Прежде чем обсуждать уплотнение, необходимо понять три ключевых концепции:
LSM-деревья обеспечивают высокую пропускную способность записи благодаря последовательной записи и фоновому уплотнению. Стратегия уплотнения определяет основной компромисс между производительностью записи, производительностью чтения и потреблением ресурсов. Традиционные LSM-деревья используют две основные стратегии уплотнения: Size-Tiered Compaction (послойное по размеру) и Level Compaction (уровневое).
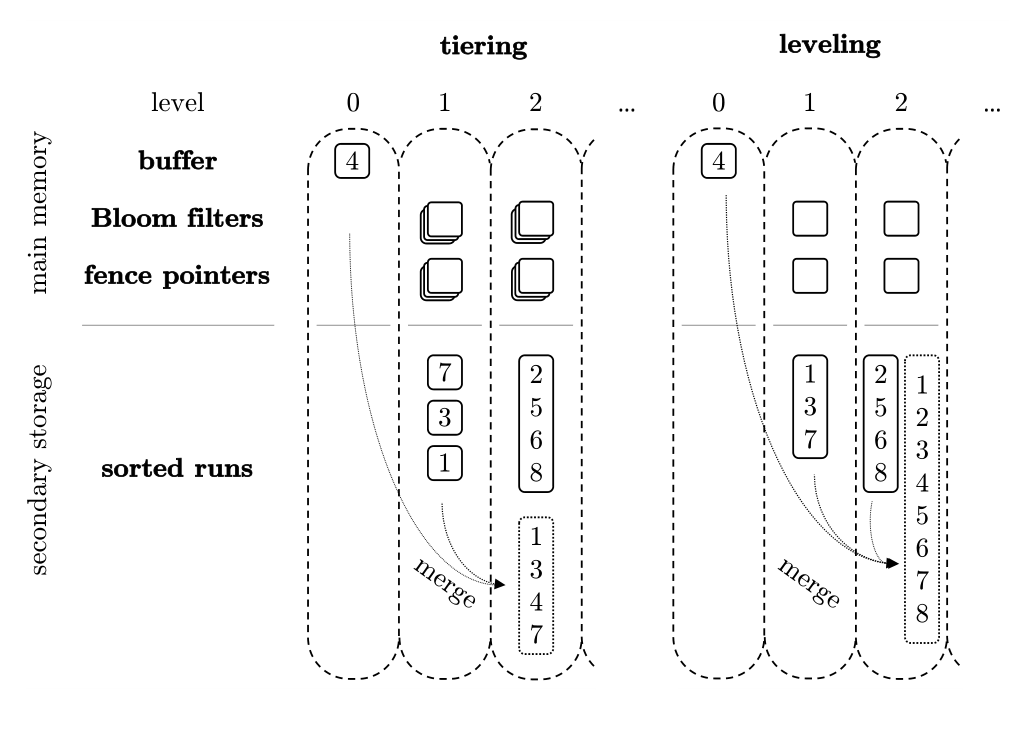
В этой стратегии SSTables в пределах одного уровня могут перекрываться. SSTables схожего размера объединяются в пакеты для создания более крупных SSTables без строгого требования непересекающихся диапазонов на каждом уровне.
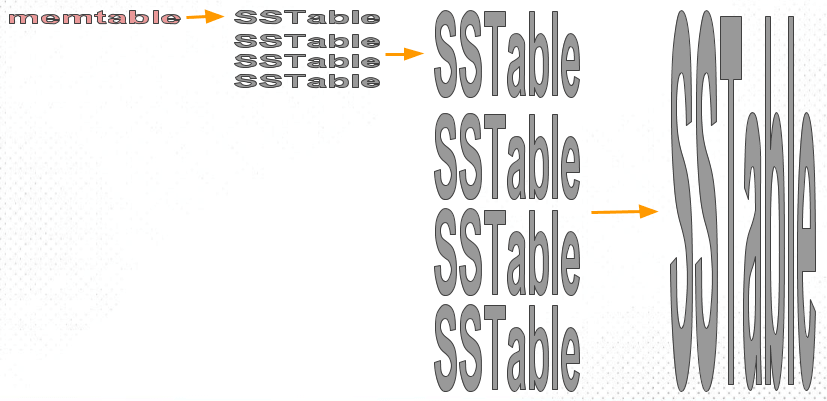
Стратегия послойного уплотнения по размеру (STCS) объединяет SSTables схожих размеров в новый файл. По мере сброса memtables на диск в виде SSTables, они начинаются как небольшие файлы. По мере роста количества небольших файлов и достижения порога, STCS уплотняет их в файлы среднего размера. Аналогично, когда количество файлов среднего размера достигает порога, они уплотняются в большие файлы. Этот рекурсивный процесс непрерывно генерирует все более крупные файлы.
Основные принципы:
Пример: Предположим, что каждая SSTable содержит 4 ключа.
SST-A: [1 – 4]SST-B: [5 – 8]SST-C: [3 – 10].Структура Уровня 0: [1–4], [5–8], [3–10]
C перекрывается с A по ключам 3–4.C перекрывается с B по ключам 5–8.Запрос key=6 требует сканирования нескольких файлов, что иллюстрирует усиление чтения. При послойном уплотнении слияние запускается, когда количество файлов на уровне достигает порога, выдавая один большой файл (например, [1 – 10]).
Таким образом, преимуществом является быстрая запись с низким усилением записи, но недостатком является то, что запросы должны сканировать несколько файлов, что приводит к усилению чтения.
SSTables в пределах каждого уровня стремятся быть непересекающимися (непересекающиеся диапазоны ключей). Если возникает перекрытие, SSTable верхнего уровня и все перекрывающиеся SSTables нижнего уровня объединяются и перезаписываются.
При уровневом уплотнении каждый уровень состоит из упорядоченных Run SSTables, поддерживая отсортированные отношения между ними. Когда размер данных уровня достигает своего лимита, он сливается с Run следующего уровня. Этот подход уменьшает количество Run на уровень, минимизируя усиление чтения и пространства. Использование небольших SSTables позволяет выполнять гранулярное разделение задач и контроль, где контроль размера задачи эффективно контролирует использование временного пространства.
Основные принципы:
Пример: Используя тот же сценарий, при обнаружении перекрытий ([1–4], [5–8], [3–10]) происходит немедленное слияние для получения [1–10]. Затем оно разделяется на [1–5] и [6–10] для обеспечения непересекающихся интервалов внутри уровня.
Таким образом, преимуществом являются быстрые запросы (сканирование максимум одного файла), но недостатком является высокое усиление записи, непрерывное фоновое уплотнение и высокая нагрузка на ввод-вывод.
| Измерение | Tiered (Послойное) | Leveling (Уровневое) |
|---|---|---|
| Перекрытие внутри уровня | Допускается | Не допускается |
| Стоимость записи | Очень низкая | Средняя-Высокая |
| Стоимость запроса | Высокая | Очень низкая |
| Усиление записи | Низкое | Высокое |
| Нагрузка на I/O | Легкая | Тяжелая |
| Стабильность задержки | Плохая | Хорошая |
| Основная цель | Пропускная способность | Время отклика |
MARS3 использует стратегию послойного уплотнения (Tiered Compaction). В типичных рабочих нагрузках временных рядов (VIN + TS) непрерывная запись приводит к тому, что новые Run широко перекрываются с несколькими Run на нижних уровнях в пространстве ключей. Поддержание непересекающихся уровней с помощью уровневого уплотнения становится затруднительным, часто вызывая масштабные перезаписи. Это приводит к значительному усилению записи, которое еще больше усугубляется в сценариях MPP с множеством экземпляров.
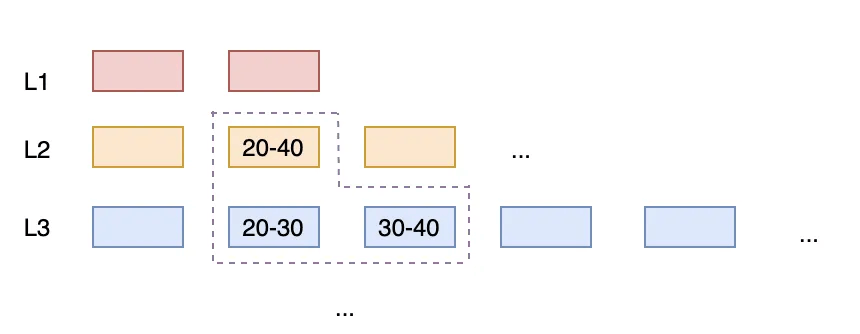
Сценарий: Предположим, три устройства (VIN=A, B, C) непрерывно сообщают последние значения. В системе уже существует слой Уровня 1 (L1), где каждый файл охватывает определенный временной диапазон для VIN:
A:[0 ~ 999], A:[1000 ~ 1999]B:[0 ~ 999], B:[1000 ~ 1999]C:[0 ~ 999], C:[1000 ~ 1999]Поступление новых данных:
TS = 1500 ~ 1700TS = 1600 ~ 1800TS = 1400 ~ 1650Эти новые записи формируют новый Run (например, в L0 или на верхнем уровне), называемый NewRun. NewRun содержит последние временные срезы для A, B и C, охватывая примерно:
A:[1500 ~ 1700]B:[1600 ~ 1800]C:[1400 ~ 1650]Анализ перекрытий:
A:[1000 ~ 1999].B:[1000 ~ 1999].C:[1000 ~ 1999].Следовательно, один NewRun перекрывается с несколькими файлами L1 (по одному на каждый VIN).
Если одновременно пишут 10 000 VIN, один NewRun может перекрываться с сотнями или тысячами файлов L1. Уровневое уплотнение требует, чтобы файлы L1 были непересекающимися. Поэтому слияние NewRun в L1 потребует чтения NewRun плюс всех перекрывающихся файлов L1, их повторной сортировки и записи новых файлов L1 для сохранения свойства непересекаемости.
Даже если новая запись мала (например, 1 ГБ), если она затрагивает множество исторических сегментов, она вовлекает огромные объемы исторических данных (например, 10 ГБ, 50 ГБ или 100 ГБ) для перезаписи, вызывая сильное усиление записи.
Напротив, послойное уплотнение по размеру (Size-Tiered Compaction) не требует непересекающихся нижних уровней. Оно в основном объединяет Run схожих размеров. Оно не вовлекает大量 (большое количество) файлов нижнего уровня исключительно для устранения перекрытий. Таким образом, в этом сценарии усиление записи значительно снижается.
Кроме того, Run в MARS3 представляют собой колоночные структуры, требующие достаточной физической непрерывности для обеспечения пропускной способности сканирования и эффективности сжатия. Это конфликтует с мелкой гранулярностью SSTables, часто используемой в уровневом уплотнении. Послойное уплотнение по размеру лучше подходит для этой рабочей нагрузки: оно объединяет Run одинакового размера, значительно снижая усиление записи. Кроме того, при потоках данных, прогрессирующих во времени, оно естественным образом формирует организацию Run, кластеризованную по времени, делая фильтрацию по времени и пропуск сканирования (skip-scans) более эффективными.
Для контроля усиления чтения MARS3 ограничивает коэффициент усиления чтения на каждом уровне. Как только этот коэффициент превышен, запускается уплотнение на нижний уровень.
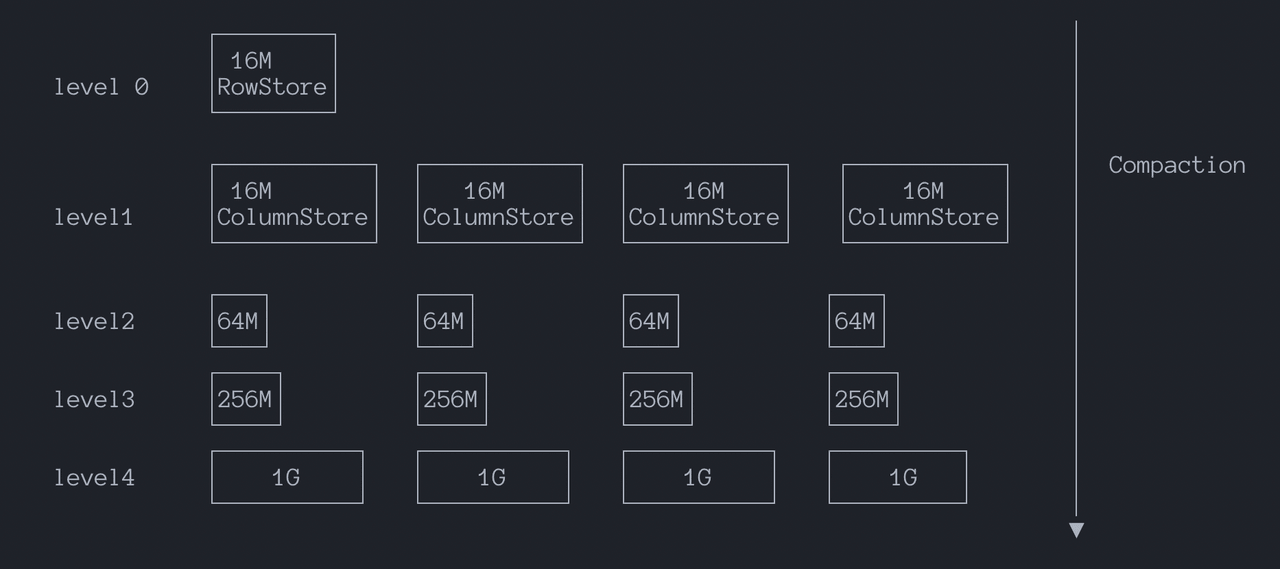
Параметр level_size_amplifier задает коэффициент усиления для размеров уровней.
Порог для запуска слияния на конкретном уровне рассчитывается как: rowstore_size * (level_size_amplifier ^ (level - 1)).
По сути, level_size_amplifier контролирует, насколько каждый уровень может быть больше предыдущего. Верхние уровни действуют как буферы, а нижние уровни служат долгосрочным хранилищем.
Вместе rowstore_size и level_size_amplifier создают контролируемый ритм опускания данных. Это ограничивает накопление Run в модели Tiered, ограничивая усиление чтения при сохранении преимуществ пропускной способности записи. Подробнее см. раздел Наблюдаемость.
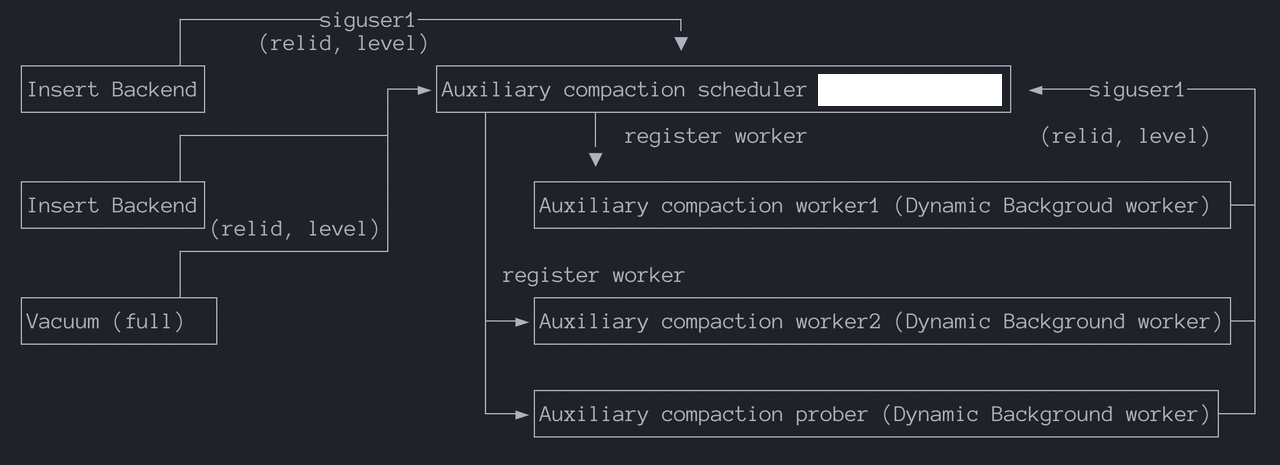
Планировщик уплотнения (Compaction Scheduler): Постоянный вспомогательный процесс, запускаемый при старте базы данных. Когда rowstore достигает rowstore_size, система переключается на новый rowstore. Сигнал отправляется процессу планировщика через общую память, содержащий детали запроса на уплотнение (ID отношения и уровень). Планировщик отвечает за регистрацию новых воркеров для выполнения уплотнения.
Воркер уплотнения (Compaction Worker): Выполняет конкретные запросы на уплотнение. Если усиление чтения уровня превышает лимит, воркер уведомляет планировщик о новом запросе на уплотнение. Из-за текущих ограничений модели процессов максимальное количество воркеров уплотнения жестко закодировано и равно 16.
Зонд уплотнения (Compaction Prober): Активно опрашивает наличие задач уплотнения, таких как:
SIGUSR1 планировщику и записывает информацию о запросе на уплотнение (relid, level) в общую память.Когда несколько таблиц требуют уплотнения, но доступно только 16 воркеров, механизм приоритетов гарантирует, что «наиболее нуждающиеся» таблицы будут уплотнены своевременно. Факторы приоритета включают:
Autoprobe периодически сканирует все таблицы MARS3, вычисляя оценку на основе возраста транзакции, деленного на размер (age / size). Он выбирает top N уровней с наибольшими оценками для запуска задач сброса/уплотнения, эффективно сжимая исторические уровни.
Функция matrixts_internal.mars3_autoprobe_candidates() отображает уровни-кандидаты и их оценки:
adw=# SELECT * FROM matrixts_internal.mars3_autoprobe_candidates();
segid | datname | relname | level | nruns | age | bytes | score
-------+---------+-------------+-------+-------+------------+-----------+-----------------------
0 | adw | t_w0_nosort | 1 | 13 | 616005 | 49888440 | 0.012347650076851471
0 | adw | t_w0_nosort | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w3b_3key | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w1_1key | 1 | 7 | 329693 | 23821378 | 0.013840215288972788
...Поскольку Autoprobe всегда выбирает уровни с наивысшей оценкой, система использует внутреннюю защиту для повторно падающих задач, чтобы они не блокировали другие уровни-кандидаты. Если Autoprobe долго не продвигается, сначала проверьте журналы базы данных и состояние compact worker, затем обратитесь к администратору или в службу поддержки.
Параметры GUC:
mars3.autoprobe_period: Контролирует интервал зондирования в секундах. Значение > 0 включает его; 0 отключает (по умолчанию). Начните с 10 минут и настройте в зависимости от рабочей нагрузки.mars3.autoprobe_workers: Контролирует, сколько уровней выбирается за одно зондирование (по умолчанию: 2). Примечание: Они занимают стандартные слоты воркеров уплотнения; новые воркеры не создаются.mars3.autoprobe_retry: Контролирует попытки повторения. Значение 2 означает всего 3 попытки.Влияние отключения Autoprobe: Таблицы без новых записей не будут подвергаться уплотнению. Таблицы с активными записями продолжат слияние в обычном режиме.
Для таблиц MARS3 команда VACUUM может продвигать данные RowStore в ColumnStore и совместно с фоновым управлением очищать версии данных, которые больше не видимы. Рассмотрите выполнение VACUUM в следующих случаях:
VACUUM FULL выполняет более сильную реорганизацию пространства и слияние Run, но требует более сильных блокировок и может создавать высокую нагрузку ввода-вывода. Используйте его, когда данные в основном стабильны и есть окно обслуживания. Не рекомендуется часто выполнять его во время постоянного пика записи.
Если в таблице постоянно выполняются UPDATE или DELETE, Delta-файлы и невидимые версии могут некоторое время расти. Фоновый compaction постепенно освобождает это пространство. Решение о дополнительном VACUUM или VACUUM FULL принимайте на основе наблюдений через matrixts_internal.mars3_level_stats и matrixts_internal.mars3_files.
Проверьте статус воркеров:
ps aux | grep postgres | grep 'compact worker'Убедитесь, что все воркеры работают. Ищите процессы, которые работают долгое время без завершения, что может указывать на аномальное поведение системы.
Журналы базы данных также содержат информацию об активности уплотнения. Создайте таблицу t1 и непрерывно вставляйте данные:
postgres=# CREATE TABLE t1(id int, info text)
USING mars3 WITH(mars3options='prefer_load_mode=single,rowstore_size=64');
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLEОткройте новое окно и непрерывно мониторьте состояния уровней с помощью matrixts_internal.mars3_level_stats:
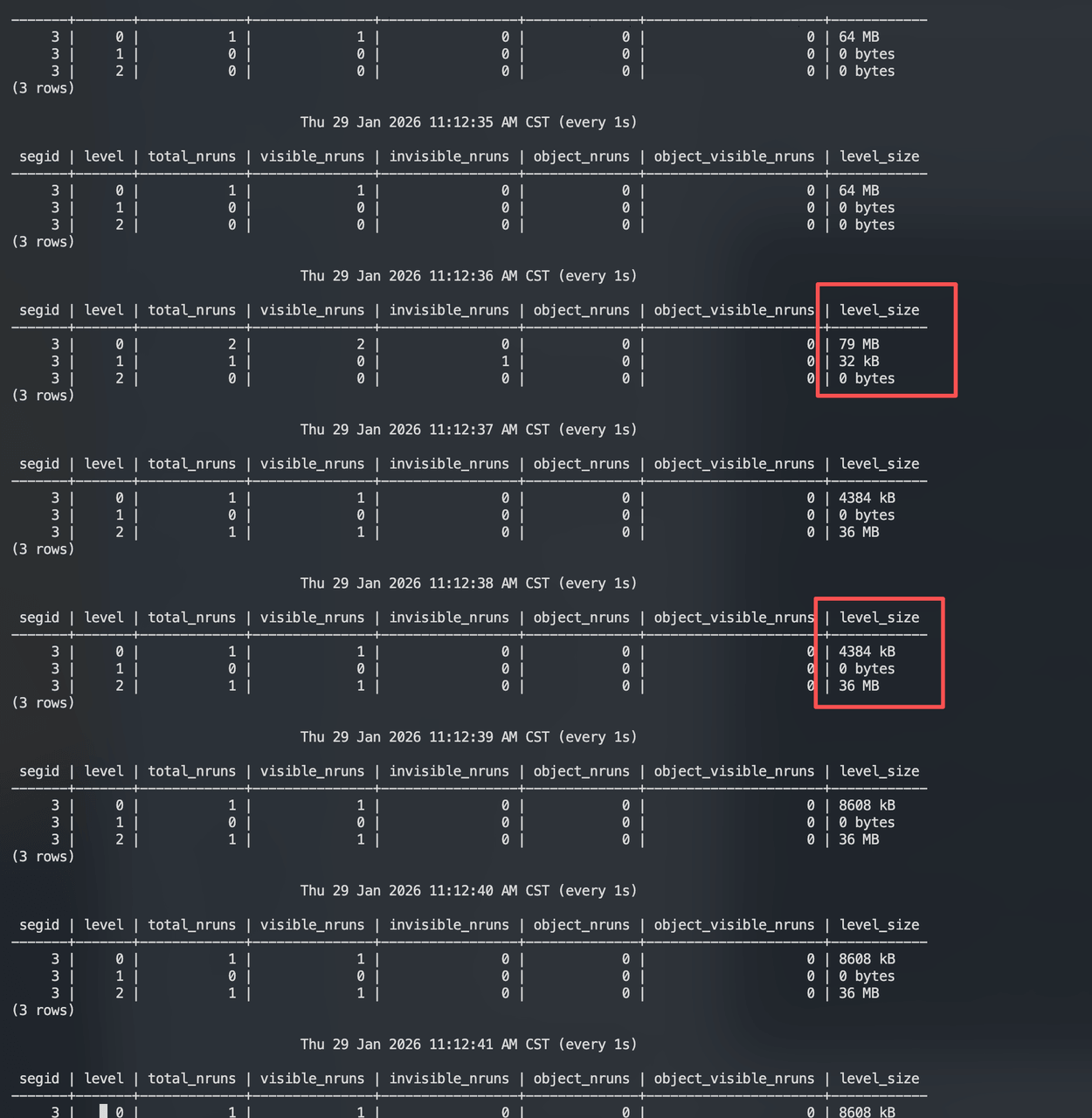
Наблюдение: После заполнения L0 до 64 МБ (rowstore_size), L1 кратко показывает 32 КБ, и данные записываются напрямую в L2. Последующие записи также идут напрямую в L2. Почему не сначала в L1?
MARS3 включает логику «Корректировки уровня» (GetDesiredLevel):
desired_level) для Run на основе его TotalSize.cur_level) отличается, он блокирует Run и перемещает его на целевой уровень.Поток вычислений:
run_size ≈ rowstore_size = 64 МБ.total_amp = run_size / rowstore_size = 64 МБ / 64 МБ = 1.0.desired_level = log(1.0) / log(8) = 0.Теоретический относительный уровень равен 0.
if (desired_level < 0) {
ret = desired_level < -0.5 ? 1 : 2;
} else {
ret = Min(2 + round(desired_level), MAXLEVELS - 1);
}Поскольку desired_level = 0, выполняется ветвь else:
round(0) = 0.ret = 2 + 0 = 2 (с учетом защиты верхнего предела Min).Результат: GetDesiredLevel() возвращает 2. Согласно новым правилам, Run размером 64 МБ принадлежит L2.
В модели Tiered MARS3 стабильный геометрический рост достигается не путем строгого мгновенного обеспечения общего размера на уровень, а путем позволяя уплотнению постепенно выравнивать целевые размеры Run с коэффициентом усилителя. Основные пороги для запуска уплотнения:
threshold(level) = rowstore_size × amp^levelthreshold(level) = rowstore_size × amp^(level - 1)Здесь bytes_threshold оценивает размер входного набора для операции уплотнения/выбора (pick). Уплотнение выбирает N Run, чей total_size приближается к bytes_threshold.
Рассчитанные пороги (предполагая rowstore_size=64МБ, amp=8):
Применяется ограничение Min(MAX_RUN_SIZE, ...). Если рассчитанный размер превышает MAX_RUN_SIZE, предел ограничивается, чтобы предотвратить чрезмерно большие задачи или выходные Run.
Мотивация А: Стабилизация модели геометрического роста.
rowstore_size представляет гранулярность rowstore.level-1 в формуле и добавляет +2 в классификации Run, чтобы выровнять базовую линию модели на более стабильные слои. Инженерный принцип: Не используйте самый нестабильный слой в качестве линейки.Мотивация Б: Экспоненциальное масштабирование задач с верхними пределами.
Мотивация В: Настраиваемый контроль усиления чтения.
level_size_amplifier означает более быстрый рост порога → менее частое уплотнение → более плавная запись.Используя пример таблицы t1, наблюдайте, когда L2 запускает «Выбор» (Pick). Согласно модели расчета, L2 должен запускать уплотнение около 512 МБ.
Thu 29 Jan 2026 02:42:07 PM CST (каждую 1с)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 64 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 15 | 15 | 0 | 0 | 0 | 533 MB
3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 bytes
(4 строки)
Thu 29 Jan 2026 02:42:08 PM CST (каждую 1с)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 2 | 2 | 0 | 0 | 0 | 69 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 15 | 15 | 0 | 0 | 0 | 533 MB
3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 bytes
(4 строки)
Thu 29 Jan 2026 02:42:09 PM CST (каждую 1с)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 16 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 16 | 16 | 0 | 0 | 0 | 577 MB
3 | 3 | 1 | 0 | 1 | 0 | 0 | 32 kB
(4 строки)
Thu 29 Jan 2026 02:42:10 PM CST (каждую 1с)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 16 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 16 | 16 | 0 | 0 | 0 | 626 MB
3 | 3 | 1 | 0 | 1 | 0 | 0 | 32 kB
(4 строки)
...
...
Thu 29 Jan 2026 02:42:26 PM CST (каждую 1с)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 32 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 16 | 16 | 0 | 0 | 0 | 626 MB
3 | 3 | 1 | 0 | 1 | 0 | 0 | 467 MB
(4 строки)
...
...
Thu 29 Jan 2026 02:43:58 PM CST (каждую 1с)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 32 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 1 | 1 | 0 | 0 | 0 | 36 MB
3 | 3 | 1 | 1 | 0 | 0 | 0 | 531 MB
(4 строки)
Thu 29 Jan 2026 02:43:59 PM CST (каждую 1с)
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
3 | 0 | 1 | 1 | 0 | 0 | 0 | 32 MB
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
3 | 2 | 1 | 1 | 0 | 0 | 0 | 36 MB
3 | 3 | 1 | 1 | 0 | 0 | 0 | 531 MB
(4 строки)Анализ журналов и явлений:
14:42:07 ~ 14:42:08
L0: 1 Run, 64 МБL2: 15 Run, 533 МБL1: 0L3: 014:42:09 ~ 14:42:10
L0: Возврат к 16 МБ (накопление нового Run).L2: 16 Run, 577 → 626 МБ (добавлен новый Run).L3: 1 Run, невидимый=1, 32 КБ.14:42:26
L2: 16 Run, 626 МБ.L3: Невидимый Run растет с 32 КБ → 467 МБ.14:43:58 ~ 14:43:59 (Завершение)
L2: 1 Run, 36 МБ.L3: 1 Run, 531 МБ (Видимый).L0: 32 МБ (Накопление нового Run RowStore).Вывод: Уплотнение завершено и зафиксировано.

Примечание: bytes_threshold для L0 равен 0, так как он сбрасывается напрямую; эта метрика менее значима для L0.
RunLife-Flushed используется для отладки кода для отслеживания жизненного цикла Run:
RunLife-Created: RUN создан.RunLife-Flushed: RUN прочитан и сброшен.RunLife-Recycled: RUN переработан и использован повторно.
Вернуться к предыдущему разделу: Принципы движка хранения