一、 企业介绍
小米制造作为全球领先的智能硬件制造企业,其工厂产线覆盖手机、智能家居等多品类生产,每日产生海量设备运行数据、生产日志及业务系统数据。为实现生产全流程可追溯、核心指标实时监控及快速决策,小米制造亟需一套能够支撑实时采集、高效分析、动态预警的大数据管理平台。
二、面临挑战
小米制造的智能工厂场景对数据处理提出了严苛要求,具体挑战包括:
数据规模与时效性:
- 产线设备数目庞大(涉及180 多类设备),日新增数据量预计可达 130GB,需要能够快速写入数据库,以实现实时更新良品率、OEE、UPH 等核心指标。
传统方法的故障预警是预先设定报警阈值,一旦监控到数据超过阈值,才能发出警报。这种方法存在严重滞后性,即发出警报时设备生产的良品率已经下降。
数据分析困难
- 终端设备产生的大量非结构化数据,传统数据库难以消化这些海量数据,往往会导致难以及时优化生产管理流程,无法针对性设计工厂生产的各类指标,进而阻碍了设备的监测和分析。
业务场景多样性
- 需支撑智能制造部工业数据组的澎湃 OS 中控大屏(显示生产核心指标)、自研BI系统(管理看板、工时统计)等多个核心业务。
传统架构局限性
- 早期依赖 Hadoop 生态及多类型数据库(如Greenplum、Oracle),无法承载实时计算需求,故障预警滞后,且复杂报表查询耗时过长。
三、YMatrix超融合数据库:一站式解决生产数据难题
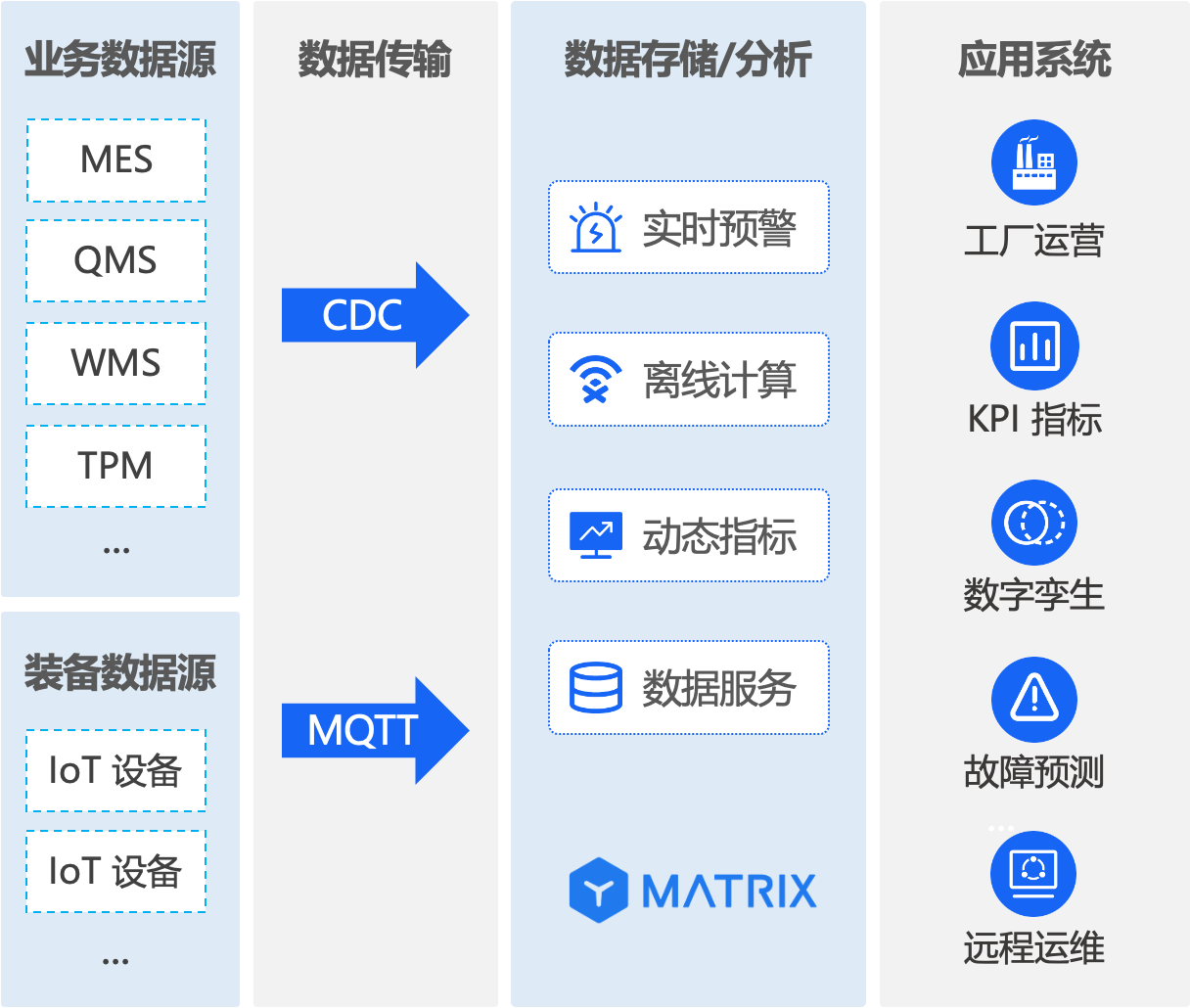
针对小米制造的核心诉求,YMatrix 超融合数据库提供了从数据采集到分析预警的全链路解决方案,关键能力覆盖:
- 数据高效写入:自研 MatrixGate 组件,满足海量数据快速接入需求。
- 实时混合计算(HTAP)架构:YMatrix 实现事务处理(OLTP)与实时分析(OLAP)融合,支持产线设备数据(如时序、结构化、非结构化数据)的实时写入与秒级查询。可保障生产异常(如良品率下降)及时发现并干预。
- 高效开发与运维优化:支持plpython编程,实现数据库维护工作与算法开发工作解耦。
- 复杂场景适配能力:针对良品率计算等复杂业务(算法复杂、时效性要求高),YMatrix通过库内流计算引擎(Domino)实现实时指标动态计算,避免结果延迟导致的废品浪费。
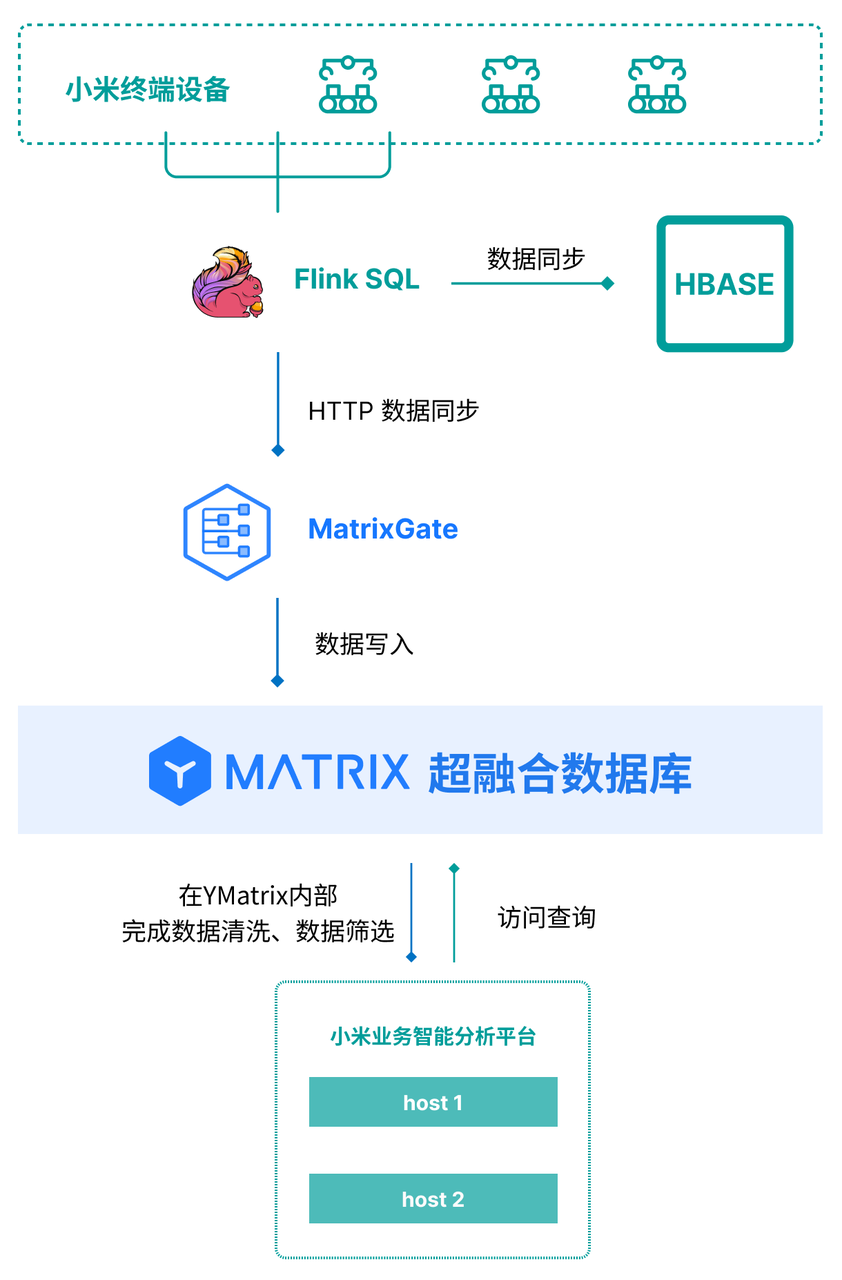
四、客户收益:从数据驱动到生产质效双提升
YMatrix 承载来自 IoT 平台的设备运行中的生产状态、实时参数、生产日志等数据,同时接入业务数据。建立起了基于 HTAP 的数据管理平台。 通过库内实时预警、离线分析、动态指标计算以及数据服务,赋能智能工厂运营与数字孪生等应用。
生产效率提升
- 时序性能卓越,写入速度可达 5w+ 行/秒,满足数十万台装备的接入;
- 日请求量达50万QPS,95% 查询响应时间 <2.5秒,保障产线稳定运行;
- 截止 2024 年底,总数据量已达 12TB+,最大表 1.8TB+,为工厂运营提供稳定的底层支撑。
生产成本降低
- YMatrix 一站式满足多模数据存储与计算需求,降低架构的复杂度,提高运维效率,降低人员成本;
- 核心指标(良品率、OEE、UPH)查询速度大幅提升,实时预警,及时发现产线问题,提高良品率,降低企业生产成本。
更多业务支撑
- 澎湃 OS 中控大屏实时展示生产核心指标(如OEE、良品率、UPH 等),为管理层提供决策依据;
- 支持自研 BI 系统工时管理、看板分析,推动生产流程精细化;
- 库内机器学习能力,助力预测性维护功能,帮助客户工艺快速迭代,保持核心竞争力。
五、总结:智能工厂的“超融合”数据基座
小米制造的实践表明,YMatrix 超融合数据库通过实时计算、高效存储、简易运维的一体化能力,成功解决了智能工厂场景下“数据多源、分析复杂、响应时效”的核心痛点,不仅支撑了当前生产管理需求,更为未来扩展(如冷热数据分离、数字孪生)奠定了坚实基础。作为头部制造企业的选择,YMatrix 正成为智能工厂数据中枢的“标准配置”。







