_1749628397.png?x-oss-process=image/resize,h_300/format,webp/quality,q_80)
据工信部2024年数据,中国工业设备联网率已突破75%,但数据价值挖掘仍面临三大核心挑战:
1.高频写入洪峰 单条产线每秒生成数万条传感器数据(温度/振动/电流),汽车工厂日增超20TB时序数据,传统数据库写入易成瓶颈。
2.实时分析延迟 质量缺陷检测需200ms内响应,但跨系统数据孤岛导致分析链路长达15分钟(某零部件企业实测)。
3.异构数据融合困境 同一场景需处理设备时序数据(InfluxDB)、工单关系数据(Oracle)、图像日志(MongoDB),多系统协同效率低下。
技术特征
典型代表

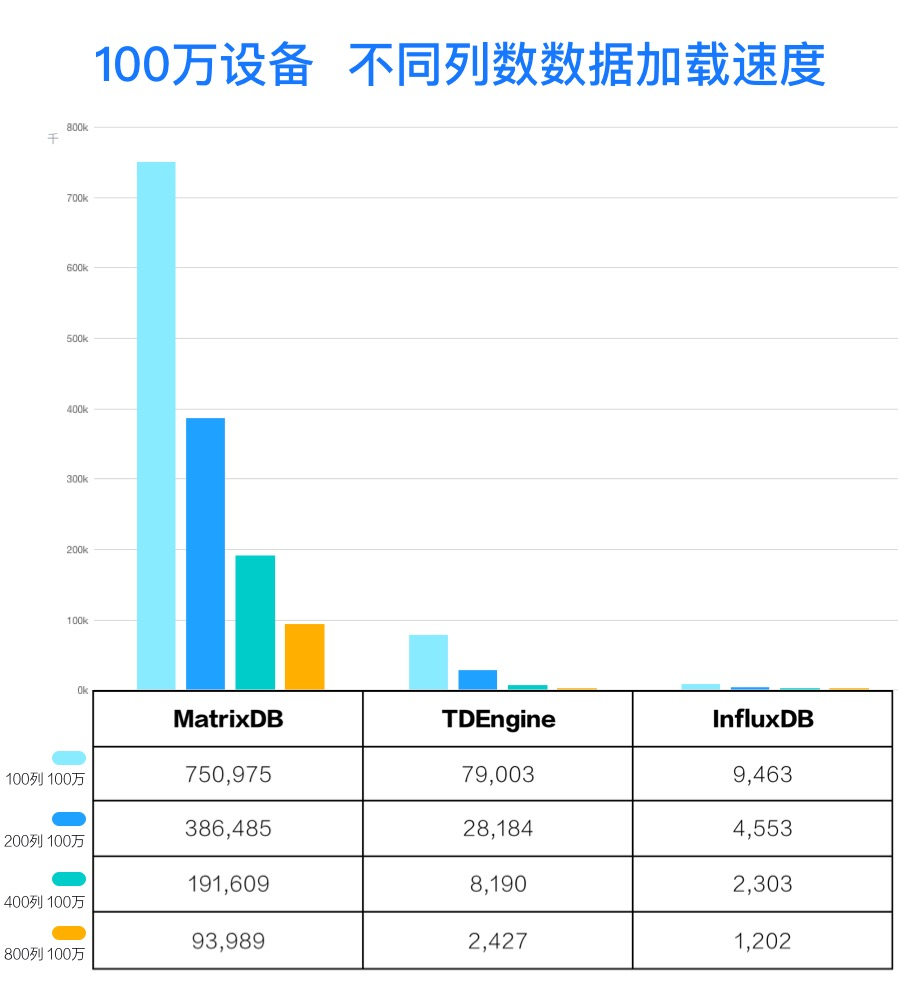
技术革新
致命缺陷
适用场景
风险预警:某装备制造企业Greenplum集群处理1TB质检数据需2小时,且无法支持实时告警。
适用场景
成本警示:1TB内存成本≈50块HDD硬盘,某半导体厂HANA集群年运维成本超千万。
第一步:数据特征诊断
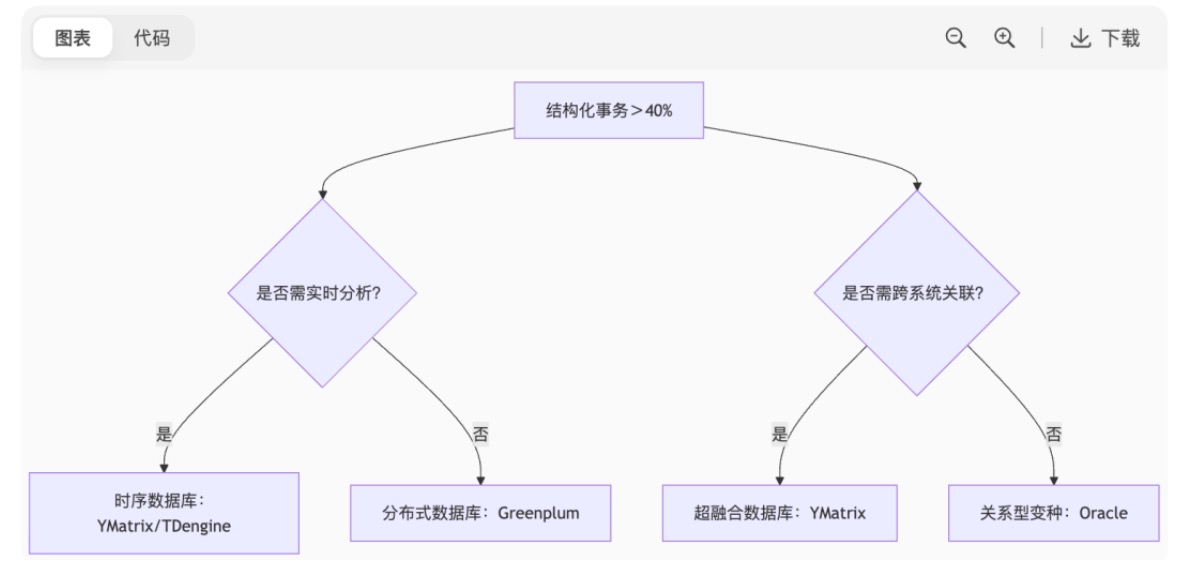
第二步:架构适配性验证
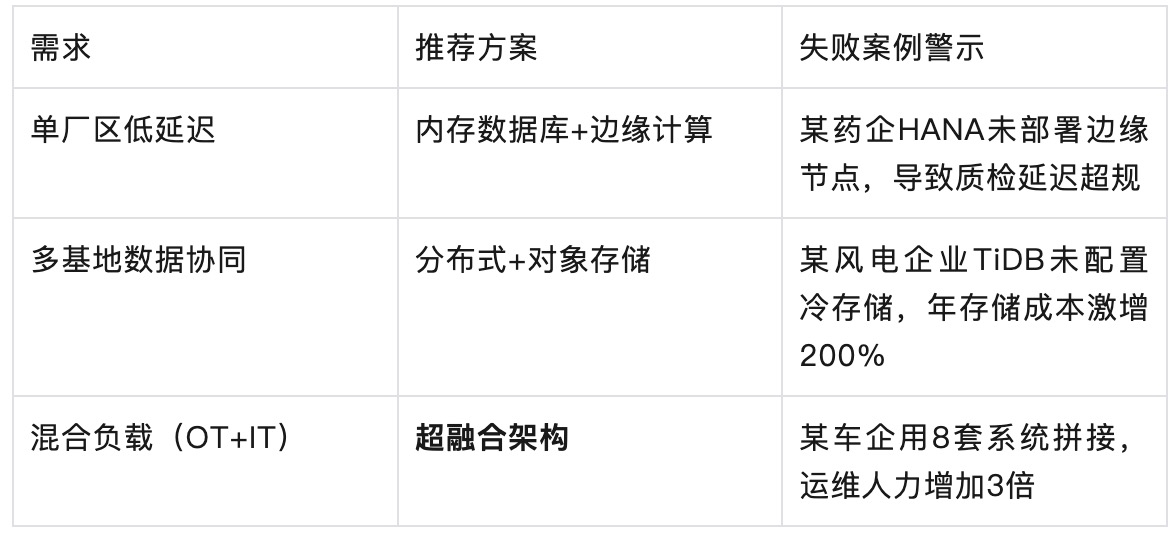
第三步:成本效益精算 成本公式:硬件成本+开放成本+运维成本
工业场景本质需要三类能力融合:
而传统方案如同“用三把刀切一块肉”,数据搬运损耗超40%(IBM研究院2024)。
使用YMatrix作为工业数据库的方案效果:

1.场景切片 区分核心场景(如设备监控用时序库)与融合场景(如质量分析用超融合库)
2.小规模验证 关键测试项: 写入稳定性(持续24小时压测) 混合查询响应(时序+关系SQL联合执行)
3.渐进迁移 timeline 2024 Q3 : 边缘设备数据接入YMatrix 2024 Q4 : 迁移MES工单数据至统一库 2025 Q1 : 关停Oracle集群,全量超融合
当工业元宇宙需要实时融合OT数据(设备状态)与IT数据(订单需求),更先进的架构将成为工业选型的重要标准。






