Начало работы
Подключение
Тесты производительности
Развёртывание
Использование данных
Управление кластерами
Обновление
Глобальное обслуживание
Масштабирование
Мониторинг
Безопасность
Лучшие практики
Технические принципы
Типы данных
Хранилище
Исполняющий движок
Потоковая обработка (Domino)
MARS3 Индексы
Расширения
Расширенные функции
Расширенный запрос
Федеративные запросы
Grafana
Резервное копирование и восстановление
Аварийное восстановление
Графовая база данных
Введение
Предложения
Функции
Расширенные темы
Руководство
Настройка производительности
Устранение неполадок
Инструменты
Параметры конфигурации
SQL-команда
Часто задаваемые вопросы
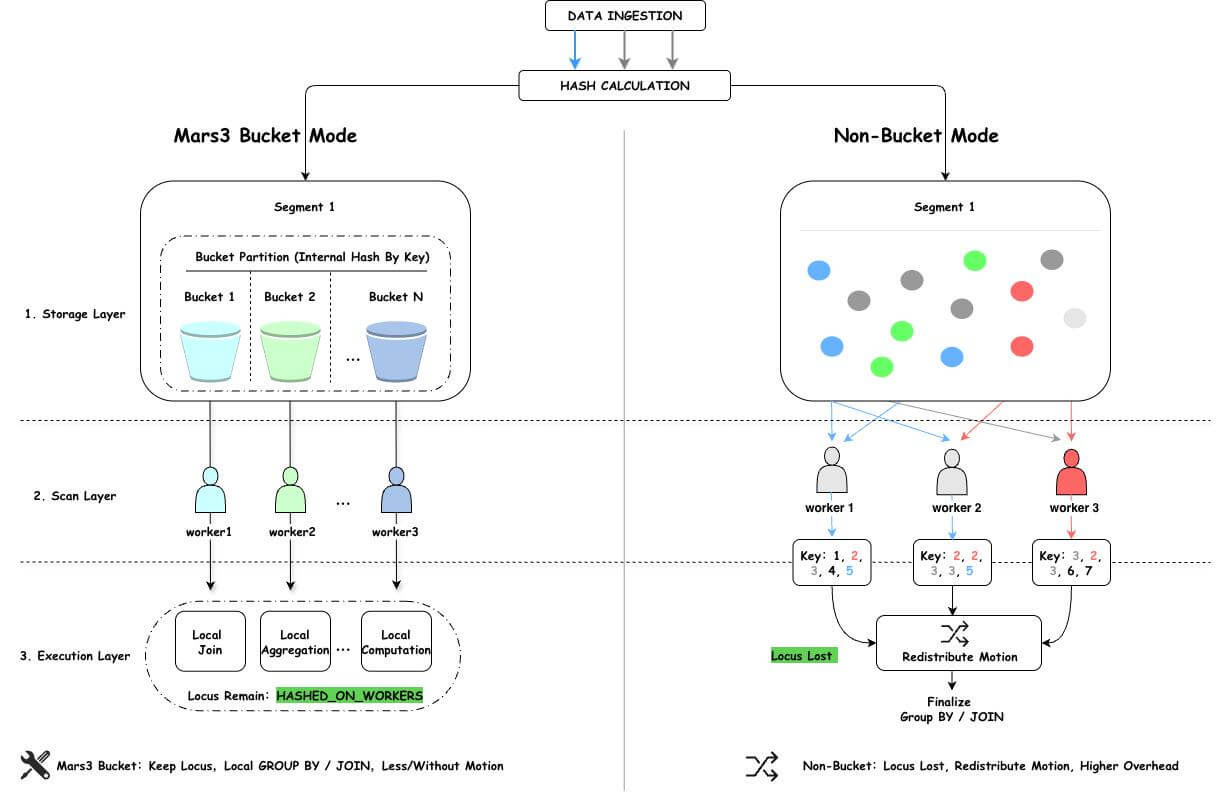
MARS3 Bucket — это механизм оптимизации параллельного выполнения на уровне хранения, разработанный YMatrix для сценариев параллельного сканирования в MPP-архитектурах. Во время записи данные организуются в несколько логических бакетов на основе хеш-значений ключа распределения. Это гарантирует, что данные с одинаковым ключом распределения будут обрабатываться одним и тем же рабочим процессом при параллельном сканировании. Такой подход сохраняет семантику распределения данных (locus), устраняет ненужную перераспределку данных (Motion) и обеспечивает переход от «более быстрого сканирования» к «более локальным вычислениям».
Bucket в первую очередь подходит для больших таблиц, которые выигрывают от параллельного сканирования, особенно для таблиц с hash-распределением, где агрегации или соединения используют ключ распределения и важно избежать лишнего Motion. Для небольших таблиц, временных таблиц или таблиц, которые редко сканируются параллельно, Bucket обычно дает ограниченную пользу и может увеличить накладные расходы на файлы, метаданные и фоновое управление.
При настройке nbuckets учитывайте следующие рекомендации:
nbuckets не должно превышать число CPU-ядер на узле, деленное на число Segments на узле.rowstore_size и размером таблицы; избегайте bucket меньше 2 МБ.nbuckets при создании таблицы. Последующее изменение nbuckets переписывает всю таблицу и не рекомендуется как регулярный способ тюнинга.nbuckets для них не дает эффекта.Цель MARS3 Bucket — сохранить строгую локальность данных после параллельного сканирования, чтобы максимум вычислений выполнялся локально.
Помимо традиционного распределения, которое определяет, на каком узле хранятся конкретные данные, MARS3 Bucket дополнительно организует данные внутри каждого узла в структурированные бакеты. Это гарантирует, что данные из одного бакета будут выдаваться одним рабочим процессом.
Основное отличие подхода MARS3 Bucket от стандартного параллельного сканирования с прерыванием по страницам заключается в упорядоченности обработки внутри segment. Параллельное сканирование переходит от простого одновременного чтения данных несколькими рабочими процессами к совместному чтению данных в соответствии с семантикой распределения.
Рассмотрим таблицу t_sales с ключом распределения c1. Выполняется следующий SQL-запрос: select c1, count(*) from t_sales group by c1;
В стандартном параллельном сценарии (без режима Bucket) план выполнения выглядит так:
Gather Motion 12:1
-> Finalize HashAggregate
Group Key: c1
-> Redistribute Motion 12:12
Hash Key: c1
-> Partial HashAggregate
Group Key: c1
-> Parallel Seq Scan on t_salesc1 будут обработаны одним рабочим процессом.c1 может оказаться у нескольких рабочих процессов даже после частичной агрегации, данные необходимо перераспределить по c1, чтобы обеспечить корректность финальной агрегации.Проще говоря: проблема не в самом методе распределения таблицы, а в том, что параллельное сканирование нарушает исходные правила распределения данных, необходимые для прямой агрегации. Чтобы исправить это, оптимизатор добавляет дополнительный шаг перераспределения данных, что напрямую снижает ожидаемую выгоду от параллельного выполнения.
При использовании MARS3 Bucket план выполнения упрощается:
Gather Motion 12:1
-> HashAggregate
Group Key: c1
-> Parallel Custom Scan (MxVScan) В базе данных YMatrix данные распределяются и хранятся на различных узлах данных (Segments) согласно определённым правилам. Все данные на этих узлах в совокупности образуют полный набор данных. При создании таблицы необходимо указать ключ распределения. Во время вставки система вычисляет хеш-значение по этому ключу и сопоставляет результат с конкретным узлом данных. Таким образом, если таблицы используют один и тот же ключ распределения, одинаковые данные гарантированно размещаются на одном и том же узле. Это позволяет выполнять такие операции, как соединения и агрегации по ключу распределения, преимущественно локально, без перемещения данных. Такое явление называется совместной локальностью данных.
С точки зрения всей таблицы, YMatrix использует MPP-архитектуру, где процессы сканируют данные на каждом Segment. Такой уровень параллелизма называется параллелизмом на уровне экземпляра.
С точки зрения конкретной таблицы внутри отдельного Segment, сканирование данных может выполняться одновременно несколькими процессами. Такой уровень параллелизма называется внутриузловым параллелизмом.