任何一款数据库,数据都遵循某种模型,如关系模型、KV模型等。超融合时序数据库MatrixDB,以关系模型为基础,增加了可扩展数据类型,使其既能方便做关系运算,同时又不受关系模型固定的限制,既高效又灵活。
本课程教学视频请参考MatrixDB数据建模与时空分布模型
要接入时序数据,首先要知道时序数据包含如下信息:
所以,在做数据接入时,MatrixDB需要如下数据表:
其中,设备信息表包括设备ID和其他属性,如名称、位置等。
指标表来存设备ID和所有指标。
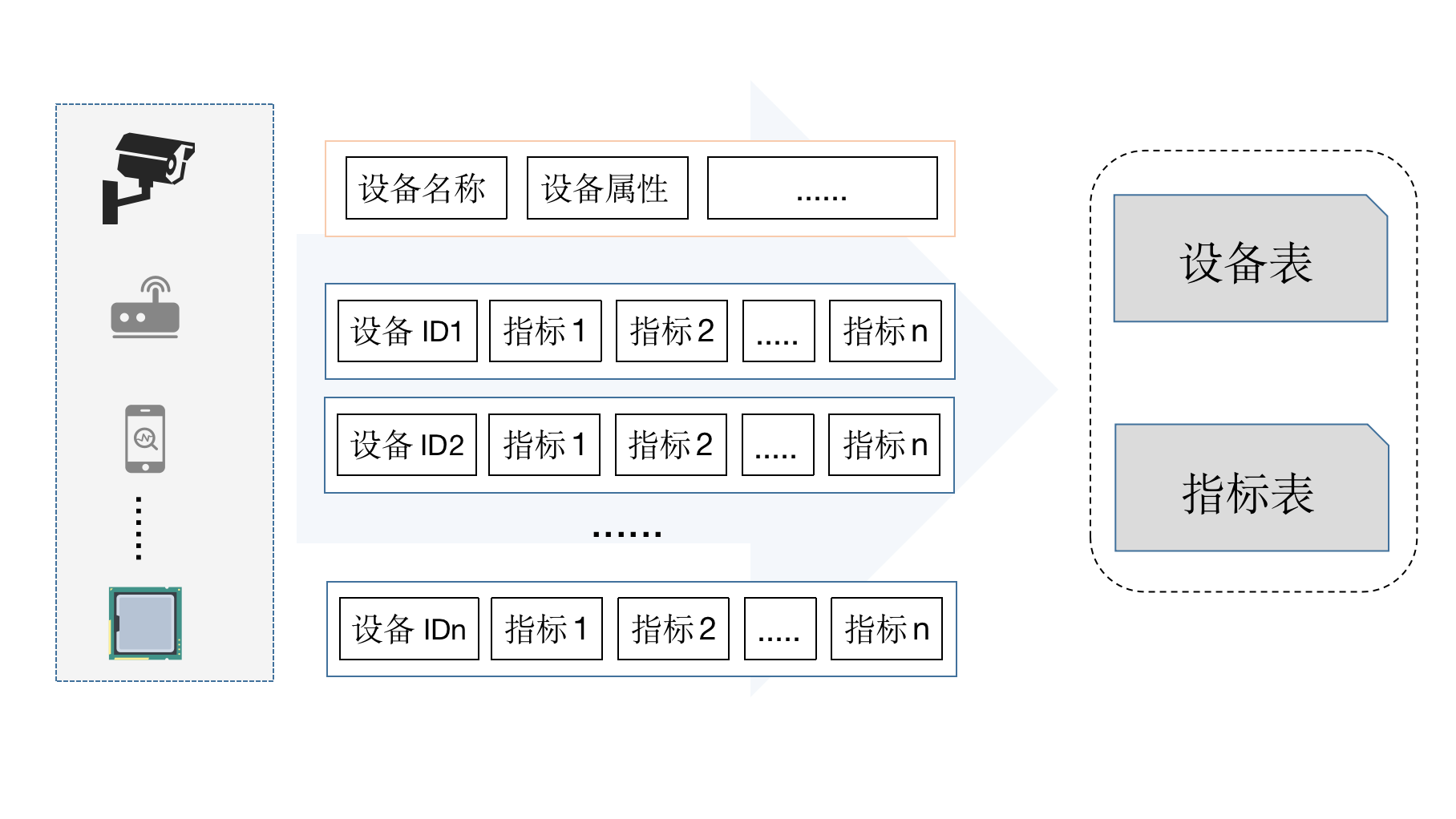
之所以要把两个表分开而不是存在一起,主要原因是:
这样设计符合关系模型设计范式,但是又引入了一个新的问题,设备ID如何生成。通常使用如下两种方法:
下面举例说明,如何接入时序数据。 假设要采集风机的转速、温度和湿度。风机设备包含名称、编号、区域、坐标等属性。
按照如上方法,需要准备如下两张表:
| 字段 | 类型 | 描述 |
|---|---|---|
| tag_id | int | tag_id为风机的唯一id,用自增主键(SERIAL类型) |
| name | text | 风机名称 |
| serial_number | text | 风机序列号 |
| region | text | 风机所属区域 |
| longitude | float4 | 风机经度 |
| latitude | float4 | 风机纬度 |
| 字段 | 类型 | 描述 |
|---|---|---|
| tag_id | int | 风机id |
| time | timestamp | 时序数据的时间戳 |
| speed | float4 | 风机转速 |
| temperature | float4 | 风机温度 |
| humidity | float4 | 风机湿度 |
和其他数据库一样,在MatrixDB中,数据表是按库组织起来的,所以先创建数据库stats。
可以连接默认数据库postgres,然后使用CREATE DATABASE创建:
[mxadmin@mdw ~]$ psql postgres
psql (12)
Type "help" for help.
postgres=# CREATE DATABASE stats;
CREATE DATABASE也可以直接使用MatrixDB的命令行工具createdb创建:
[mxadmin@mdw ~]$ createdb stats创建好数据库后,要连接进去才能使用。在MatrixDB中每个连接只能隶属于一个固定的库。
可以在执行psql命令尾随数据库参数连接:
[mxadmin@mdw ~]$ psql stats
psql (12)
Type "help" for help.
stats=#也可以从其他数据库连接中,使用\c元命令,切换连接到新的数据库中:
postgres=# \c stats
You are now connected to database "stats" as user "mxadmin".连接数据库后,开始创建数据表:
创建tags表:
CREATE TABLE tags(
tag_id serial,
name text,
serial_number text,
region text,
longitude float4,
latitude float4
)
Distributed replicated;创建指标表:
CREATE TABLE metrics(
time timestamp with time zone,
tag_id int,
speed float4,
temperature float4,
humidity float4
)
Distributed by (tag_id);从上面的建表语句会发现,两个表的分布方式不同。
tags表使用得是Distributed replicatedmetrics使用得是Distributed by (tag_id)因为:
有关数据分布更详细的介绍请参考数据分布模型
因为tag表中设备信息必须唯一,所以需要为标识设备唯一属性的信息建立唯一索引,便于应用端维护设备信息。这里假设设备编号用来标志设备的唯一性,所以建立如下唯一索引:
CREATE UNIQUE INDEX ON tags(serial_number);应用方在进行指标数据接入的时候,需要按如下步骤进行:
那么设备标识如何转换成ID呢? 设备ID并不是设备自身的一个属性,不会随指标数据发送过来,需要应用方进行转换。
最简单的做法就是每次根据设备编号查库,如果存在则直接读取;不存在则插入新设备并生成ID。
这种方法需要每个指标在插入前都要查库,大大增加数据库负载,影响吞吐量。所以推荐做法是,在应用方维护一个内存哈希表。每条数据在到来的时候从内存哈希表查询设备ID,存在则直接使用;不存在则插库获取设备ID并更新哈希表。
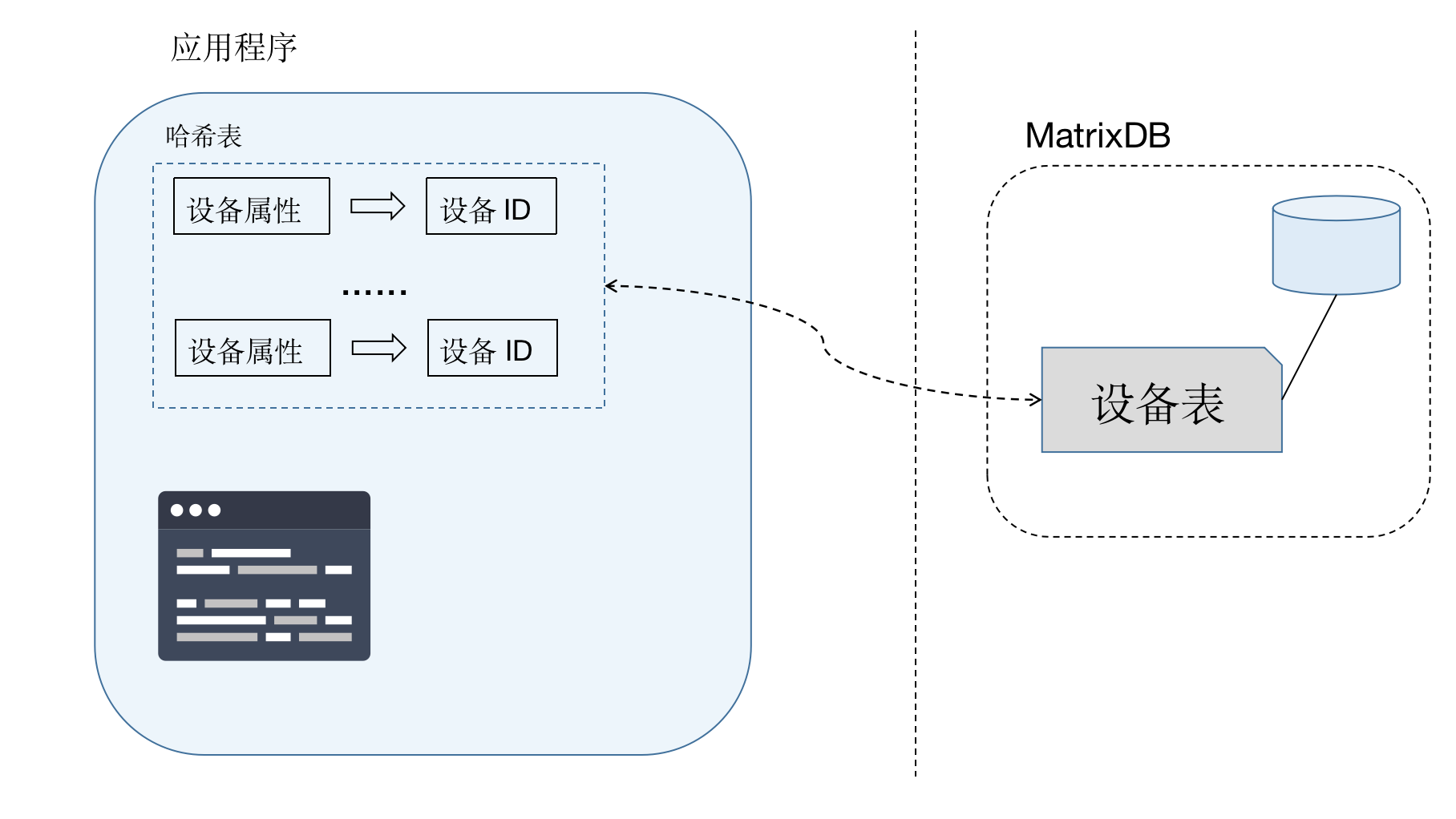
既然设备信息和指标数据分开到两个表存储。在做查询的时候,如果既要获得指标统计信息又要获得设备信息,要基于设备ID做连接。
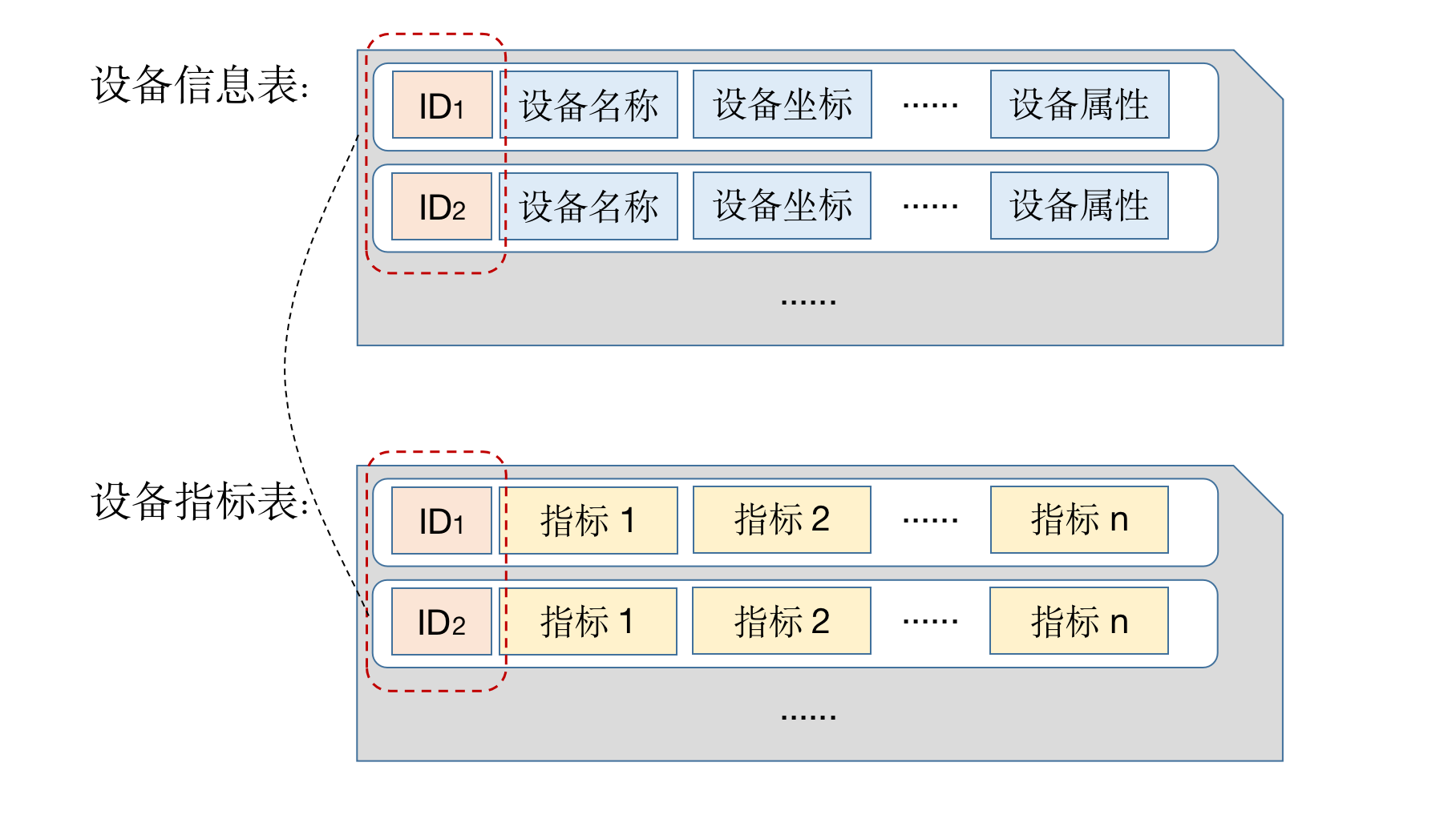
如下SQL统计了'2021-07-01'日每个风机的平均温度、平均湿度和最大转速:
SELECT tags.name,
AVG(metrics.temperature),
AVG(metrics.humidity),
MAX(metrics.speed)
FROM tags JOIN metrics USING (tag_id)
WHERE metrics.time >= '2021-07-01'
AND metrics.time < '2021-07-02'
GROUP BY tags.tag_id, tags.name;从上文介绍可以看出,MatrixDB是关系型数据库,在数据建模时使用的是关系数据库的范式。关系模型固然好用,但在做时序采集时也面临一些挑战,考虑如下场景:
针对如上问题,MatrixDB技术团队开发了mxkv自定义数据类型,提供了kv键值存储结构,完美解决了如上场景的问题。
如下图所示,mxkv是一个键值类型,内部可以存储任意数量的键值。键数量无限制,并且可以任意增加新键。对于不确定的指标将其存在mxkv字段里即可。实际存储空间开销取决于键值数量和大小。
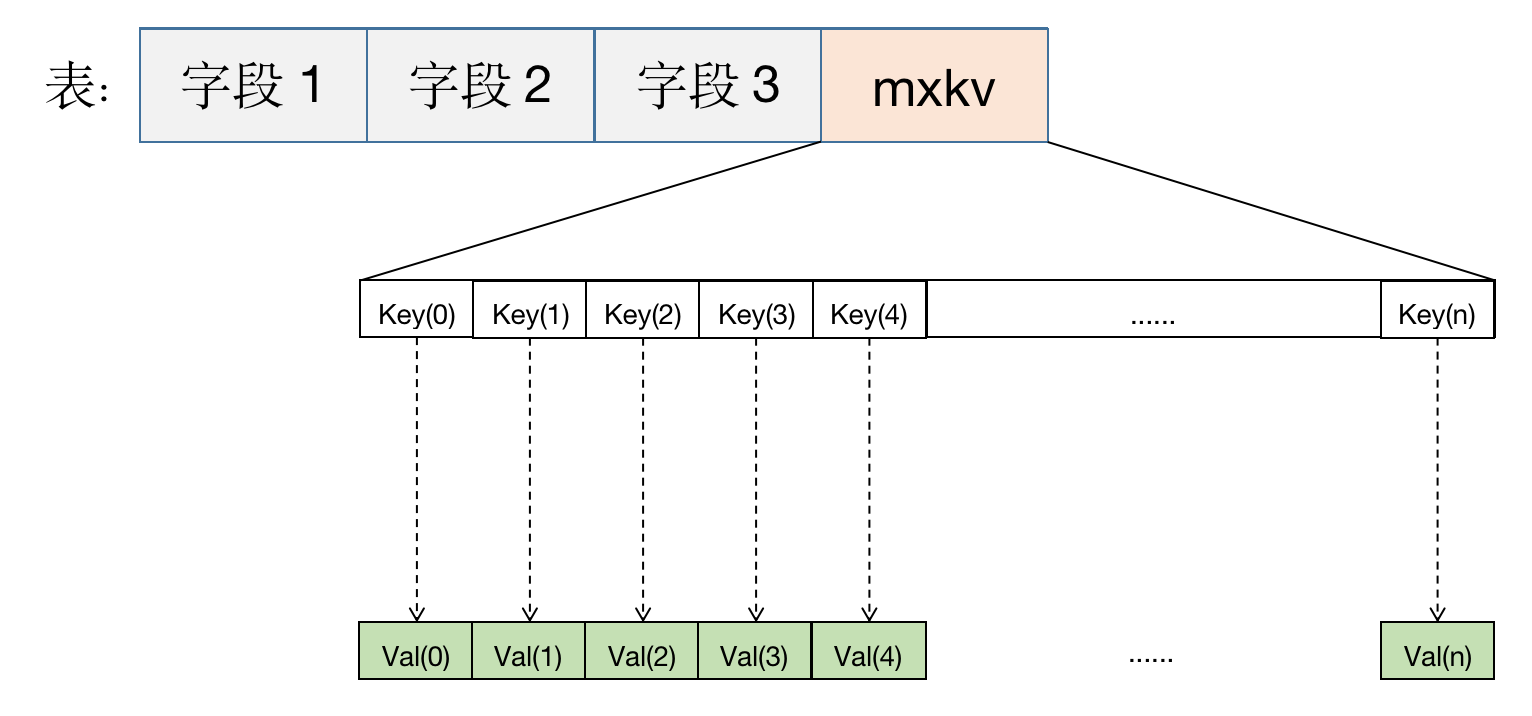
mxkv的使用请参考mxkv






