MatrixDB简介
MatrixDB是同时支持在线事务处理(OLTP)、在线分析处理(OLAP)和物联网时序应用的超融合型分布式数据库产品,具备严格分布式事务一致性、水平在线扩容、安全可靠、成熟稳定、兼容PostgreSQL/Greenplum协议和生态等重要特性。为万物互联的智能时代提供坚实、简洁的智能数据核心基础设施,为物联网应用、工业互联网、智能运维、智慧城市、实时数仓、智能家居、车联网等场景提供一站式高效解决方案。
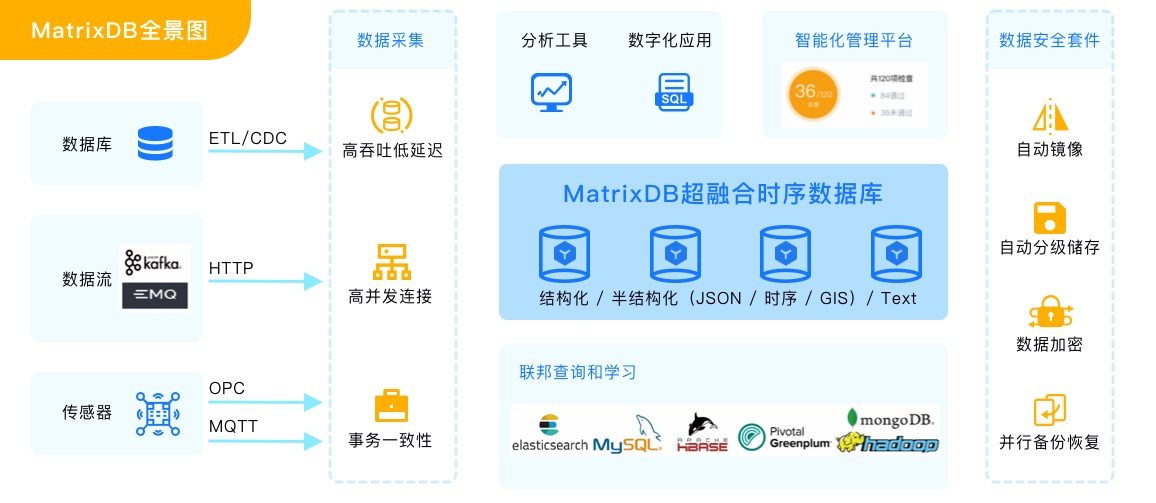
相比传统的“烟囱式”、“孤岛式”数据架构,MatrixDB开创的超融合架构具备以下优势:
- 赋能数字化新业务场景:数字化和数字孪生改变IT部门在整个组织中的角色,使之从业务支撑角色成为业务赋能角色,成为数字化业务的重要一环。传统的“烟囱式”数据架构无法高效应对数字化时代对处理实时性、数据多样性、用户/设备规模性、场景复杂性等要求更高的新场景。超融合时空数据库技术通过平台化、模块化、分布化完美的解决这个问题。超融合架构契合奥卡姆剃刀原理:“如无必要、勿增实体”。
- 10倍降低投入:超融合时空数据库避免采购众多的单体产品,大幅降低产品投入;避免数据在不同系统间冗余存储,大幅降低存储空间投入;避免复杂的数据流动,大幅减低数据管理投入;超融合架构大幅降低了运维投入。
- 10倍提升开发运维效率:开发工程师无需在不同的数据源之间来回切换,无需把数据从不同数据源拉到内存中进行复杂计算,无需重新发明轮子而借助强大的SQL进行业务数据处理,实现数据独立性、应用层和数据层的解耦,大幅提升开发效率。运维人员无需管理几十种产品而集中精力在少量产品上,大幅降低数据处理核心架构的复杂性,大幅提升运维的效率
- 10倍提升总体性能:通过平台化、模块化,可以实现数据近距离通信、实现计算贴近数据;通过分布式,借用线性扩展大幅提升系统总体性能;通过经典的数据库理论嫁接现代分布式理论,大幅提升系统总体吞吐量,降低系统延迟。
四大亮点
亮点一:原创超融合时空数据库技术
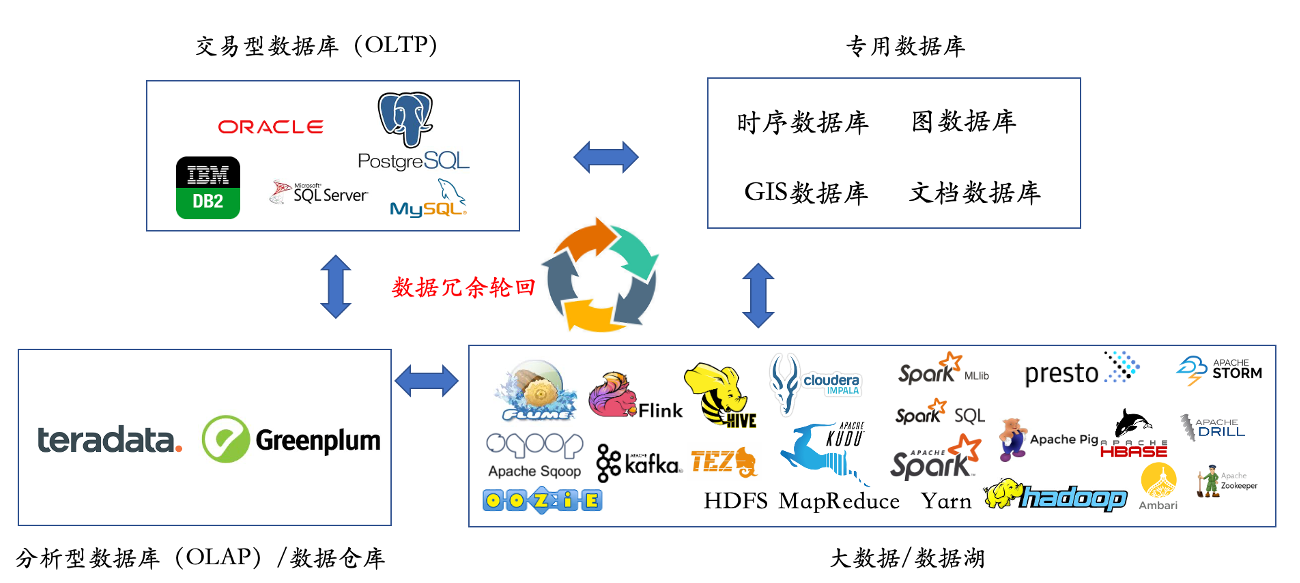
传统数据处理平台使用不同种类的数据库处理不同类型的数据,造成“数据孤岛”、“数据质量低下”、“数据冗余轮回”等问题,不但价格高昂,而且效率低下,严重阻碍了数字化时代的新业务需求。MatrixDB原创超融合时空数据库技术,使用一款数据库处理各种数据,完美的解决了大数据“多样性/Variety”的挑战,为数字化时代的业务提供强力支撑。
传统的数据架构如下,典型问题是数据孤岛化严重、数据质量低、数据冗余存储轮回、系统复杂昂贵。超融合时空数据库技术通过平台化、模块化、分布化从根本上上解决了数字化时代核心数据平台面临的巨大挑战。
亮点二:高吞吐、低延迟、高并发准实时数据加载
数字化时代,交易、设备和机器每时每刻都在正在生成大量数据,少则几十多则数千万交易和设备可以同时生成数据注入数据库,数据库的加载能力备受关注。MatrixDB实现了超大规模数据的实时加载特性,在保证低延迟和高并发加载的同时,也充分减轻了系统资源消耗。
基于独有专利技术,在支持ACID保证数据严格正确性的前提下实现海量数据的准实时、低延迟数据采集,并具有极佳的线性扩展能力。支持RESTfulAPI,允许上万客户端同时注入数据。借助专门创建的存储引擎和优化的内存表示,MatrixDB可以分级存储用户数据,让热数据常驻内存,毫秒级响应查询,历史冷数据经过10倍以上压缩保存在磁盘,索引压缩比例更高,为企业保存海量历史数据节省大量成本。
亮点三:联邦查询和联邦学习
数据类型和数据源的多样化是许多企业面临的现状,MatrixDB可以快速将外部数据导入集群。除此之外,还可以通过联邦查询直接原地查询其他数据源的海量数据,包括ElasticSearch、MongoDB、MySQL、Oracle、PostgreSQL、HBase、Hive、HDFS、S3等,也可以将外部数据源和集群内的数据进行关联分析和执行数据联邦机器学习。
亮点四: 现代SQL
MatrixDB支持从SQL92到SQL2016的各种高级SQL特性,包括JSON、窗口函数、数据立方体、递归关联子查询等,一条SQL语句抵数千行代码,既可以大幅减少应用开发维护成本,又可以避免应用和数据库之间反复的数据访问交互,提升执行效率。
特性丰富、功能强大
- 时序特性: 支持时序数据的流式快速插入、高压缩比存储和高效查询,支持first、last、time_bucket等常用时序函数
- 支持行存表、列存表:行存表用于OLTP业务,支持高效更改和删除,列存表用于OLAP业务,支持特定列扫描和压缩,行存和列存表任意关联无限制
- 透明分布式:所有DDL、DML语句和单机数据库一样,分布式内建在数据库中,对用户完全透明
- 自动分片管理:数据在各个数据节点间自动分片分布,无需用户或者管理员管理干预,数据分布方式多样,支持哈希分析、随机分布和复制分布
- 海量数据存储:支持PB级数据的无限量存储,单个数据库可以存储多达40亿张表,单表可以保存多达2的48次方行记录,单行或者单字段最多可以保存超过1G数据
- 丰富的数据结构: 支持关系型、XML、JSON、键值、地理空间、文本等结构化、半结构化和非结构化数数据模型
- 支持索引:支持快速点查和范围查找的Btree索引、占用空间极小的稀疏索引Brin和Odin,以及文本检索的倒排索引GIN等
- 高并发极速OLTP:得力于索引和缓存的帮助,支持高并发连接下的毫秒级OLTP业务的增、删、改、查操作
- 高级分析: 支持复杂场景下的多表数据关联查询,支撑数据分析的即席查询
- 存储过程: 支持SQL、Java、Python3等各种语言编写的存储过程
- 数据库内机器学习: 可以在数据库内完成分布式机器学习
- 企业级特性完备:内置图形化监控管理、一键在线扩容、高可用自动数据镜像、增量备份、细粒度资源管理等






