В MARS3 ключ сортировки является критически важным элементом проектирования, определяющим способность движка хранения достигать оптимальной эффективности сканирования и поддерживать долгосрочную стабильность. Упорядоченные данные в сочетании с надежными метаданными на уровне блоков значительно повышают производительность сканирования.
Основные преимущества ключей сортировки можно разделить на пять категорий:
WHERE тесно согласуются с ключом сортировки (например, диапазоны времени, диапазоны ID устройств), данные демонстрируют более сильную кластеризацию на уровне хранения. Запросы могут раньше и точнее пропускать нерелевантные блоки данных, снижая потребление ресурсов ввода-вывода и процессорного времени.Организуйте данные, используя измерения запросов, которые являются наиболее распространенными и обеспечивают наибольший эффект фильтрации. На практике выбор ключа сортировки обычно сочетает два измерения:
Столбцы, часто используемые в условиях фильтрации, должны располагаться в начале ключа сортировки.
WHERE, как самый левый префикс ключа сортировки.Короче говоря, убедитесь, что наиболее распространенные условия запроса могут сузить диапазон сканирования до непрерывных, кластеризованных интервалов.
Рассмотрим реальный кейс клиента в сценарии временных рядов со следующим запросом:
SELECT time_bucket_gapfill ('5 min', time) AS bucket_time,
locf (LAST (value, time)) AS last_value,
locf (LAST (quality, time)) AS last_quality,
locf (LAST (flags, time)) AS last_flags
FROM
xxx
WHERE
id = '116812373032966284'
AND type = 'ANA'
AND time >= '2025-11-16 00:00:00.000'
AND time <= '2025-11-16 23:59:59.000'
GROUP BY
bucket_time;Результаты показывают, что различные ключи сортировки значительно влияют на производительность сканирования по индексу, функционируя аналогично составным индексам.
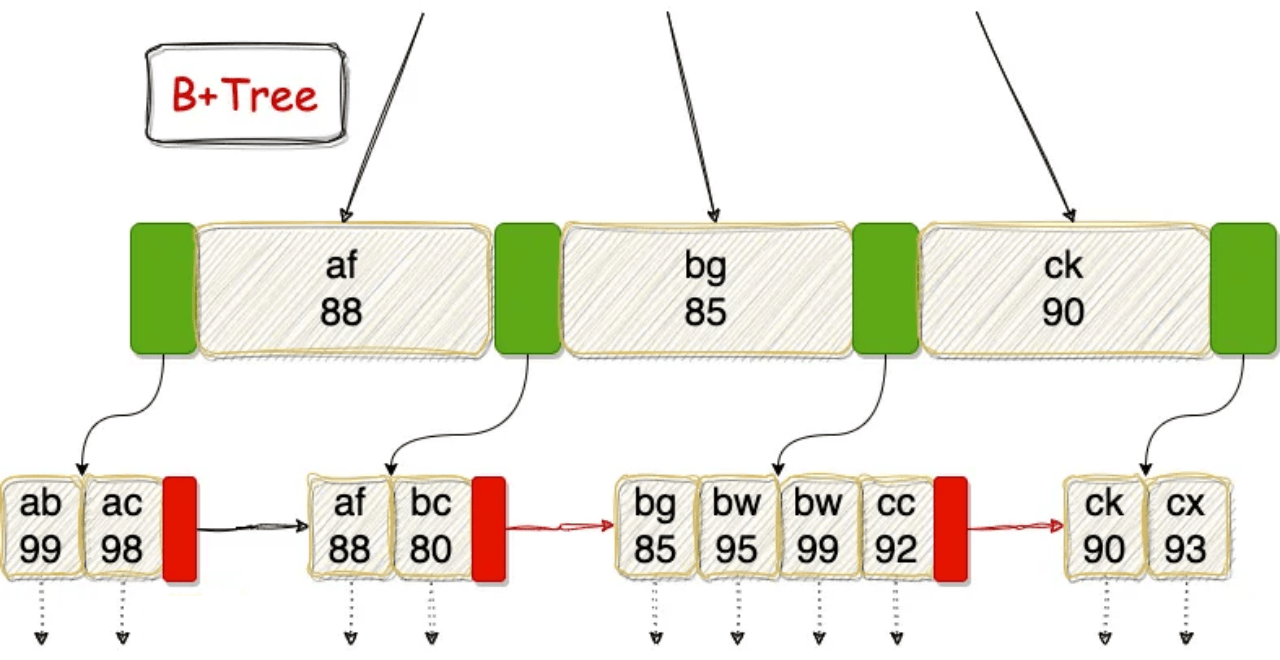
Когда поле времени стоит первым, кортежи с одинаковым ID разбросаны по пространству хранения во времени. Следовательно, сканирование по индексу должно выполнять множество случайных чтений для получения соответствующих блоков данных. Однако, когда ID стоит первым, все кортежи, принадлежащие одному и тому же ID, хранятся в соседних locations. Это резко снижает случайный ввод-вывод, так как сканированию по индексу нужно прочитать лишь несколько смежных блоков.
Данные сортируются во время преобразования из Rowstore в Columnstore. Сам Rowstore не отсортирован; однако, если в Rowstore существует B-Tree индекс, этот индекс остается упорядоченным. Указание ключа сортировки влечет следующие накладные расходы:
Отсутствие указания ключа сортировки позволяет избежать этих расходов, часто приводя к более легким операциям записи. Однако ключи сортировки также влияют на естественную организацию данных на диске:
CREATE TABLE t_w0_nosort (
id bigint NOT NULL,
k1 bigint NOT NULL, -- Высокая кардинальность
k2 smallint NOT NULL, -- Низкая кардинальность
k3 bigint NOT NULL, -- Монотонный столбец (имитация инкремента через bigint)
v1 double precision NOT NULL,
v2 double precision NOT NULL,
payload text NOT NULL -- Контролирует объем записи: рекомендуется 256Б/1024Б
) USING mars3;
CREATE TABLE t_w1_1key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k3);
CREATE TABLE t_w3a_3key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k1, k3, k2);
CREATE TABLE t_w3b_3key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k3, k1, k2);Создание промежуточного набора данных:
DROP TABLE IF EXISTS t_src_s;
CREATE TABLE t_src_s USING MARS3 AS
SELECT
g AS id,
(hashint8(g)::bigint) AS k1,
(g % 64)::smallint AS k2,
g AS k3,
(g % 1000) * 0.01 AS v1,
(g % 10000) * 0.001 AS v2,
repeat('x', 256) AS payload
FROM generate_series(1, 200000000) g;
TRUNCATE t_w0_nosort;
\timing on
INSERT INTO t_w0_nosort SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w1_1key;
\timing on
INSERT INTO t_w1_1key SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w3a_3key;
\timing on
INSERT INTO t_w3a_3key SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w3b_3key;
\timing on
INSERT INTO t_w3b_3key SELECT * FROM t_src_s;
\timing offПерезапустите базу данных после каждого теста для сравнения времени записи:
adw=# TRUNCATE t_w0_nosort;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w0_nosort SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 76859.371 ms (01:16.859)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w1_1key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w1_1key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 82864.008 ms (01:22.864)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w3a_3key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w3a_3key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 106929.500 ms (01:46.930)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w3b_3key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w3b_3key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 83456.346 ms (01:23.456)
adw=# \timing off Время записи:
t_w0_nosort (без сортировки): 76.859 сt_w1_1key (ORDER BY k3): 82.864 сt_w3a_3key (ORDER BY k1,k3,k2): 106.930 сt_w3b_3key (ORDER BY k3,k1,k2): 83.456 сПропускная способность:
t_w0_nosort: 200,000,000 / 76.859 ≈ 2.60 млн строк/сt_w1_1key: 200,000,000 / 82.864 ≈ 2.41 млн строк/сt_w3a_3key: 200,000,000 / 106.930 ≈ 1.87 млн строк/сt_w3b_3key: 200,000,000 / 83.456 ≈ 2.40 млн строк/сНакладные расходы относительно отсутствия сортировки:
Размещение монотонного столбца k3 в качестве первого ключа сортировки снижает стоимость записи при многоколоночной сортировке почти до уровня одноколоночной сортировки.
Размещение случайного столбца с высокой кардинальностью k1 первым значительно увеличивает затраты на запись.
Почему «Без сортировки» быстрее всего? Избегание сортировки, сравнений и поддержки упорядоченности минимизирует накладные расходы на фоновую запись, устанавливая базовую пропускную способность (2.60 млн строк/с).
Почему ORDER BY (k3) лишь немного медленнее?
Входной поток уже является инкрементальным по k3. Поскольку ключ сортировки совпадает с порядком ввода, система в основном выполняет последовательную запись с минимальными дополнительными накладными расходами на поддержку метаданных, что приводит к замедлению всего на ~8%.
Почему ORDER BY (k1,k3,k2) значительно медленнее?
Сортировка приоритизирует k1, который является столбцом с высокой кардинальностью и близким к случайному распределением. Это рассеивает весь поток записи по пространству ключей:
Почему ORDER BY (k3,k1,k2) сопоставимо по производительности с сортировкой по одному столбцу?
Первый ключ сортировки k3 совпадает со входным потоком, позволяя системе максимально использовать естественный порядок:
k3.k1 и k2 участвуют в более глубоких сравнениях только тогда, когда значения k3 идентичны или очень близки, что значительно снижает давление сравнений и пересортировки.
Следовательно, его производительность почти идентична ORDER BY (k3) (2.40 млн против 2.41 млн строк/с).adw=# \dt+
List of relations
Schema | Name | Type | Owner | Storage | Size | Description
--------+-------------+-------+---------+---------+---------+-------------
public | t_default | table | mxadmin | mars3 | 160 kB |
public | t_sort_bad | table | mxadmin | mars3 | 103 MB |
public | t_sort_good | table | mxadmin | mars3 | 35 MB |
public | t_src_s | table | mxadmin | mars3 | 3040 MB |
public | t_w0_nosort | table | mxadmin | mars3 | 2769 MB |
public | t_w1_1key | table | mxadmin | mars3 | 2764 MB |
public | t_w3a_3key | table | mxadmin | mars3 | 3453 MB |
public | t_w3b_3key | table | mxadmin | mars3 | 2764 MB |
public | testmars3 | table | mxadmin | mars3 | 160 kB |
(9 rows)Вернуться к предыдущему разделу: Принципы движка хранения