
时序类型数据无处不在,小到日常衣食住行所涉及的可穿戴设备、智慧农业、食品溯源、智能建筑、全屋智能、车联网、智慧交通,大到推动国家和城市发展的智能制造、能源科技和智慧城市,都在持续不断的生成时序数据。
为了更好的利用数据来赋能业务,越来越多的企业开始采集、利用、分析时序数据,试图通过数据背后所暗藏的逻辑,来赋能企业的精益化经营、智能决策、产品研发、用户服务,并最终实现增长和商业模式创新。
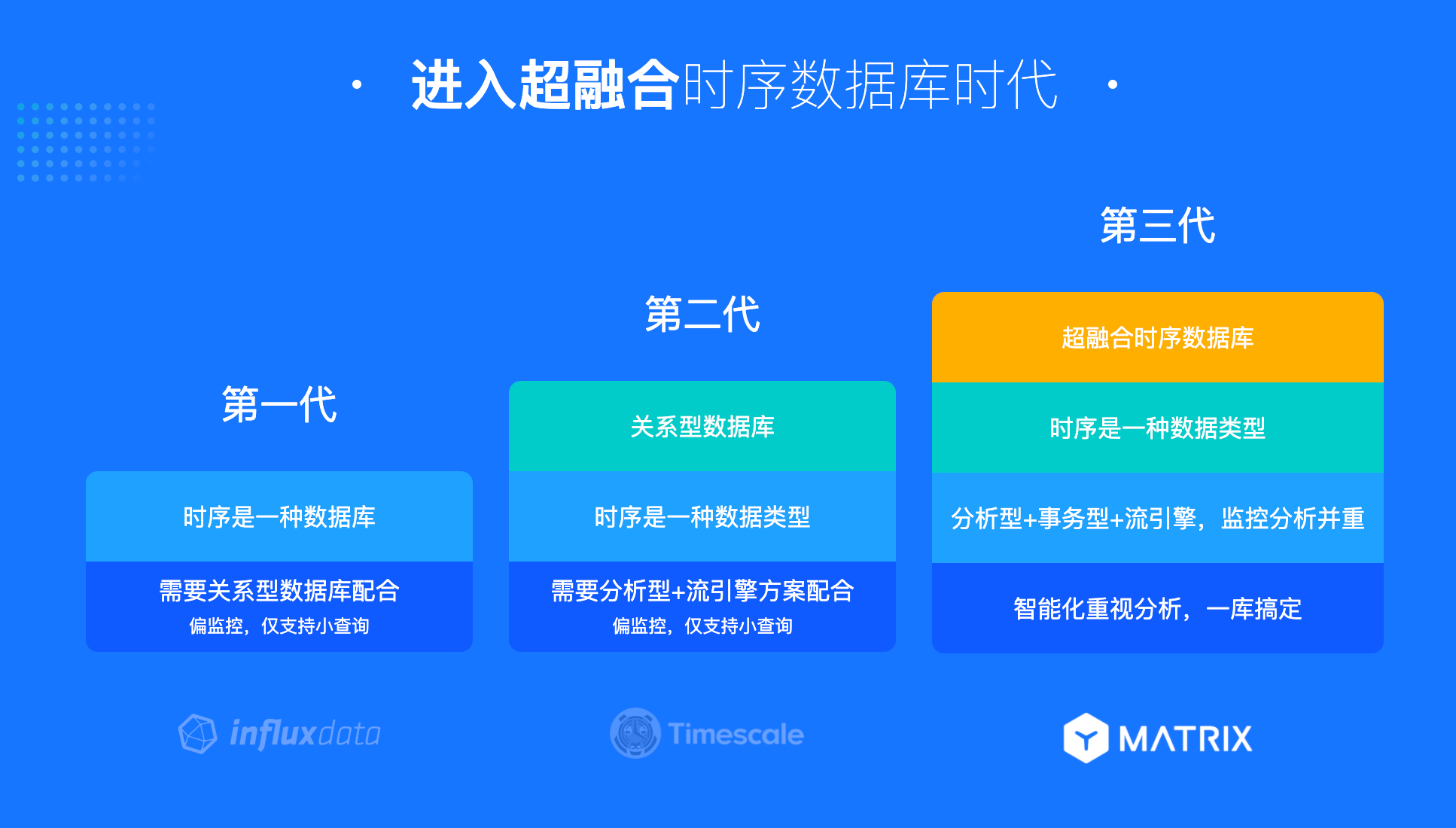
伴随时序数据价值的普及,数据管理技术的升级迭代,企业对存储、处理时序数据的数据库产品的期望也在不断调整。
早期时序数据应用面较窄,以证券交易为代表性应用场景,KDB是这个阶段的代表时序数据库,属于闭源商业产品,自定义语法非标准SQL,用户相对小众生态相对封闭,用户学习和使用难度大。这个时期的数据规模有限,大家对数据的重视程度也不够,有时还使用数据的有损压缩。另外,能源化工领域也是较早采用时序数据库的行业,国内应用较多的Pi数据库是这一场景的佼佼者。
目前,时序数据库经历演变发展,已经从封闭走向开放开源,从局部小数据规模应用到全行业大数据遍地开花,从单一监控到实时多维多模集成分析,成为数字化智能化的核心支撑。用户在选型时,需要从时序场景的特殊需求和通用数据库的普遍功能两个方面同时考虑,着眼未来,从功能、生态、用户体验等多维度综合评价。
近日,YMatrix发布《时序数据库选型指南》,对主流时序数据库进行了详尽的对比。为了便于客户选型时参考使用,所列出产品包含8大类、49小类的全功能比较,详细报告请下载 PDF全文。
部分报告内容节选如下:
2000 年后,随着互联网、大数据、容器和微服务技术的大发展,时序数据库的第一个大浪潮由 OpenTSDB 和 InfluxDB开启。
这个时期的应用,以软硬件的运维监控为代表性应用场景,数据模型和应用需求相对单一,只是数据规模变大,使用时序数据库的行业和用户变多。
OpenTSDB 和 InfluxDB 定位在只处理时序数据的专有时序数据库,又因为处于 Hadoop 和 NoSQL 流行的时期,所以在产品形态上都是 NoSQL 的模式,不具备事务能力,对资源使用比较粗放,产品功能有限,往往需要搭配事务和分析数据库使用。
其中,OpenTSDB 基于 HBase,技术栈复杂,数据需要两次 compact,写延迟波动大,所有数值都保存为 32位的float,无法准确表示 int 值,对时间类型仅支持毫秒精度;InfluxDB 的存储层经历过四次重写,依然面临很大的挑战,数据容易丢失、延迟大。
经过这个时期,时序数据库从封闭走向开源,大家对时序数据的特征、存储需求和查询类别有了清晰的认识,也形成了相应的性能评测标准。
2015 年后,用户逐渐认识到时序数据通常都不是独立存在的。以监控场景的 Zabbix 为例,Zabbix 的数据模型既需要收集存储大量时序数据,又需要保存和管理众多用户、主机、组件等实体对象和他们的关系。
针对这一需求,同时为解决前一时期的产品挑战,TimescaleDB 开启了时序数据库的第二个时代。在现有成熟的 PostgreSQL 数据库中,引入对时序特性的支持。
在多模时序数据库时代,类似 TimescaleDB 的产品包括 MongoDB 和 Cassandra。这些产品部分解决了数据孤岛问题,功能相对丰富,使得时序数据的应用场景开始拓展到物联网等新兴领域。
近年来,时序数据爆发式增长。时序数据的分析成为挖掘数据价值的刚需,数据入库和查询延迟对一些场景变得至关重要。同时,时序数据规模开始放大,许多场景设备数和指标数都有了数量级的提升。
以时序数据库为中心,“云-边-端”一体,融合时间变化、空间移动、相关实体、协同系统的长周期多维度数据,企业可获得 360 度全景实时数据。从数据管理视角来看,用户期待在一个数据库中完成时序全场景、流式加载、实时聚合与查询、高级分析和机器学习,充分利用时序数据降本增效、量化细化管理和科学决策、为安全生产保驾护航。
至此,时序数据库进入到一个融合数据分析、事务处理、流处理能力的第三代超融合数据库时代。
针对时序场景的需求,YMatrix 旗下超融合产品,在成熟稳定的 MPP 分布式分析型 PostgreSQL 架构之上,为时序场景量身定制存储和优化,为用户提供了高性能、智能化、简单易用的一站式时序数据平台。 在产品的实现上,InfluxDB 最近发布的新一代时序数据库产品特性的 13 条规划中,也印证了以上趋势。其中,有 12 条规划已经在 YMatrix 产品中已实现。






