
近日,第十二届中国数据库技术大会(DTCC2021)召开。会议上,针对行业内时序场景需求,以及关系型和非关系型数据库在提供解决方案时的差异和利弊,YMatrix CTO 翁岩青发表主题演讲《时序数据库,从无关到有关》。

以下为部分演讲内容节选:
时间序列数据是“带有时间戳”的一系列结构化数据,来自联网设备在不同周期性产生的指标数据。
以新能源汽车为例,由传感器采集多种类型数据,如:位置、车速、电池、环境等信息。自动驾驶汽车每秒钟采集数千个指标,这些指标数据用来做智能应用,可以说越是智能的场景,越需要大量的数据来做实时计算,用数据驱动智能。
除了设备产生指标数据以外,时序数据的范畴还包括一些事件,即在“特定时间点”产生的数据,如银行账户间转账记录信息、账户余额信息,从时序的角度来看余额是账户的最新状态,是经过一系列不同时间点收入和支出后所产生的最新值。
“普通数据+时间列”与“时序数据”两者之间的区别,主要取决于如何看待时间所起的作用。
在普通数据中,时间是数据的属性信息。同样以银行账户余额为例子,属性信息指的是,时间与账户的余额是人民币还是美元,存在哪个银行,这些信息是一样的。如果以时序数据角度来看,时间是数据的状态信息,有状态就表示数据是“动态的”,可以跟踪状态变化。
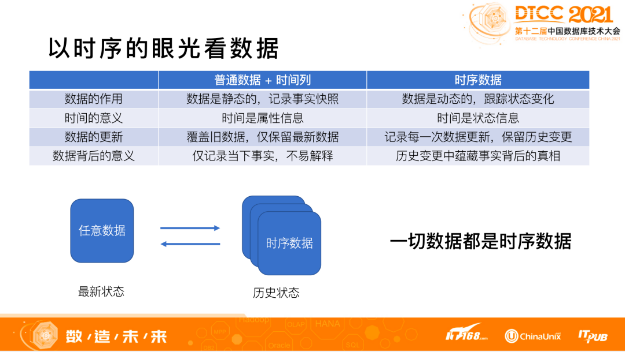
在数据更新方面也存在着差异,普通数据的更新是 update 操作,新数据覆盖旧数据,每次更新只保留最新版本,不会保留历史记录。时序数据的更新是采用 insert 或 append 操作,每次的更新都是一个“完整记录”,同时保留所有的历史记录。
时序数据比普通数据蕴含更多背后的信息,比如账户余额是如何经过变化,到达目前的最新值,余额数据是经过日积月累产生,还是一夜暴富,都可以通过挖掘历史记录来获得答案。
从这个角度来看,任何数据都是时序数据,时序数据记录一条数据的“多个”状态,数据量也将会是原来的 N 多倍。
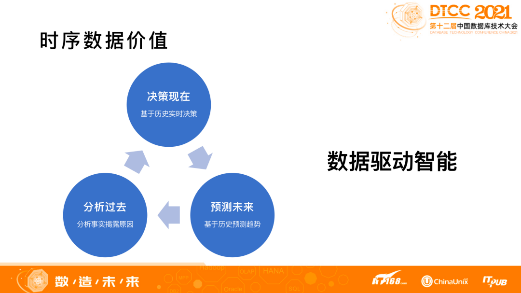
通过对历史数据的分析来总结规律,能更好理解数据本身,帮助我们做实时决策,对于未来可以做趋势的判断。
讨论时序数据库前,需要先了解“时序数据”的基本概念。下图中的数据是风力发电风机所产生的时序数据。
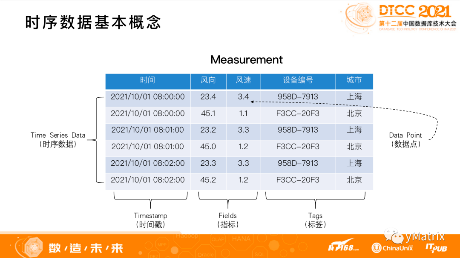
分为三类:第一类是 Timestamp(时间戳);第二类是 Tags(标签数据),可以确定图表里有两个风机设备,分别位于上海和北京,每个设备有两个属性;第三类是 Fields(指标数据),也就是设备产生的一些指标值,每个值都是一个数据点。时序数据库就是统一处理这三类数据的工具。
需要特别注意的时,时序数据除了具有“时间列”外,还有以下几种特征。
只读的结构化数据:不同设备产生的数据是互相独立的,通常在设备产生数据后,数据无需再修改。
数据是按时间顺序进行上报,可能会存在乱序、延迟、分批上报的情况:以车联网为例,车辆在正常行驶下,数据是按照“时间顺序”进行上报。如果在没有信号、数据发不出去的情形下,联网后,会优先上报当下的最新数据,再上报离线累积数据,这就是“延迟和乱序上报”;分批上报是指一辆车每秒钟采集 5000 个指标,这 5000 个指标由于网络传输的限制,会分成 5 批上传,每一批分成 1000 个,这就是分批上报。
有温度属性(冷热特征): “热数据”指最近一段时间的数据,价值密度高,查询需求比较强烈;“冷数据”指历史数据,随着时间增加,数据的价值逐渐的降低,查询的需求逐渐减弱。但联网设备数量逐渐增多,历史数据不断的积累,冷数据对于挖掘类查询的价值反而会更大。
数据总量大且增速快:在设备规模大、指标数多且采集频率高的场景下,5G、智能家居等设备规模都是千万级甚至达到亿级,指标数从几十到几千个不等,采集频率为分钟级、秒级,采集时间也从几个月到数年不等,有些场景一个月就能达到 PB 级,在面对大规模的数据时,存储和计算都非常的复杂。
关注数据变化的趋势:时序数据的体量很大,需要关注数据变化的趋势,而非单点数值。
当前的时序数据库里主要有两类解决方案,代表两种不同的数据模型:“窄表”及“宽表”。
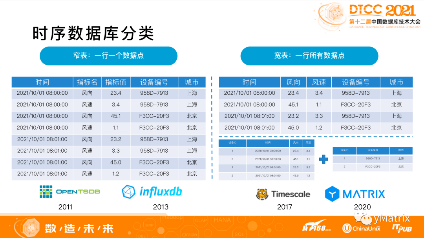
窄表数据模型可以理解是KV模型。目前市面上众多的时序数据库,包括 influxDB、OpenTSDB 都是采用这种模型。前面提到时序数据分为3类:时间戳、标签数据、指标数据。窄表模型是把标签数据下,每一个时间点的每一个数据点都作为一行来存储。
宽表模式对应的是关系模型。目前在大数据的时序分析里逐渐开始越来越多,典型的产品包括基于 PostgreSQL 的 TimescaleDB 和 YMatrix。关系模型是对现实世界中最好的一个建模方式,概念与时序相对应,是一个标签和时间下的每个数据点,所有的指标在一行存储。同时为了进一步降低标签数据的冗余,可以抽取出标签,形成一个标签表或者是设备表,查询的时候两表进行关联。
在真实时序场景里,时序数据和关系数据是同时存在,时序数据需要关系数据做注解,不能孤立存在,这对数据库的性能和功能提出挑战。
分析的功能和性能需求强烈,功能需求是业务需要,性能需求是用户体验。如果数据库功能需求不全,就需要应用层来做额外处理;如果性能解决不好,不但影响用户体验,还需要多个数据库做联合处理。

所以当前处理时序数据的架构都存在一个显著问题,复杂需求导致复杂技术栈的产生,维护和运维难度增大,在每一个分布式系统中,一旦出现问题都会导致系统不稳定。 同时,应用开发层面也很复杂,需要从多种数据库中读取数据,并在应用层处理,还要处理各种系统的错误情况。
此外,每个系统都是分布式存储,为保证数据不丢,每一份数据都有多个副本且都在多个系统里,增加存储成本。数据还需要在不同系统间来回搬运,既浪费资源,又浪费时间,导致数据时效性差,一致性也难以保证。
从我们的实践积累来看,造成这些问题的根本原因是非关系数据库分析能力的弱化,不能像关系数据库一样通过标准 SQL 来表达所有查询需求,通过优化器、执行器来同时满足性能和功能的需求,造成了这种复杂、低效、成本高的现状。
专用时序数据库一开始更多强调扩展性、写入性能,弱化分析能力,提供简单的时序聚合分析,满足当时的应用场景,但当前复杂及丰富的智能场景已不再适用。
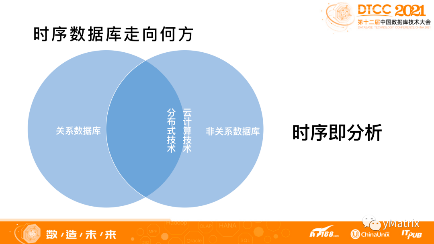
随着分布式技术的不断成熟,云计算技术的普及,非关系数据库的扩展性能的优势大不如前。关系数据库最重要的优势是“通用分析能力”,通用指对功能的完备及性能的平衡。
所以,时序数据库的发展方向应该是在关系数据库的基础上,更好的支持当前越来越复杂的时序需求。
分布式架构完全高可用,线性扩展,支持在线扩容,同时也支持分布式事务,保证数据不错、不重、不丢,降低应用开发的负担。
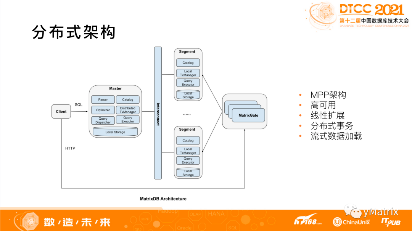
YMatrix 的分布式架构则采用 MPP 架构:
主节点 Master,负责整个集群的元信息管理;
从节点 Segment,负责分布式存储和分布式计算;
网络层 Interconnect,负责分布式查询过程中数据的高速网络通信。
高性能数据加载工具 MatrixGate,负责实时数据的流式加载,加载过程中数据不落地,并行加载到所有 Segment 上。
此外,YMatrix 是基于 PostgreSQL 的分布式关系数据库,因为除了解决数据规模带来的三大问题:写入、存储和查询,还要解决时序特定的需求。

数据加载支持各种数据上报方式,支持海量设备,控制资源开销。
支持对错误数据的自动识别,遇到数据错误,尤其是格式错误,不能阻碍数据加载。
支持多种数据模型,既要支持宽表的关系模型,也支持窄表的 KV 模型,有些场景下,比如设备差异比较大,或者设备升级,导致指标频繁变化的时候,KV 模型还是很方便的。
加载过程中要能做一些流式计算,比如通过持续聚集,自动对数据进行降采样。
支持标准 SQL,同时对时序所需要的分析,从优化器到执行器进行全方位的优化,保证功能和性能。
支持高级语言的数据分析,数据库内可以用 Python、R 或者 Java 写函数,做库内机器学习,库内机器学习相比 Spark 使用移动数据的方式做计算,库内机器学习是把计算推到存储层,移动计算要比移动数据性能会快很多。
从存储来看,如果能保证数据在时间和设备两个维度的局部性,既有利于高压缩比,又有利于查询性能,YMatrix 的存储引擎也提供多种机制来保证数据的局部性。
在分布式的环境下,数据分片(sharding)是解决单机存储容量限制和资源限制的主要方式。图中红色实线区域是数据分片的方式,是按照设备 ID 做 Hash。Hash 分片的好处是可以让同一个设备存储到同一个 Segment 节点上,也就是在节点级别来保证设备数据的局部性。
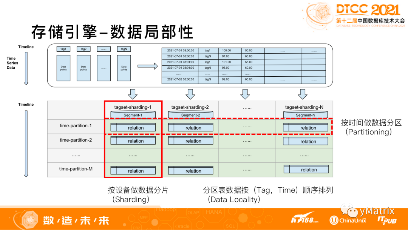
在数据分片的基础上,进一步对数据做更细的数据分区,采用的方式是按照时间范围来做分区,也就是图中红色虚线的部分。按时间分区的好处是可以在时间维度上进一步保证数据的局部性,也有利于做数据的生命周期管理。
按照设备做纵向的分片,按照时间做横向的分区之后,整体会形成一个大的分区表,每个分区表内部的数据是按照设备、时间(也就是 tag 和 time) 的顺序来存储,可以保证数据的完全局部性能。
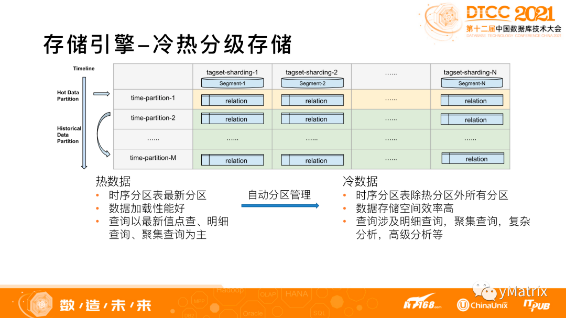
热数据要承接数据的写入,因此加载性能要好,查询以最新值的点查、明细查询、聚集查询为主,主要做实时分析。
冷数据一般不承接数据的直接写入,而是热数据转冷的时候,通过自动分区管理的机制批量导入。冷数据由于数据量大,因此压缩需求强烈,查询方面除了支持常规的时序查询,对分析类、挖掘类的查询也有需求,比如多表关联、复杂查询。
YMatrix 根据冷热数据不同的访问需求,用不同的存储引擎来进行处理。
热数据采用行存 HEAP 表来做存储引擎。行存 HEAP 表写入速度快,同时不受设备规模的限制,对于乱序写入可以通过索引来维护顺序,分批写入通过 upsert 功能来做边加载边合并,由于热数据通常是按时间顺序来写入的(不是我们所期待的 tag,time 顺序),因此会建一个 (tag,time )索引,通过索引来维护逻辑的数据局部性。另外,对于指标类、标签类都支持建立二级索引,加速多维查询。
冷数据采用的是行列混存引擎——“MARS”。冷数据是热数据通过自动分区管理机制批量导入的,在导入的过程中会按tag和时间段进行分组,组内再按照 tag 和 time 顺序来进行存储,这样就不需要B Tree来维护逻辑的顺序关系,做到物理的数据局部性,每个分组内采用压缩更好的列存方式。编码主要以增量编码为主,浮点数支持 Gorilla 编码,压缩以 ZSTD、LZ4 压缩为主,压缩比可以做到1:10到1:20。
索引方面,YMatrix Database 采用稀疏索引,维护每个分组的min,max边界值,可以做到跟 BTree 一样的效果,但空间只有 BTree 的1%,甚至是1‰。
对于常见的指标类时序聚集查询,会在每个分组上做预集,比如维护这一分组的 count 和 sum,这样对于一些聚集查询,直接返回预聚集作为查询结果,降低计算量同时提升性能。
这个是 YMatrix 整体的一个存储引擎示意图:
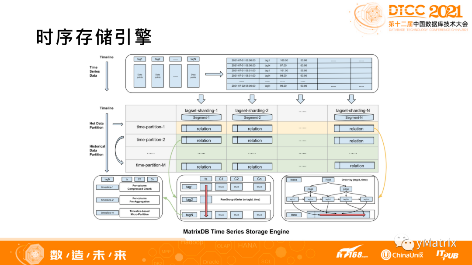
首先,尽可能保证设备和时间数据的局部性,无论是通过索引来维护逻辑局部性,还是通过存储布局来维护物理局部性;其次,通过分区表来做冷热分级管理,热数据用行存引擎,冷数据用行列混存引擎,通过自动分析管理机制来进行转换,完全不用人工参与,对用户透明。
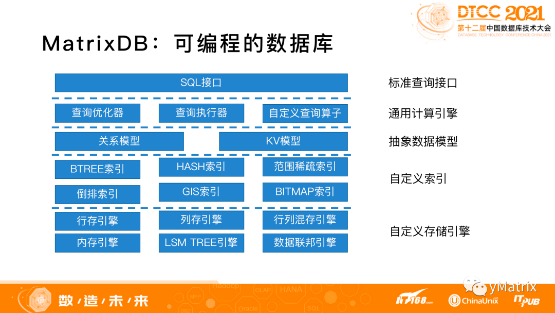
支持从 SQL 1992 和 SQL 2016 全部的标准,任何对数据的操作都可以通过一个 SQL 搞定;
支持丰富的类型系统和索引能力,无论是文本数据、 GIS 数据,还是各种半结构化数据都有内置的数据并行支持,同时支持自定义;
支持高级语言查询,可以用 Python、R、Java 来写函数,做库内机器学习,移动计算而不是移动数据;
支持数据联邦查询,大部分主流的外部数据源都支持跨库查询,不需要 ETL 导数据。
超融合数据库实现存储引擎和索引自定义,除了存储以外的优化器、执行器,甚至执行器的算子都可以自定义。
把数据库看成是一个通用的编程平台,数据库开发人员根据业务需要定制自己的存储引擎和计算逻辑,同时共享数据库的基础能力,比如分布式能力,MPP执行能力,分布式事务能力,高可用能力等等。
所以,在服务时序场景时,对比专用时序数据库叠加关系数据库的方案,超融合数据库是更优异、更出色、更易用的解决方案,可以把复杂度留在数据库产品内部,把便利和效率释放给用户,加速企业数字化转型和数据价值挖掘能力提升。






