_1746771022.png?x-oss-process=image/resize,h_300/format,webp/quality,q_80)
某头部 ERP 产商在 OpenAI 发布 GPT 不久,就已开始布局 AI 产品线, 随着 Deepseek 爆火,该厂商迅速在自有平台上发布 AI 智能体,产品迅速成为提升工作效能的重要工具,在完全落地客户场景前,充分证明了产品价值。
那么,这家公司究竟是如何基于 YMatrix,一步步搭建起属于自己的企业智能系统?又是如何在短短数月内,实现效率翻倍、业务创新加速?
本文将带你详细揭秘——
一文了解,企业智能升级的真实路径。
在大模型领域,从大火一整年的 GPT 再到横空出世的 Deepseek, 一代更比一代强,企服软件厂商也在紧跟这个风口,寻找 AI 时代的“增量”。从国际巨头 SAP 高举“商业 AI”大旗开始,企服软件厂商们在 AI 上的动作可以用“百花齐放”来形容,各家厂商都在用 AI 给自己贴上“智能”的标签,声称要颠覆企业管理、重塑商业未来。
市场上已有许多强大的通用大模型,这些模型具备强大的泛化能力,可以处理各种信息,然而这只是企业级智能化应用架构中的一部分。
🎉 大模型 + AI 数据库,才构成企业级智能化应用的基础架构!
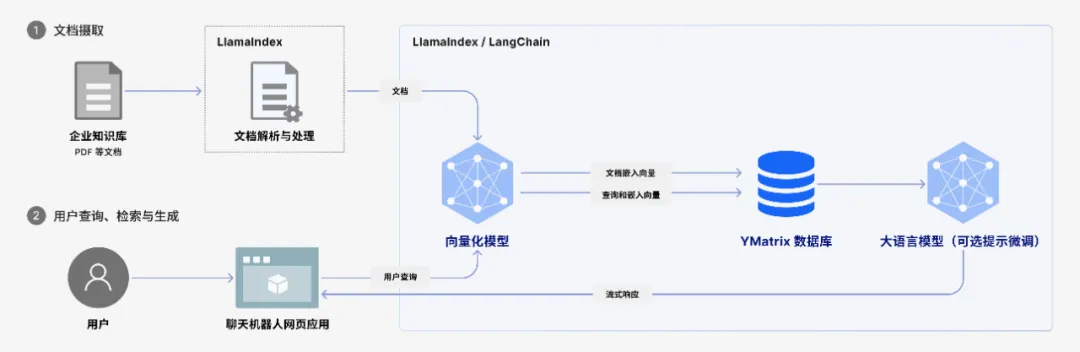
一个 GPT 不仅需要强大的大模型支撑,还必须依赖一个稳定、高效、灵活的数据引擎,缺少了“好用”的数据引擎,无法构建符合企服场景需求的 AI 产品。因此,产品落地于企业真实场景,除了大模型提供的 AI 能力,下一个要亟需解决的就是数据问题。
对于支撑大模型的数据引擎,这些要求是逃不开的:
向量检索能力:需要有能够提供向量检索能力的平台
信息更新能力:企业内部知识分散在文档、代码库、邮件等多个地方并会经常更新
更佳查询性能:作为用于企业内部的生产力工具,需要具备良好的性能和高峰期稳定服务的能力
所以,问题来了:
目前,在企服场景中,一方面 AI 能力更多的是作为产品的亮点出现,从务实的角度,多数企业并不愿意专门为 AI 能力花费大量投资,另一方面,面对迅速变化的市场,厂商也需要快速动作,避免在竞争中下风。
从大型企服软件厂商的视角来看,我们可以将企对 AI 数据库的需求总结为:
AI 能力:必须能够支持大规模向量检索,从而支持大模型从数据库中获取信息,这是支撑企服 AI 的基础
高效数据更新:企业的知识和业务数据是动态变化的,在大型企业中,更新可能更频繁,因此在具备 AI 能力的基础上,数据库还需要有较好的更新能力
快速响应与高并发:虽然 AI 并非高并发型应用,但大型企业也不可避免会出现高峰时段,因此,响应速度、并发能力也需要充分考虑。
落地快、成本低:现阶段,虽然客户都在拥抱 AI ,但预算都持谨慎态度,如何在现有产品架构上,以最快速度、最低成本的方式集成 AI, 已经不是“选修课”而是“必修课”了。
成果展示:仅用 6 个月时间,成功实现了“企业版 GPT”的上线
该产品在商业化运作之前,企业已在内部作为首个用户进行大量试用,目前,多个商业客户已经签约,在接下来会逐步实施上线,显示了强大的产品竞争力。
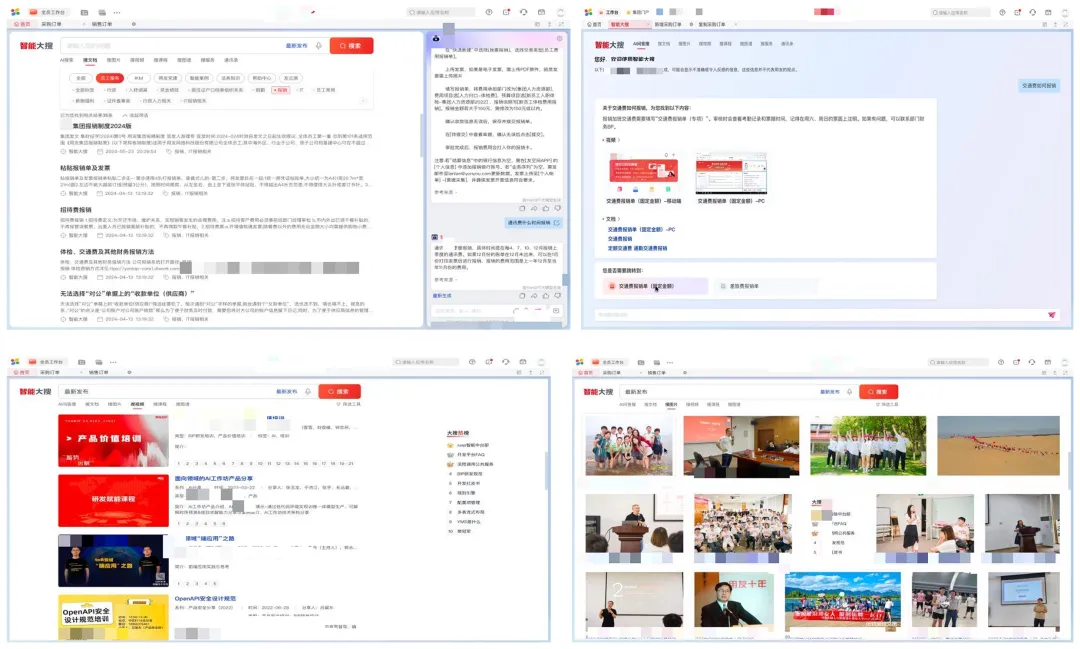
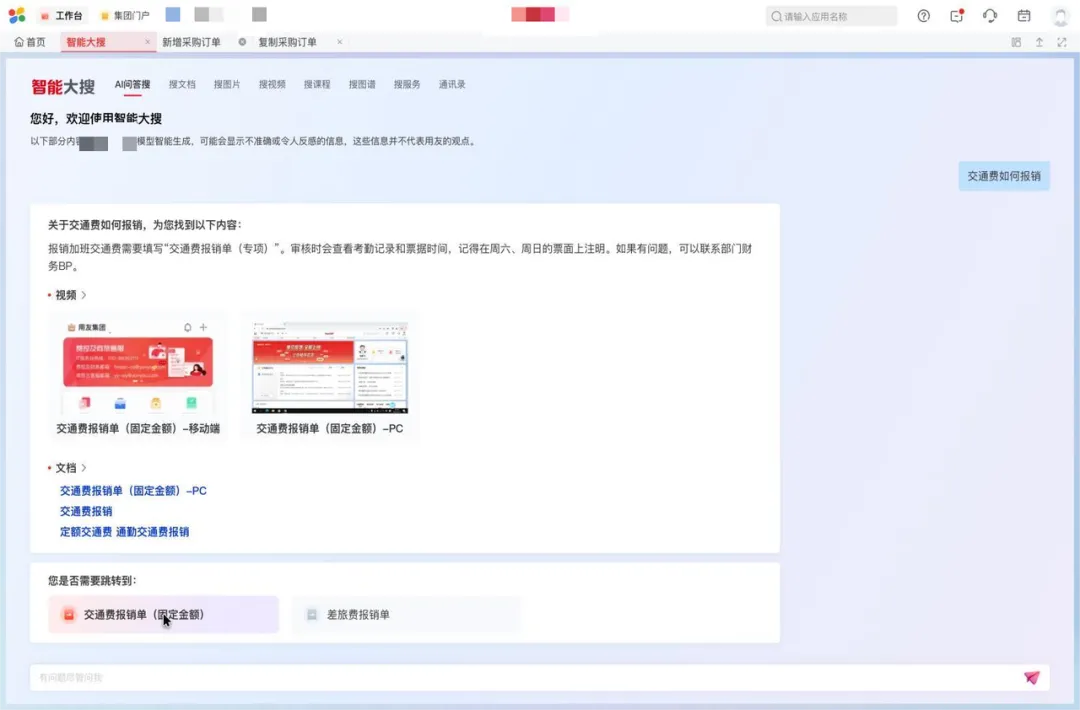
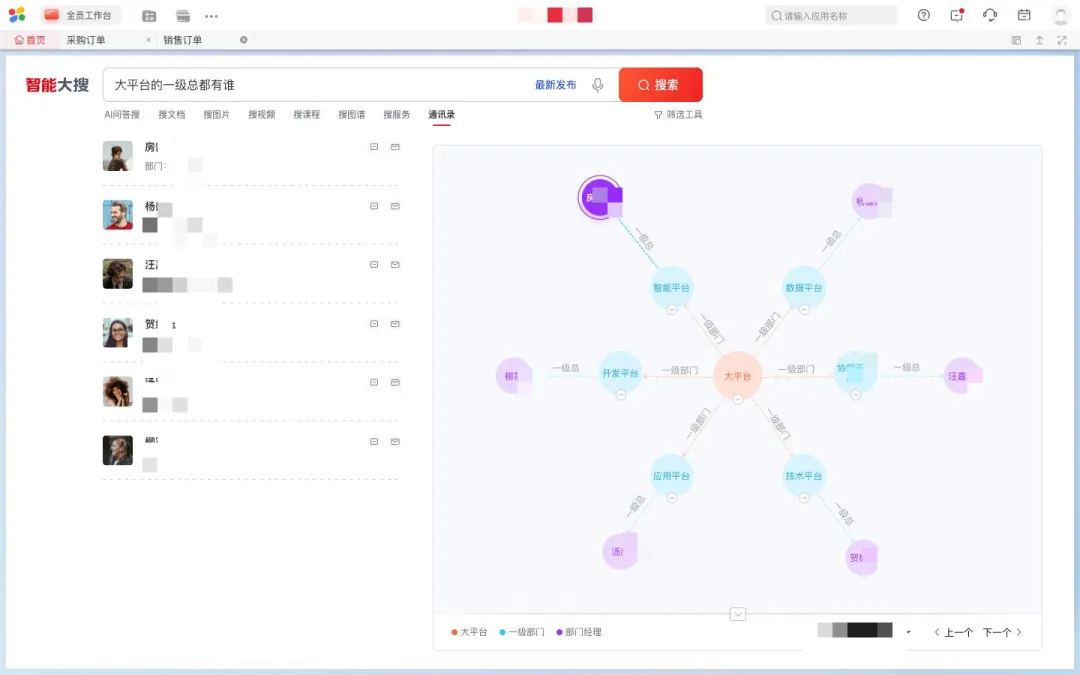
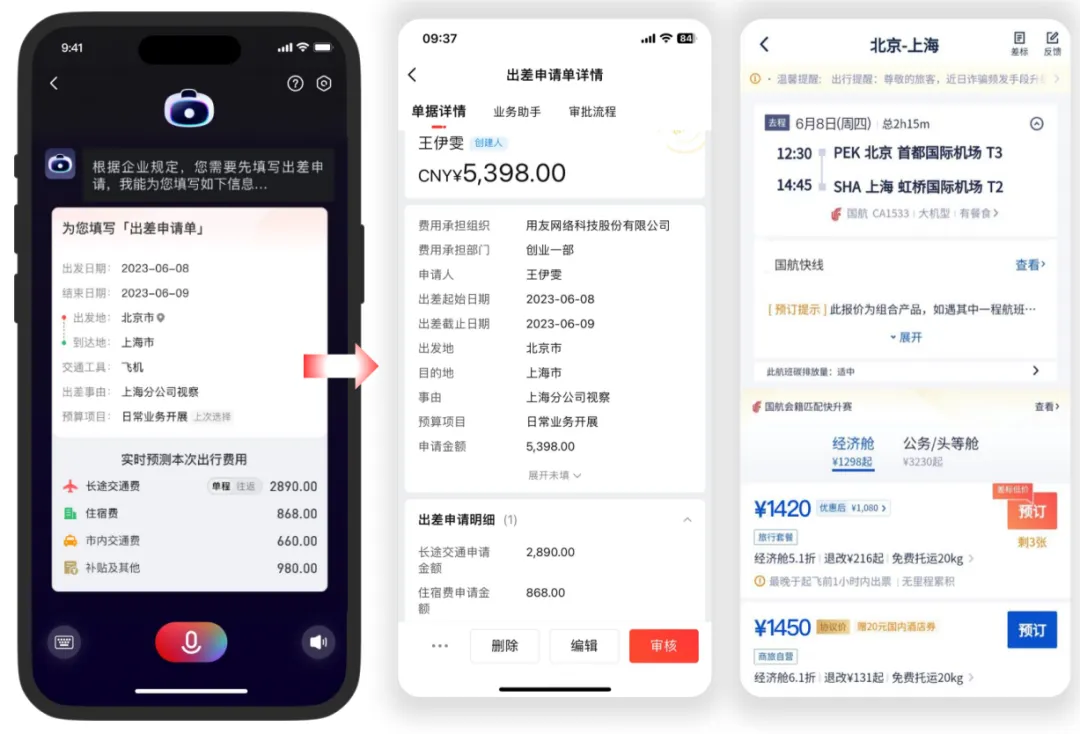
费控智能助理
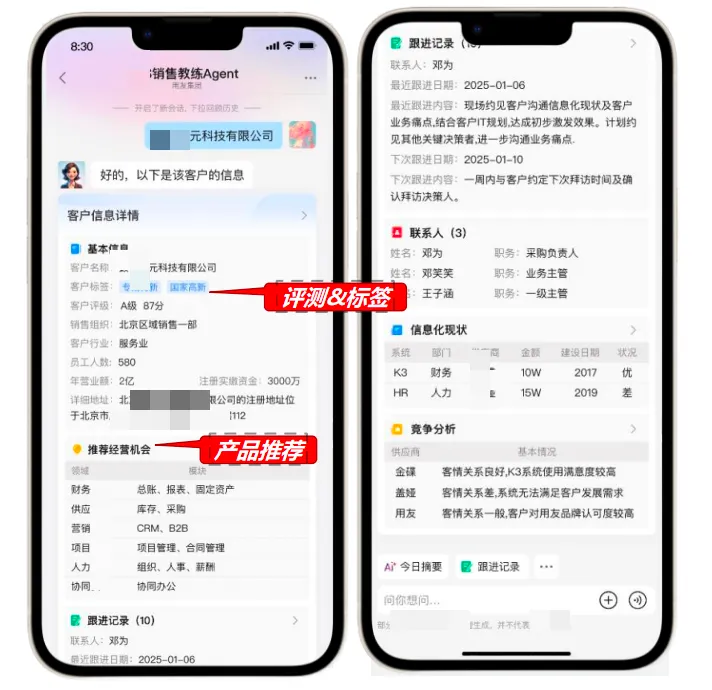
智能销售教练
YMatrix 超融合数据库作为底层数据引擎,为企业版 GPT 提供了强有力的支撑。
复用现有数据基础设施:YMatrix 作为超融合数据库,本身即具备向量能力,能够直接支持大模型调用。由于原有产品已经搭建于 YMatrix 之上,新增的 AI 功能可直接在原有数据库上直接开发,大大提升了产品迭代速度。
统一数据存储与智能处理: YMatrix 还支持多模态数据(文本、图片、视频等)的混合检索,使企业能够将所有内部数据统一存储至 YMatrix,不仅满足 AI 需求,还能不同传统场景下的软件产品对数据库的多样化需求。
分布式高效向量检索: YMatrix 本身是分布式数据库,能够通过水平扩展增加集群算力,AI 计算性能表现也能受益,能够在高并发情况依然提供秒级的响应速度,确保在大量员工同时访问时,系统依然保持高效稳定。
实时数据更新: YMatrix 的向量能力不仅体现在相应速度上,还体现在数据更新能力上。YMatrix 一方面在数据更新上有良好的性能表现,同时作为企业数据的统一平台,向量数据可直接在数据库内流转,在简化整体架构的同时,还能够大大提升数据更新的及时性。
这场内部变革深刻验证一个趋势:
“数字化转型的胜者,往往掌控着数据的命脉。在这场‘数据库+AI’的竞赛中,企业如何成为先行者,关键就在于能够驾驭数据的超级引擎。”
想要了解如何快速搭建属于自己的“企业版 GPT”?想要掌握 YMatrix 高效的智能玩法,让数据真正释放无穷的商业价值?
数智化转型,赢在数据。现在就联系我们,看看如何让你的企业迈上智能化新台阶!






