
作为一款高性能时序数据库,数据写入是最普遍场景,所以数据写入速度尤为重要。数据写入框架如下图所示:
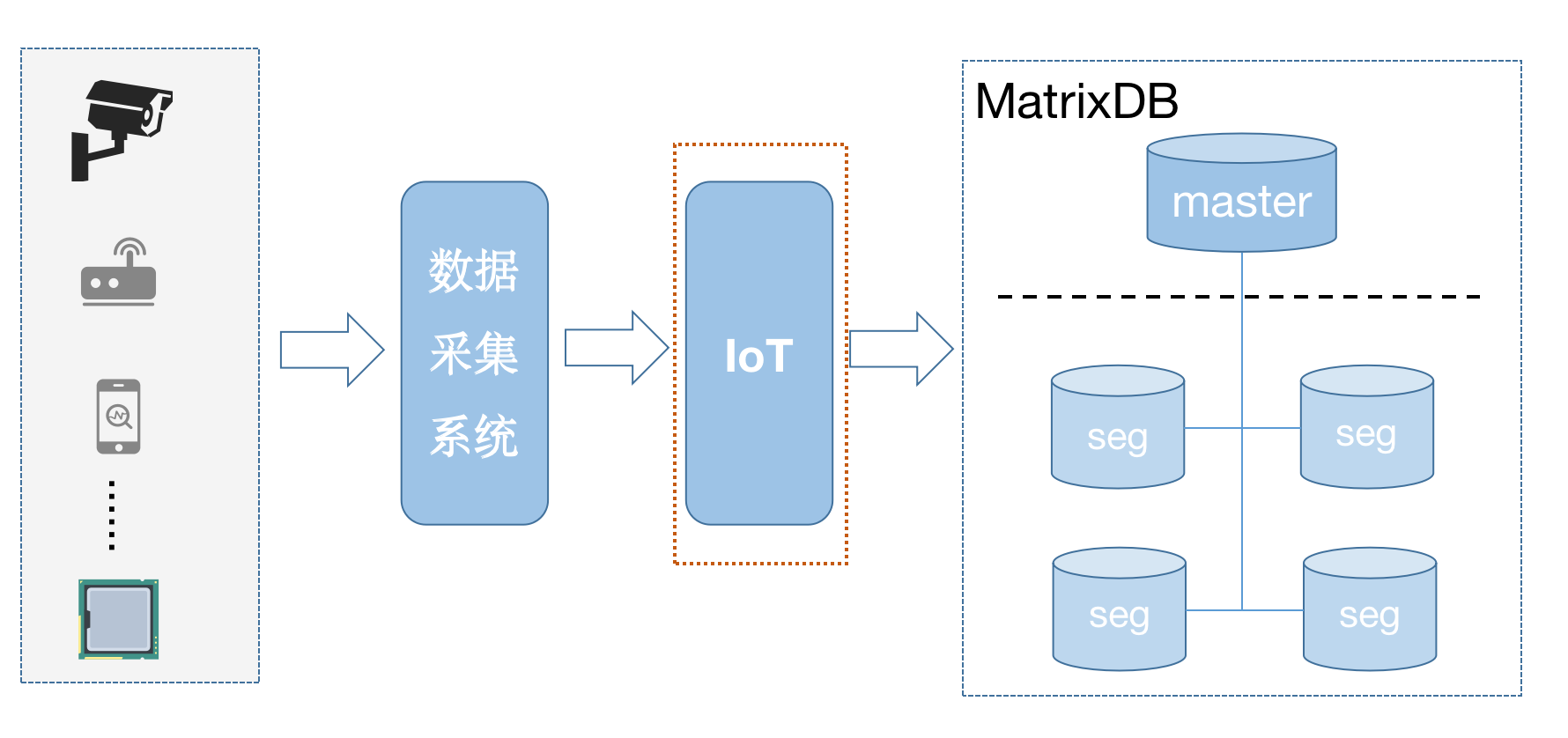 设备产生实时数据,通过数据采集系统发送到 IoT 网关,再写入到 MatrixDB 中。 为此,MatrixDB 专门开发了MatrixGate 组件,来优化数据写性能。本文将详细讲解 MatrixGate 的实现方式。
设备产生实时数据,通过数据采集系统发送到 IoT 网关,再写入到 MatrixDB 中。 为此,MatrixDB 专门开发了MatrixGate 组件,来优化数据写性能。本文将详细讲解 MatrixGate 的实现方式。
首先,先介绍一下 MatrixDB 进行数据写入的两种方式:
直接 INSERT,顾名思义,就是通过 INSERT INTO TABLE VALUES 语句插入数据,这是一种最基本最简单的方式,也是所有数据库都支持的方式。当今数据库系统在处理查询时都拥有高并发、低延迟的特性,尤其对于HTAP系统,这种方式在处理对吞吐量要求不是特别高的场景完全可以,比如两万行每秒或几十万数据点每秒。那么,当吞吐量逐渐加大,直接 INSERT 面临的问题是什么呢?这要从 MatrixDB 如何执行查询说起。
MatrixDB 是一款中心化分布式数据库系统,系统由 master 节点总控,负责客户端连接、查询执行路径生成、计划下发、结果汇总等。
对于一条 INSERT 语句,执行过程如下:
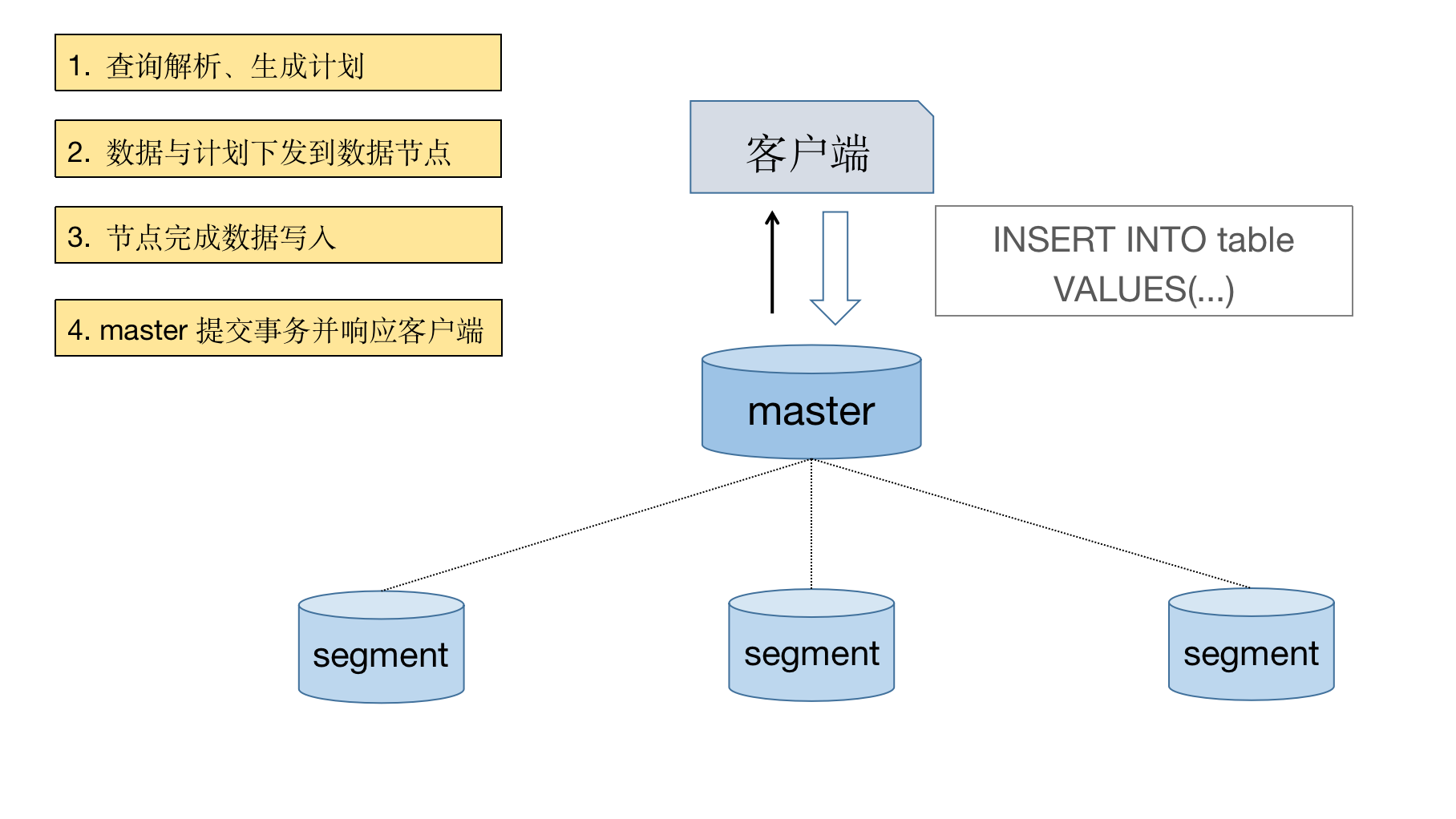 从上图执行INSERT流程可以看出:
从上图执行INSERT流程可以看出:
对于直接 INSERT 有一个小小的优化方法,就是批量插入,即每条 INSERT 语句 VALUES 后面跟多个行。 批量 INSERT 可以减少 master 做查询计划的次数,但是每条数据还是要通过 master 节点,进行解析与分发,master仍然是瓶颈。
MatrixGate 是 MatrixDB 提供的一个数据写入组件,目的是提高数据写入性能。其设计理念就是充分发挥分布式数据系统的优势,将数据解析的过程下发到了 segment。具体使用方式,请参考数据加载服务器 MatrixGate。
| 写入方式 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 直接INSERT | 接口简单 | 吞吐量低 | 吞吐量低,几十万数据点/秒 |
| MatrixGate | 吞吐量高,准实时 | 需要额外部署,有运维成本 | 吞吐量高,千万数据点/秒 |
本节详细介绍 MatrixGate 是如何做到高吞吐的。
首先要提到一种新的表类型,外部表。
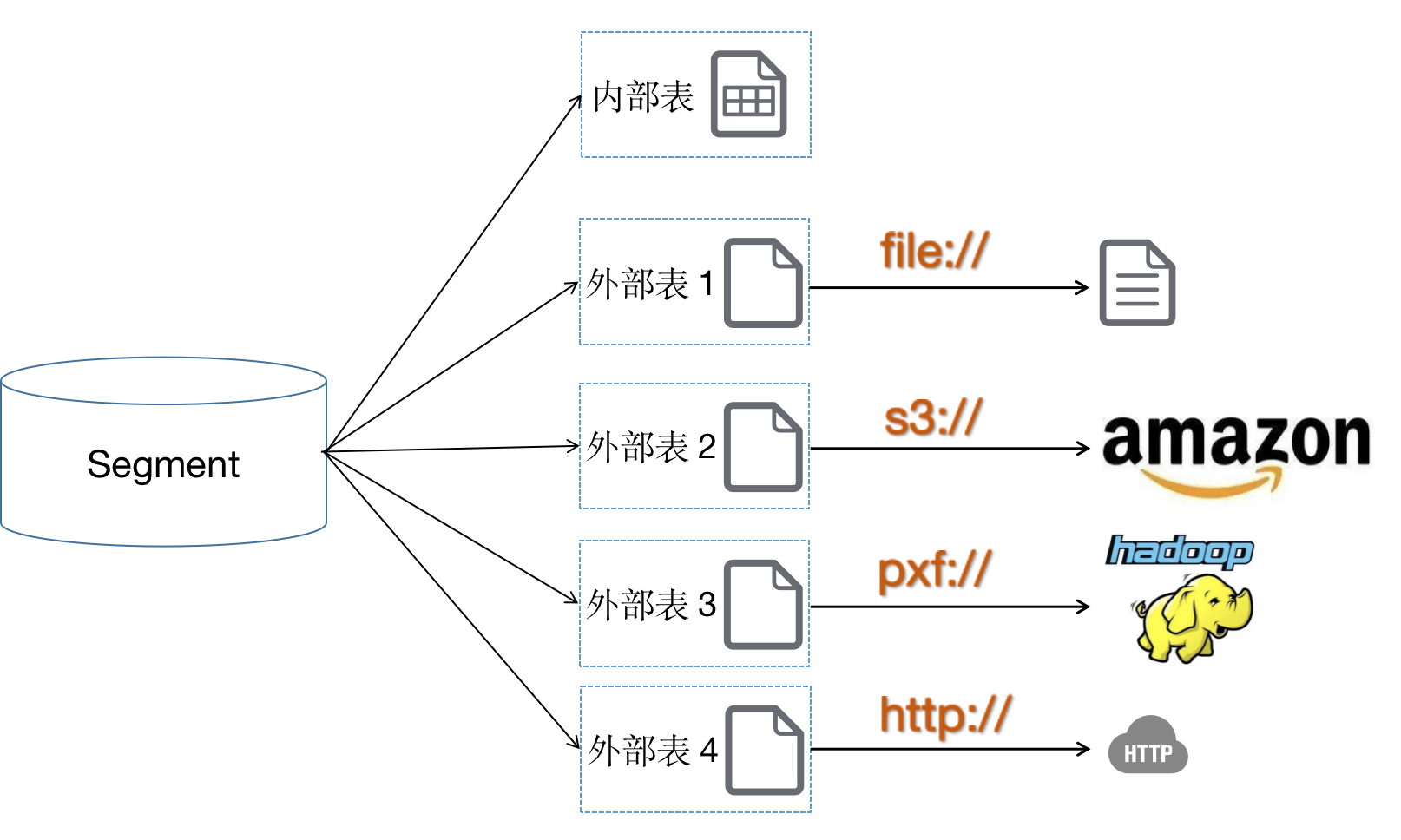 与其他表类型数据存储在数据库内部不同,外部表数据存储在数据库外部,内部只存了表的元信息。在创建表的时候通过 LOCATION 关键字指定,可以是文件路径,PXF,S3 或 HTTP 接口。
当查询外部表时,会根据 LOCATION 的协议和路径去读取指定的内容,从 SQL 接口层面看起来和普通表没有任何区别,也可以与其他普通表做连接。
如下 SQL 语句,创建了一张名为 ext 的外部表,LOCATION 路径为file://mdw/home/mxadmin/e1.csv,格式为csv:
与其他表类型数据存储在数据库内部不同,外部表数据存储在数据库外部,内部只存了表的元信息。在创建表的时候通过 LOCATION 关键字指定,可以是文件路径,PXF,S3 或 HTTP 接口。
当查询外部表时,会根据 LOCATION 的协议和路径去读取指定的内容,从 SQL 接口层面看起来和普通表没有任何区别,也可以与其他普通表做连接。
如下 SQL 语句,创建了一张名为 ext 的外部表,LOCATION 路径为file://mdw/home/mxadmin/e1.csv,格式为csv:
CREATE EXTERNAL TABLE ext(
c1 int,
c2 varchar(100)
)LOCATION ('file://mdw/home/mxadmin/e1.csv') format 'csv' (delimiter ',');那么,如何将外部表数据导入到数据表呢?
通过执行如下语句:
INSERT INTO dest SELECT * FROM external;
其中 dest 是目标数据表,external 是外部表,并且两个表的列数和类型必须相同。
如上 SQL 与普通的 INSERT INTO VALUES 最大的区别就是,数据解析与重分布执行在 segment 节点上,这样充分利用了分布式多机资源。
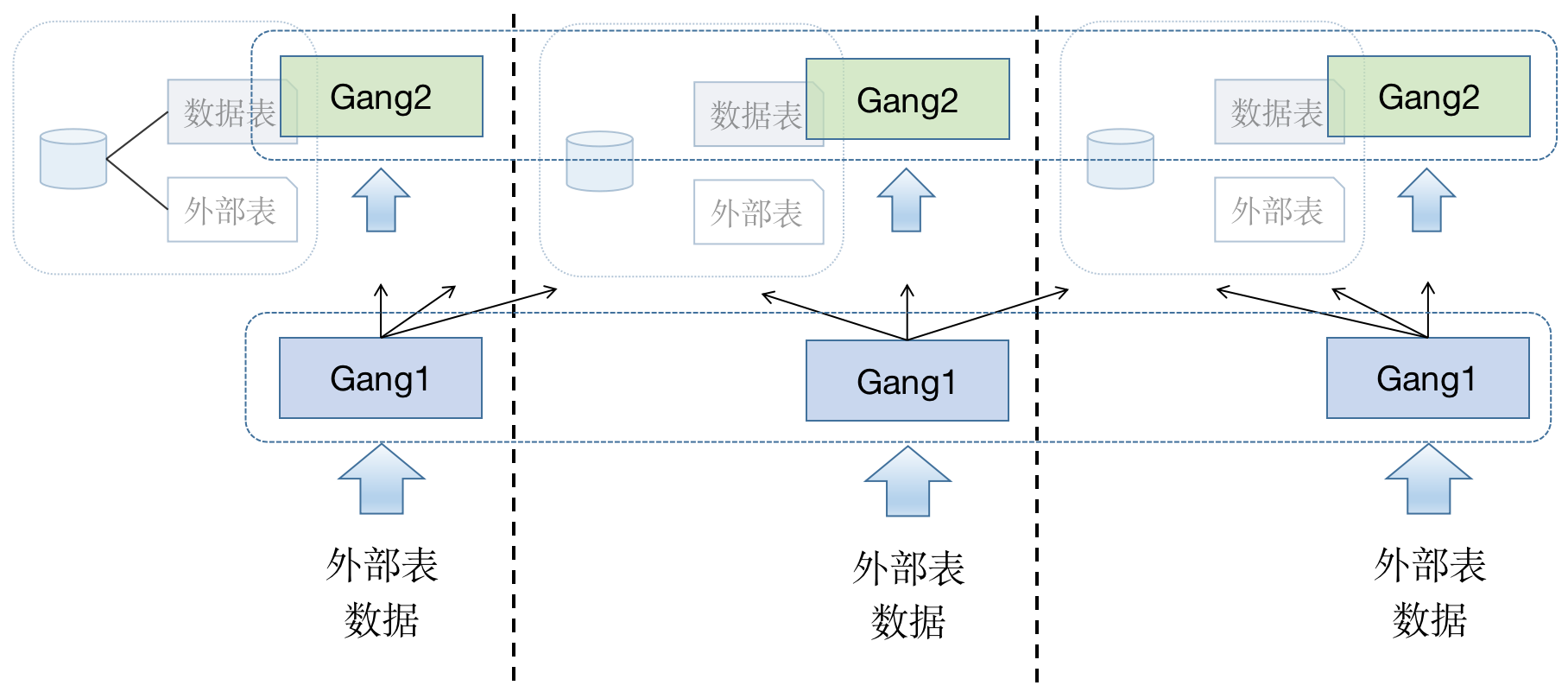 如上图所示,在实际运行过程中,会有两组 Gang,一组负责从 MatrixGate 拉取数据并分发到对应的 segment,另一组负责接收分发的数据然后存储到本地。
所以,master 节点并不处理实际数据,真正的解析与转发都是由 segment 进行,master 节点不再是瓶颈。
如上图所示,在实际运行过程中,会有两组 Gang,一组负责从 MatrixGate 拉取数据并分发到对应的 segment,另一组负责接收分发的数据然后存储到本地。
所以,master 节点并不处理实际数据,真正的解析与转发都是由 segment 进行,master 节点不再是瓶颈。
MatrixGate 利用了外部表导入数据的优势,实现了 HTTP 协议,和创建外部表、执行 INSERT SELECT 的过程。
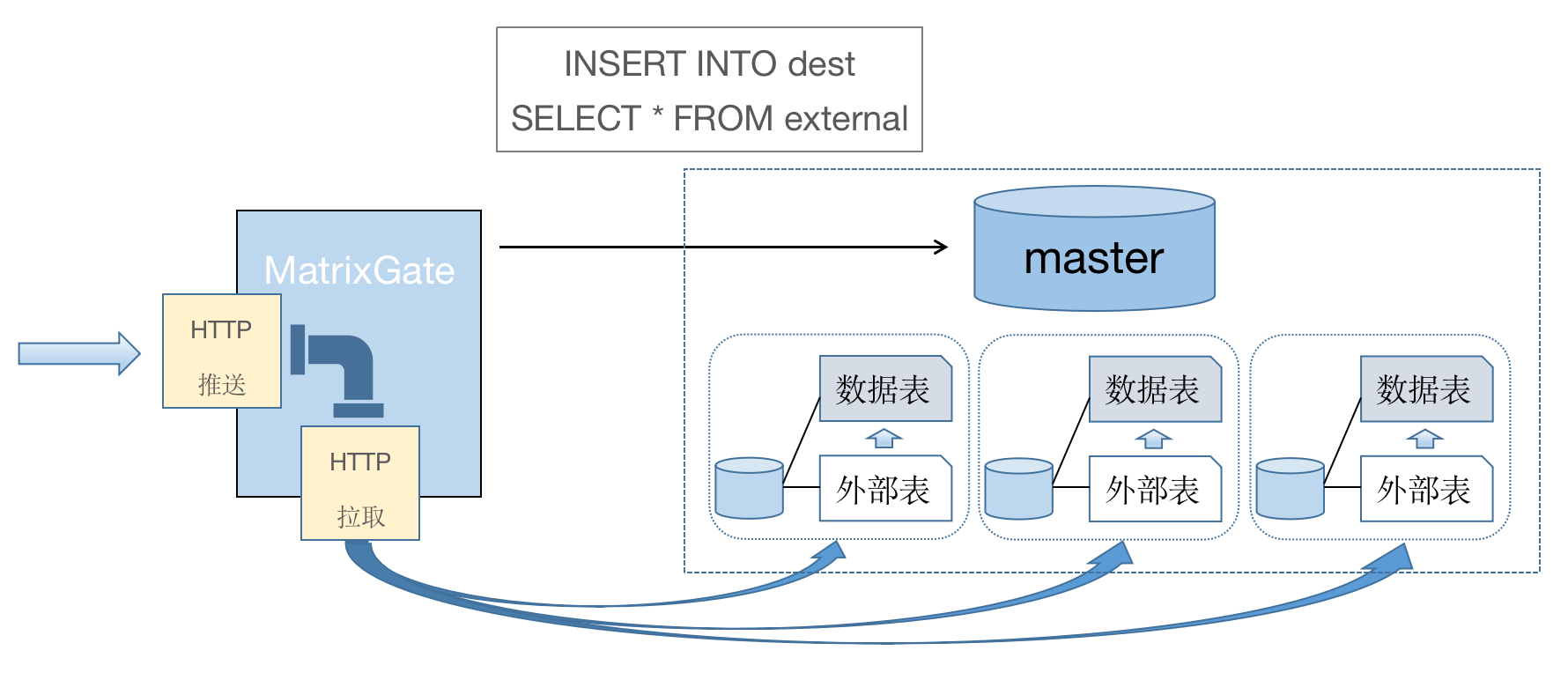 从上图可以看出:
从上图可以看出:
如要增加并发,在 MatrixGate 中启动多个任务并行执行 INSERT INTO dest SELECT * FROM external 即可。目前,MatrixGate 默认配置了 10 个并行任务。
最后,还有一个问题。那就是 INSERT INTO dest SELECT * FROM external 语句什么时候执行结束呢?
因为设备数据是一直在发送的,永不停歇,这就意味着 segment 一直能从 MatrixGate 拉到数据。如果插入语句一直执行不结束的话,数据就一直无法被其他会话看到;同时,事务太大,数据库维护成本也太高。
为此,MatrixGate 的每个并行任务在执行一段时间后,会向所有取数据的 segment 发送 EOF,即结束符。segment收到结束符后,认为数据已经取完,随之 SELECT * FROM external 子查询执行结束。在INSERT成功后,整个查询完成。
随后,会继续执行 INSERT INTO dest SELECT * FROM external,写入后面的数据。每个接收数据任务的默认执行时间间隔为 100ms,即过 100ms 发送 EOF。也就是说,数据在百毫秒级别时延后就会被查询到,基本接近实时。
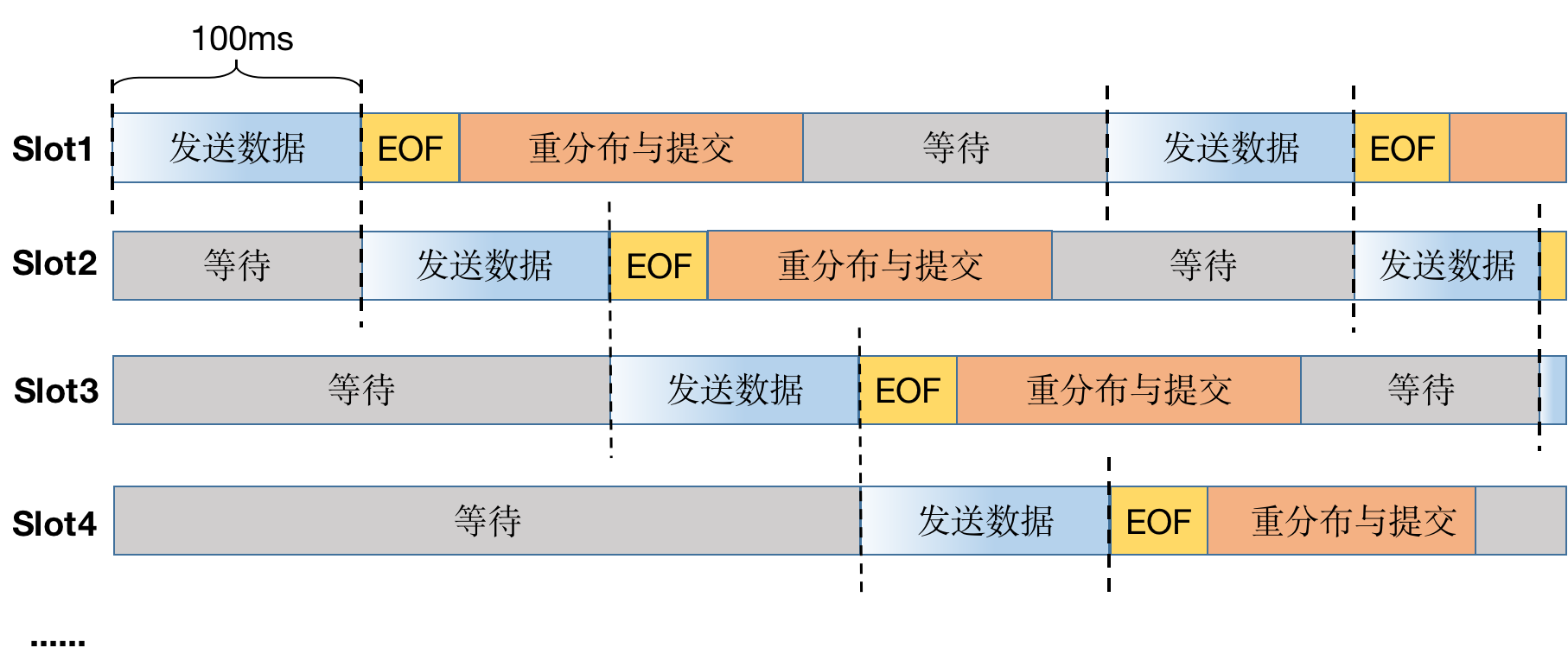
从上图可以看出,MatrixGate 的每个数据写入任务内部有很多 Slot,每个 Slot 都会执行 INSERT INTO dest SELECT * FROM external 语句来实现数据从外部表导入到数据表。SQL 语句执行分为如下两个阶段:
每次发送数据时间窗口为 100ms,不同 Slot 之间发送数据是互斥的(因为一个 Slot 就会占满网络带宽)。发送数据时间窗口到达后,发送 EOF 结束 SELECT 子句。新写入的数据则进入下一个 Slot 的发送数据窗口。
从上面可以看出,使用 MatrixGate 这种架构模型包含如下优点:
经测试,使用 MatrixGate 进行数据导入与竞品相比,性能可以提升几十倍。具体数据可参考《时序数据库插入性能评测:MatrixDB是InfluxDB的78倍》。






