本文档介绍了在 YMatrix 中支持数据自动降级到对象存储(如 AWS S3),从而实现全自动化冷热分级的方法。
注意!
此功能仅支持MARS3 表。
物联网场景会产生海量的数据存储。YMatrix 认同热数据(实时数据)重要性的同时,也兼顾对冷数据(历史数据)存储性能和易用性的挖掘。例如:电商平台 7 天内的交易订单访问量会较高,而超过无理由退换的时间后,订单数据被访问的频率就会逐步减少,但过期的订单数据又占用了大量存储空间......此时,如何能够尽量降低此部分的存储成本便成为一个值得思考的问题。
为解决冷数据的存储问题,YMatrix 开发了降级存储功能。其支持将冷热数据存储在不同的介质上:热存储保持为标准型存储、性能性存储、本地 SSD 盘或本地 HDD 盘,冷数据则主动转储到容量型存储,如对象存储之上。容量型存储的价格仅为标准型存储的 20%,大大降低了存储成本。成功转储的数据也将无缝接入 YMatrix 强大的大规模并行计算(MPP)底座,完成数据分级和存储优化。
除存储环境本身的成本节约外,数据降级存储的过程也无需人工干预,最大程度的降低了人工管理成本和使用成本。
目前主流的降级存储方案大多基于 FDW(Foreign Data Wrapper)。区别于基于 FDW 的方案,YMatrix 将对象存储视作一种和本地文件系统等价的存储介质,并将它无缝的接入了 MARS3 存储引擎,对于普通的文件系统适用的能力,对降级存储中的数据同样适用。
这意味着在 MARS3 中降级存储将拥有更多的可能性:
| 特性 | YMatrix(MARS3 降级存储) | FDW 相关方案 |
|---|---|---|
| 支持事务 | 是 | 否 |
| 支持冷数据自动转储 | 是 | 否 |
| 管理复杂度 | 不需要人工接入 | 需要复杂的运维支持 |
此部分我们将通过完整的流程测试使你直观、快速地体验降级存储的过程与结果。
本文以 AWS S3 为例。
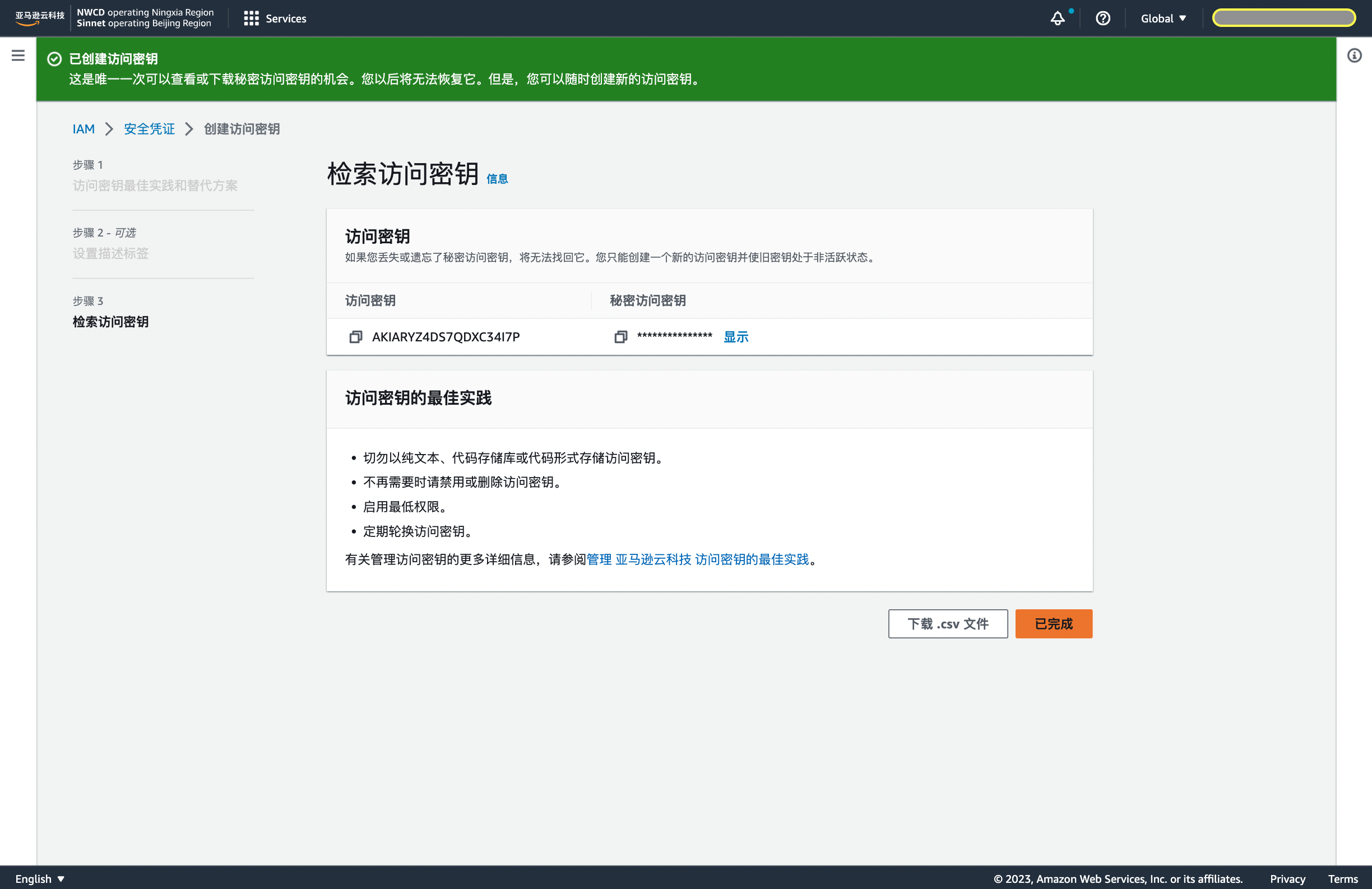
首先登陆 AWS ,点击右上角用户名处按钮,选中 Security credentials,下滑选择 创建访问密钥。
_1689323577.png)
因为我们需要将冷数据从 YMatrix 中整理并转储到 AWS S3 对象存储桶中去,因此需要选择 在 亚马逊云科技 之外运行的应用程序。

创建成功。
成功创建对象存储桶后可得到以下信息:
在测试集群的 Master 和 Segments 服务器上创建表空间目录。
$ mkdir -p <tablespace_dir,eg:'/home/mxadmin/test'>首先使用 vi quick.sql 命令创建 quick.sql 文件,并保存以下内容:
-- 创建 matrixts 扩展
CREATE EXTENSION IF NOT EXISTS matrixts;
-- 配置相关系统配置参数
\!gpconfig -c mars3.enable_objectstore -v ON --skipvalidation
\!gpconfig -c mars3.degrade_min_run_size -v 0 --skipvalidation
\!gpconfig -c mars3.degrade_probe_interval -v 300 --skipvalidation
-- 创建表空间 your_tbs
DROP TABLESPACE IF EXISTS your_tbs;
CREATE TABLESPACE your_tbs LOCATION :tablespace_dir
WITH(
oss_accessid=:oss_accessid,
oss_secretkey=:oss_secretkey,
oss_endpoint=:oss_endpoint,
oss_region=:oss_region,
oss_bucket=:oss_bucket
);替换下方 < > 内(含 < >)的配置信息,并执行该命令,快速初始化降级存储:
$ psql -be -d <your_database>
-v tablespace_dir="'<your_tablespace_dir>'" \
-v oss_accessid="'<your_oss_accessid>'" \
-v oss_secretkey="'<your_oss_secretkey>'" \
-v oss_endpoint="'<your_oss_endpoint>'" \
-v oss_region="'<your_oss_region>'" \
-v oss_bucket="'<your_oss_bucket>'" \
-f quick.sql重新加载配置文件:
$ mxstop -u使用 vi quick2.sql 命令创建 quick2.sql 文件,并保存以下内容:
\set tname t1
\set tnamestr '''t1'''
-- 创建测试表,设置将 7 天前的数据转储到对象存储
DROP TABLE IF EXISTS :tname;
CREATE TABLE IF NOT EXISTS
:tname(
key int,
value int,
c3 date)
USING mars3
WITH(ttl_interval='7 d', ttl_space='your_tbs')
DISTRIBUTED BY (key)
ORDER BY (key, value);
-- 往测试表中插入一批测试数据
INSERT INTO :tname SELECT i, i, current_date FROM generate_series(1, 12000000) i;执行 quick2.sql 文件:
$ psql -be -d <your_database> -f quick2.sql通过内置的工具函数,将这张表所有的数据全部手动转储到对象存储:
$ psql <your_database>
=# SELECT matrixts_internal.mars3_degrade('t1'::regclass, -1);成功执行以上命令后,t1 的数据已经全部转储到了你的对象存储上,集群上只有一个用来访问这些数据的“壳”。可以用以下命令来验证一下数据访问是否正常:
=# \set tname t1
SELECT * FROM :tname LIMIT 10;
DELETE FROM :tname WHERE key < 50;
SELECT * FROM :tname WHERE key < 50;最后,你可以直接进入对象存储的管理平台,可以看到你创建的存储桶中已经存在这些数据。你可以将这些转储成功的对象存储测试数据全部删除,再从集群访问,例如:
=# SELECT * FROM :tname WHERE key < 50;就会发现数据库报错 key not exist,这意味着测试成功:你访问的数据已经完全变成对象存储中的对象数据了。
| 功能 | 介绍 | 配置参数 |
|---|---|---|
| 不同认证模式接入 | YMatrix 支持用两种认证模式来接入对象存储,选择其一即可: 静态的 AccessId/SecretKey 基于 Security Token Service(STS) 的动态 AccessId/SecretKey |
创建表空间时相关配置参数 系统参数 mars3.degrade_credential_update_interval |
| 转储策略管理 | 管理转储策略。包括历史数据的判断依据,数据后台任务的定时检查时间间隔等 | ttl_interval/ttl_space/mars3.enable_objectstore/mars3.degrade_probe_interval |
| 数据查询缓存 | 缓存通过减少直接与对象存储之间的交互提升数据 I/O 的效率,从而提升查询性能 | matrixts.enable_object_cache/mars3.enable_object_prefetch/oss_cache_size |
| 运维工具 | 数据链路检查工具:系统检查当前环境是否已满足降级存储功能所需的依赖条件 垃圾扫描工具:找出对象存储中的残留数据并手动清理 |
_1689752363.png)
YMatrix 支持用两种认证模式来接入对象存储,选择其一即可:
本文快速体验部分采用了 AWS S3 为例,为静态认证,语法如下:
=# CREATE TABLESPACE <your_tablespace> LOCATION '<your_tablespace_dir>'
WITH(
oss_accessid='<your_accessid>',
oss_secretkey='<your_secretkey>',
oss_endpoint='<your_address>',
oss_bucket='<your_bucket>'
);如果使用 STS 模式来访问对象存储,那么你不仅需要在表空间上填充参数,还需要额外实现一个脚本来定时刷新表空间上的参数:
-- 创建表空间
CREATE TABLESPACE <your_tablespace> LOCATION '<your_tablespace_dir>'
WITH(
oss_endpoint='<your_address>',
oss_bucket='<your_bucket>'
);
-- 实现能更新表空间中 oss_sessiontoken/oss_accessid/oss_secretkey 配置项的定时任务。参考脚本如下
DB="postgres"
SPACE="tbs"
RES=$(aws sts get-session-token)
if [ $? != 0 ]
then
echo "get credentials fail!"
exit 1
fi
ak=$(echo "${RES}"|jq -r .Credentials.AccessKeyId)
sk=$(echo "${RES}"|jq -r .Credentials.SecretAccessKey)
token=$(echo "${RES}"|jq -r .Credentials.SessionToken)
if [ "${ak}" == "" ]
then
echo "AccessKeyId is empty!"
exit 1
fi
if [ "${sk}" == "" ]
then
echo "SecretAccessKey is empty!"
exit 1
fi
if [ "${token}" == "" ]
then
echo "SessionToken is empty!"
exit 1
fi
echo $ak
echo $sk
echo $token
psql -d "${DB}" -c "ALTER TABLESPACE ${SPACE} SET (oss_accessid='${ak}', oss_secretkey='${sk}', oss_sessiontoken='${token}');"
if [ $? != 0 ]
then
echo "alter tablespace fail!"
exit 1
fi如需定期更新访问对象存储的授权信息,请配置以下参数:
注意!
此部分表空间相关配置参数介绍请见CREATE TABLESPACE
使用转储策略的前提是启用数据转储功能,通过以下参数配置:
例如:
$ gpconfig -c mars3.enable_objectstore -v ON --skipvalidation
$ gpconfig -c mars3.degrade_probe_interval -v 300 --skipvalidation
$ mxstop -u具体的转储策略通常在建表时使用 ttl_interval、ttl_space 参数进行设置,语法如下:
=# CREATE TABLE <your_table> (
...
)
...
WITH (ttl_interval='<your_interval>', ttl_space='<your_tablebspace>')
...
;也可以在已有表上修改策略,示例如下:
=# ALTER TABLE <your_table> SET (ttl_interval='14d');当一个查询需要使用对象存储中的冷数据的时候,开启缓存可以大大降低数据库操作 I/O 的开销,从而可以提升查询性能,缓存受以下参数控制:
示例如下。建表时指定表空间下文件缓存空间为 10000MB:
=# CREATE TABLESPACE <your_tablebspace> LOCATION <your_tablespace_dir>
WITH(
...
oss_cache_size=10000,
...
);然后在查询会话内开启缓存(如需关闭缓存,也要在会话内完成):
=# SET matrixts.enable_object_cache to ON;
=# SET mars3.enable_object_prefetch to ON;注意!
文件缓存和内存缓存在每个后台进程上都需要占用 64MB 的内存空间,如一个查询需要启动 10 个后台进程,那么预计需要额外的内存空间为 640MB x 2 (假设两个缓存都打开),一般为了最优的查询性能,建议同时开启以上两个缓存。
如果你要现有的生产集群上接入降级存储功能,那么请先使用数据链路检查工具检查目前集群所在环境是否允许完整的功能运行。
链路检查工具 osscheck 安装后在 $GPHOME/bin 目录下。
使用步骤如下:
$ osscheck -g confvi conf 命令编写配置文件说明:
oss_accessid,oss_secretkey,oss_endpoint,oss_bucket;oss_sessiontoken;oss_keyprefix。模版如下,请替换下方 < > 内(含 < >)的配置信息:
oss_accessid='<your_oss_accessid>'
oss_secretkey='<your_oss_secretkey>'
oss_sessiontoken='<your_oss_sessiontoken>'
oss_endpoint='<your_oss_endpoint>'
oss_region='<your_oss_region>'
oss_bucket='<your_oss_bucket>'
oss_keyprefix='<your_oss_keyprefix>'
oss_retry_mode=default
oss_upload_partsize=5
oss_upload_parallelnum=3
oss_retry_times=3
oss_timeout=3000运行如下命令,基于填写好的配置文件做链路检查。如果验证成功,将出现绿色的 success 提示:
$ osscheck -t conf
put object success
get object success
list object success
delete object success如果检测失败,将会用红色 fail 提示失败的检测项:
$ osscheck -t conf.template
ERROR: InvalidAccessKeyId: The Access Key Id you provided does not exist in our records.
put object fail垃圾扫描工具会检查对象存储服务上是否有不符合预期的垃圾数据。
垃圾数据产生可能有如下几个原因:
在使用垃圾扫描工具时需要注意:
matrixts_internal.oss_junkobjects() 函数查询数据库目录的方式开展工作 ;oss_bucket/oss_keyprefix/ 目录下的垃圾对象。所以请确保该目录仅为当前集群所用。使用方法如下:
=# CREATE EXTENSION IF NOT EXISTS matrixts;
=# SELECT * FROM matrixts_internal.oss_junkobjects('<your_tablespace>');
key | lastmodify | size
-------------------------------------+------------------------+----------
49948/2/52751/4/0 | 2023-10-19 16:00:14+08 | 38964
49948/2/53021/1/0 | 2023-10-19 16:04:55+08 | 38964
16384/2/158581/3/0 | 2023-09-03 13:16:26+08 | 4080
16384/2/158581/p2 | 2023-09-03 15:18:36+08 | 5
16384/2/202151/3/0 | 2023-09-21 16:22:09+08 | 80
49948/1/52751/4/0 | 2023-10-19 16:00:14+08 | 40620
49948/1/52861/1/0 | 2023-10-19 16:01:34+08 | 240000
49948/1/53021/1/0 | 2023-10-19 16:04:55+08 | 40620
49948/1/53038/1/0 | 2023-10-19 16:05:10+08 | 120000
16384/1/158581/3/0 | 2023-09-03 13:16:26+08 | 3864
16384/1/202151/3/0 | 2023-09-21 16:22:09+08 | 20
49948/0/52751/4/0 | 2023-10-19 16:00:14+08 | 40416
49948/0/53021/1/0 | 2023-10-19 16:04:55+08 | 40416
......其中:
是的,而且隐含了时间必须为分区键,这个时间列可以是 date 或 timestamp 类型的,这是因为冷数据的转储需要以时间作为判断标准。目前分区键中如果找不到时间列是无法使用降级存储功能的。
注意!
目前降级存储功能尚不支持分区键中存在多个时间列的表。
默认是 1 小时,可以通过 mars3.degrade_probe_interval 参数修改。
设置如下参数并重新加载配置:
$ gpconfig -c mars3.enable_objectstore -v off --skipvalidation
$ mxstop -u逻辑上支持任意多个,但目前缓存尚不能很好支持多个表空间的数据同时使用的场景,建议每个集群仅创建一个对象存储表空间。
共享。
是可以单独使用的,但为了最佳的查询性能,建议全部开启。
不能,目前的版本只有在新建分区表,或者扩展新分区的时候,分区子表才能自动继承父表的配置项;如果是已经存在的父表,直接 ALTER TABLE 父表,是不能自动继承到子表去的.
此问题中阐述的额外内存 = 缺省配置下的内存 + 开启自动转储 + 并发查询 + 开启内存缓存和文件缓存
注意!
此结果估算的是一种理论上存在的最坏场景.
具体计算公式如下:
额外内存开销 = 客户端并发查询数 * 每个单节点的 Segment 实例数 * 查询平均扫描的表数 * (并行 Worker 数 + 1) * (64MB + 64MB + 10M) + 分区表数 * 每个单节点的 Segment 实例数 * 64MB





