
智能化水平持续升级的自动驾驶系统,因为搭载先进的传感器、终端设备等装置,在车辆运行过程中产生海量数据,比如油耗、车速、路线、行驶轨迹、行驶里程、驾驶员监控等。能够管理好并利用好这些数据,对于驾驶安全和车辆智能化水平的持续升级有重要意义。
近日,YMatrix受邀参加由中国汽车工程研究院、中国汽车信息化推进产业联盟等共同主办的中国智能网联汽车创新成果大会,获评 “中国智能网联汽车创新成果奖”。

会上,YMatrix创始人兼CEO姚延栋从项目架构和实践案例出发,发表《超融合时序数据库 YMatrix Database 智能网联汽车的数据基座》主题演讲,以下为部分内容节选:

在所有“不确定性”中,最大的确定是我们已经处在了“数字化时代”。
在 Statista 2021 的报告中提到,全球联网的物联网设备已经超过了非物联网设备,数据产生的范式已经发生了根本性变化。
过去的数据是由人、动作所产生,而未来将由设备主动产生。以今天我们讨论的汽车交通场景为例,每一秒的行车轨迹,包括车速、车胎等车辆信号都是实时产生。设备产生的数据量在未来几年将会远超人力所产生的数据。

麦肯锡提出,预计到2026年,数据市场规模将会达到1000亿美金。
聚焦到汽车市场,能够管理好并利用好这些数据,对于驾驶安全和车辆智能化水平的持续升级有重要意义。
先明确一个概念:什么是超融合数据库?
和专用库支持单一场景不同,我们的超融合数据库 YMatrix 通过微内核(microdb)技术架构,可以实现一库多用,在一套数据库架构之上,对多模态数据、多场景类型、多种复杂查询需求提供统一支持,帮助企业大幅降低数据基础设施的采购、使用及运维门槛。
YMatrix Database的架构逻辑是为物联网时代而设计的。在新场景下,根据DB-Engines对数据库流行度排名的调研,时序数据高居榜首。所以,支持时序数据场景,是我们超融合底座做的第一件事情。
目前,YMatrix产品的海量数据采集、存储、复杂分析和计算的能力,已经成功在智能网联汽车、智能制造、工业互联网、智慧能源、智慧城市等领域得到验证。
尤其是在汽车行业,我们与宁德时代、理想汽车、北理新源、小米制造、比亚迪等汽车领域企业建立了友好的合作关系,共同进行了充分的落地探索。
有研究报告指出,90%的企业拥抱数字化的同时,仍有80%的企业转型是失败的。因为从技术角度来看,企业在数字化转型时采纳的技术栈,特别是数字技术,都是为“上一个时代而设计的”。
上一个时代是信息化时代和互联网时代,这些技术栈已经不适应未来新场景下的需求,所以必然经历试点炼狱,造成大量的精力消耗。

具体到数据库领域,上一个周期的主流技术栈存在三大问题:
1、碎片化非常严重。碎片化造成数据孤岛,没办法建立全局、实时的数据驱动。
2、慢。解决单一场景的数据库是快的,但几乎所有的用户都是复合场景,使用时需要叠加多种产品使用,像电脑组装机一样,更多的客户需要的是一个品牌机。
3、复杂。技术栈的复杂给用户带来最直接的影响就是“门槛高”,复杂度是造成人才困难的重要原因之一。想解决人才问题,最根本就是降低复杂度,让它变得所有人都很容易去学。
其中,复杂还可以从数据多样化和场景多样化两个角度来理解。
· 数据多样化:从年代较久远的关系数据,到相对较新的时序数据、GIS 数据或激光雷达数据等,数据类型的多样化不断拓展。
· 场景多样化:传统以Oracle为代表的数据库,以增删改查为主。但在物联网时代,需要更多的场景支持,除增删改查外,还需要查询最新值等。比如,一辆汽车的最新位置在哪里?最新车速是多少?昨天从9-10点的行车轨迹,在轨迹行驶过程中,一共踩多少次油门?这些信息可以作为明细数据查询,当然其他还有维度查询,分析型查询及Machine Learning查询等。
要降低技术栈的复杂,就要从各种DIY数据库拼搭起来的模式,走向 All-in-one的超融合架构。YMatrix Database的研发团队相信奧卡姆剃刀原理:“如无必要,勿增实体”。
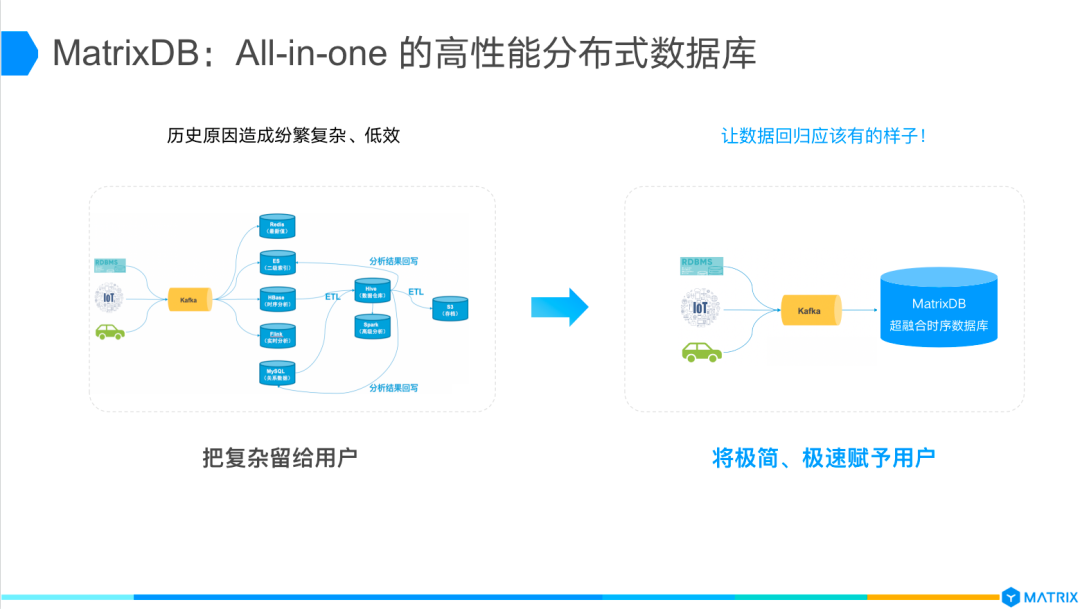
一个数据库可以完成的事情,就不需要使用其他的数据库处理。要把“极简”、“极速”留给用户,把复杂度留给数据库开发人员。
近年来,车联网场景对数据存储性能的要求不断提高,汽车的用户数据,车辆数据,场景数据,该如何进一步实现快速采集、快速拿到和快速进行处理分析,让数据价值被充分挖掘,是当前遇到的三大问题。
数据库是智能网联汽车的“基础底座”,有两个关键点:
第一,数据采集要打通全链路。没有链路,车上数据发不出来,其实就像一个没有联网的电脑一样。
一张简单的架构图,其实充满很多的挑战。汽车的采集数据频率是不一样的,发动机、电池的采集指标是毫秒级;车速数据是秒级;还有车内温度数据,可能是秒级甚至是分钟级。这些数据以不同的频率,高速实时发布到数据中心,挑战是很大的。
之所以把架构画的如此简单,是因为我们把挑战都压到数据库一侧。
第二,数据需要分批的。一次采集 300 个指标,不同指标的价值是不一样的,比如其中100个指标需要秒级使用、实时查询,另外200个指标则是每10秒或1分钟才发送。这些存在数据库里同一时刻发生的数据,就像一张Excel表,都是在一行的,这叫分批上传。
当然,还有乱序延迟数据,一辆车进入无人区,或进入没有信号的车库里,数据上传不了。当从无信号地区进入到有信号地区,需要把这辆车的最新信号实时上传,老的延迟数据会随后发出。怎么让数据库能够“无缝支持”就显得尤为重要了。
有了数据支撑后,可以从很多方面去提升业务价值,比如:
· 充电桩选址:通过每辆汽车每秒钟的位置信息数据,找到最高效、最经济的地方设充电桩。
· 后市场服务:车辆所有数据实时地传送到数据中心,主机厂售后服务人员依托数据,提升售后体验或延长产品生命周期。
比如,警示灯提示胎压报警,车主并不知道是气候影响导致的胎压低于阈值,还是因为车辆胎压确实是变低,需要补气。通常油车发生这样的问题需要开到4S店处理,而数字汽车有实时数据,可以拿出电话或使用手机查询,查看胎压是否在阈值以上或当前车胎阈值是多少。
· 实时报警:车辆的某一些符合指标,连续5秒钟高于某一个阈值时,反向报警提示主机厂售后服务人员。
YMatrix 从主机厂客户收到的效果反馈显示:硬件成本节省 80%,大概节省 800 万的成本,同时我们还将数据延迟从以前高峰期2小时缩短到只需要 10 秒钟。

制造侧有三大类数据:第一大类是运营数据,比如 ERP 系统数据,一般是 TB 级的;第二大类是生产制造数据,比如 MES 系统数据。这两类都是关系数据。
第三类设备数据,一个工厂的设备数据大约是 ~10 万点/秒时序数据。
从设备到 DCS/SCADA 控制层、执行层、运营管控层,包括时序在内的各种结构化、非结构化数据,都可以采集到 YMatrix 里进行实时分析和决策。
每一台设备都会变成 PLC、DCS 或者 SCADA 等,通过各种各样的协议对互联网网关采集,然后互联网网关再通过API发到Kafka。我们可以通过MatrixGate去消费这些数据,实时记录在秒级毫秒级写入到数据库里面去。
数据库可以做BI报表、数字化应、监控分析,甚至机器学习等。
使用 YMatrix 后,工厂大脑方案的价值可以体现在3点:

· 节省硬件成本:以前是“用一个产品来解决一个问题”,现在从技术上是“一个产品解决几乎所有数据问题”。所以,仅使用YMatrix Database和几台服务器,就可以解决过去需要4-5个产品,数十台服务器才能解决的问题。硬件数量大幅减少后,成本自然而然下降
· 性能提升 6 倍
· 降低人才的门槛:做一个极简、极速的数据库,提供标准接口,只要团队懂 SQL,就可以轻松地玩转大数据。






