现有 t_json 表,包括 json 类型的字段 c2:
mxadmin=# select c2 from t_json ;
c2
----------
{"k1":1}
{"k2":2}
(2 rows)从结果可以看到,t_json 表有两行数据,c2 列包括 k1 和 k2 两个键。
使用mxkv_import_keys通过表数据导入:
mxadmin=# select mxkv_import_keys('t_json'::regclass, 'c2');
mxkv_import_keys
------------------
k1
k2
(2 rows)如上所示,在参数中提供表名和列名。相比手动导入,这种方式更方便、更快捷。前提是样例数据已存储在其他表中。
导入键名后,该键可以在当前数据库中的任何表中使用。
键确定后,下面开始插入 kv 数据:
mxadmin=# insert into data values(now(), 1, '{"a":1, "b":2}');
INSERT 0 1如上所示,插入的 kv 数据中,包含了刚刚导入的键 'a' 和 'b'。
注意:kv 中的键必须导入后才能正确插入,否则会出现如下错误:
mxadmin=# insert into data values(now(), 1, '{"c":1}');
psql: ERROR: unknown key "c"
LINE 1: insert into data values(now(), 1, '{"c":1}');
^
DETAIL: The key is not imported yet
HINT: Import the keys with the mxkv_import_keys() functionmxkv 键内容的读取方式与 json 一样,都是使用 -> 符号:
mxadmin=# select kv->'a' as a, kv->'b' as b from data;
a | b
---+---
1 | 2
(1 row)注意:mxkv中->与->>效果等同。
上面创建的表中使用了 mxkv_int4 类型,mxkv 共支持如下几种类型:
mxkv_int4:存储int4/int类型的32位整数值
mxkv_float4:存储float4/real类型的32位浮点数值
mxkv_float8:存储float8/float/double precision 类型的64位浮点数值
mxkv_text:存储text类型的字符串值
其中mxkv_float4和mxkv_float8可以定义定点小数,如:
CREATE TABLE data(
time timestamp with time zone,
tag_id int,
kv mxkv_float4(2)
)
Distributed by (tag_id);这样定义后,小数点两位以后的将会做四舍五入。指定小数位数后,内部存储类型将转换为整型,更有利于优化和压缩。但数值范围也会相应缩小。
mxkv_float4(scale), scale >= 0
mxkv_float4(0): [-2147483500, 2147483500]
mxkv_float4(2): [-21474835.00, 21474835.00]
mxkv_float4(4): [-214748.3500, 214748.3500]
......
mxkv_float8(scale), scale >= 0
mxkv_float8(0): [-9223372036854775000, 9223372036854775000]
mxkv_float4(2): [-92233720368547750.00, 92233720368547750.00]
mxkv_float8(4): [-922337203685477.5000, 922337203685477.5000]
......
mxkv 类型目前有如下限制:
只支持一级kv结构,不允许嵌套和数组。
为了保证数据有效性,导入的键值无法删除。
目前不支持对某个key单独更新,只能更新整个列。
通过前面的介绍,会发现mxkv与PostgreSQL原生支持的json类型有很多相似之处:
都是用 json 格式进行交互
取值都是使用 -> 操作符
不同之处:
mxkv只能存储一层,value下面不能再分级
mxkv底层是二进制存储并且做了压缩和查询优化,性能要优于json类型

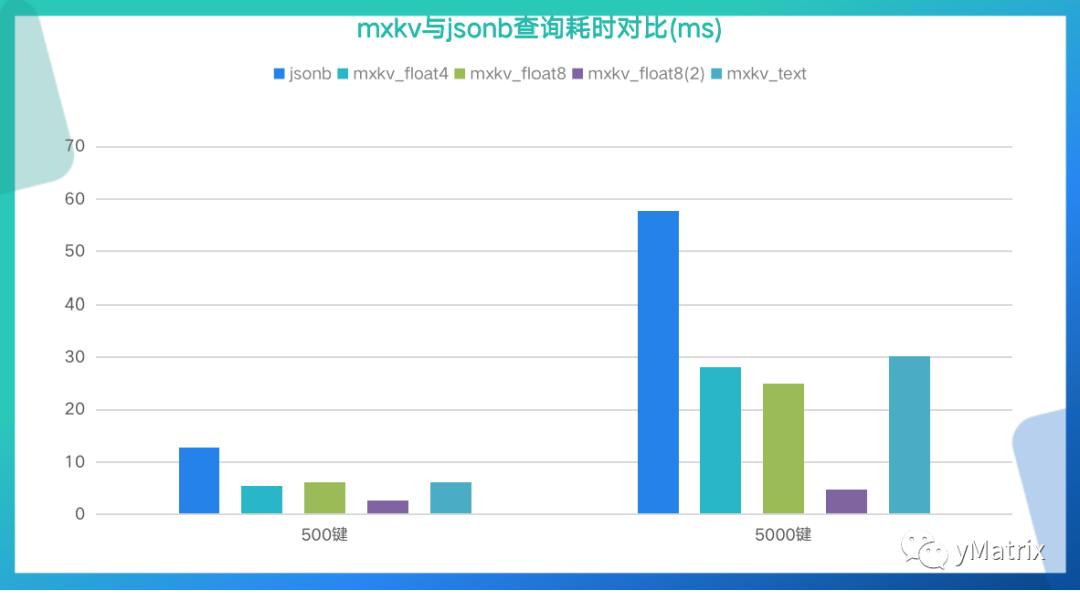
从统计结果可以看出:在 500 列和 5000 列的情况下,mxkv 的存储空间和查询延时只有 jsonb 的 40%。
mxkv 是一个高效的键值存储类型,方便为模式固定的关系表进行字段扩展
mxkv 支持整数、定点小数、浮点小数和字符串值类型
mxkv 存储空间占用和检索性能明显好于json






