
实时数据仓库的建设如同铺设城市地下管网,表面看不到的工程细节,往往决定整个系统的生命力。本文将从ETL、存储、计算到容灾四个层面,揭示那些容易被忽视却至关重要的技术要点。
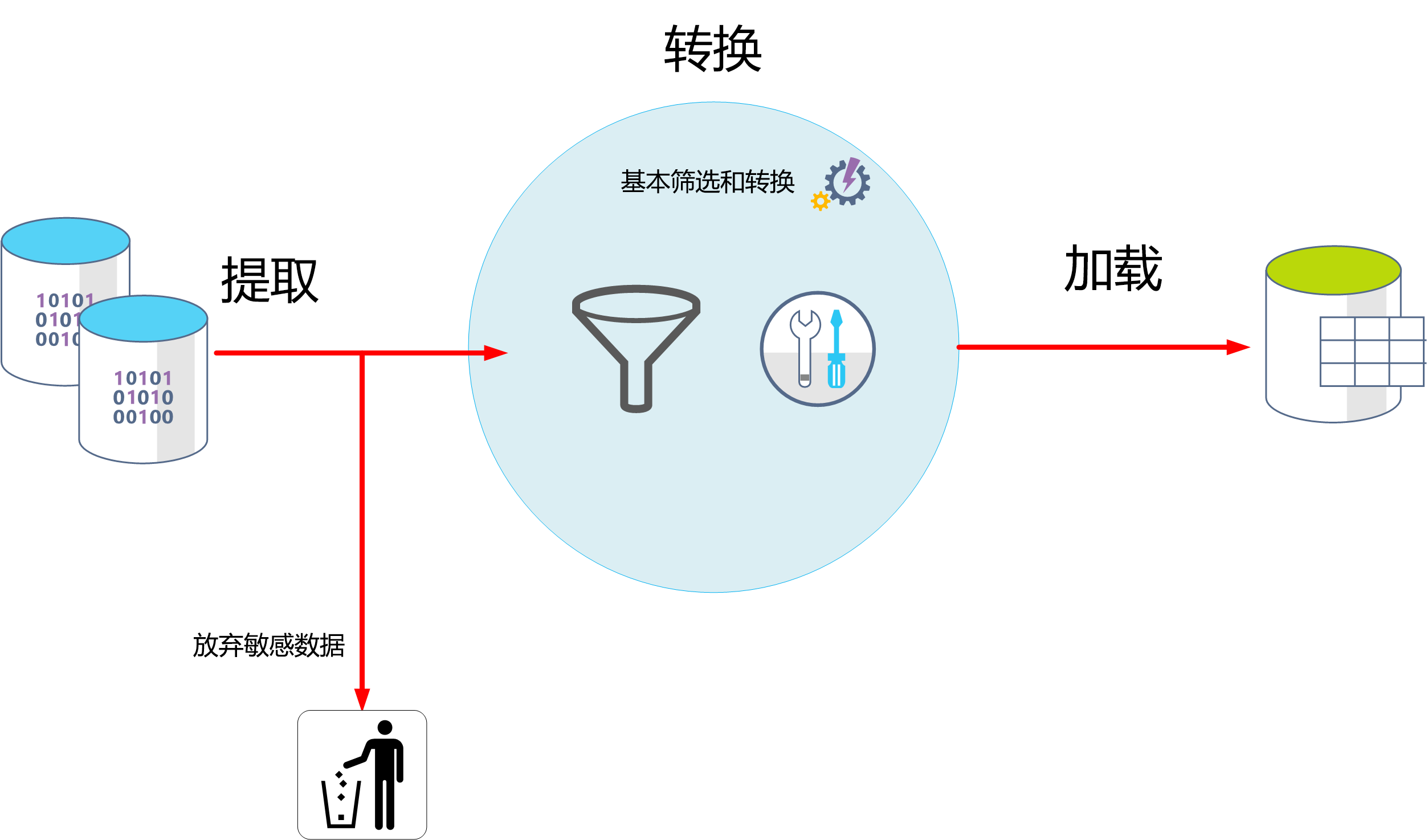 ETL指的是是数据抽取(Extract)、转换(Transform)、加载(Load),ETL是许多数仓结构的入口通道。许多企业使用不同的数据系统,链接不同的数据源,这些数据需要通过简单的处理然后再传输进入数仓,通常企业的处理办法是购买ETL组件,链接数据源与数仓。
ETL指的是是数据抽取(Extract)、转换(Transform)、加载(Load),ETL是许多数仓结构的入口通道。许多企业使用不同的数据系统,链接不同的数据源,这些数据需要通过简单的处理然后再传输进入数仓,通常企业的处理办法是购买ETL组件,链接数据源与数仓。
当数仓承载了实时的需求时,ETL的性能就至关重要了。而在实时数仓中,ETL的常见“坑”在于:
当流计算任务持续接收设备数据时,若与周期性批量ETL任务共享计算资源,可能引发资源抢占。这类似于早高峰的地铁换乘站,通勤客流与转乘旅客在通道内相互阻滞。有一种解决方案是建立物理隔离的资源池,为流任务与批任务划分独立计算单元,避免相互干扰。
这是另一个ETL比较隐蔽的问题。当网络波动导致操作重试时,传统系统可能重复写入相同数据。如同快递员因未收到签收回执反复投递同一包裹,造成仓库库存混乱。通过分布式事务协议与唯一键约束,可确保数据操作的幂等性,从源头消除冗余。
有一类超融合数仓,例如YMatrix,因为融合了数据全流程,所以可以避免ETL单独组件所带来的数据传输影响。
数据存储架构直接影响查询效率,这里有两大典型陷阱:
某些存储引擎在数据累积过程中,需反复整理磁盘结构。这种整理如同不断重组货架的仓库管理员,占用大量本应用于存取货物的时间。优化策略包括调整数据合并策略与压缩算法,减少后台操作对写入吞吐的影响。
高频访问的新数据与极少使用的历史数据若混合存储,如同将畅销商品与滞销品堆放在同一货架。当用户查询近期数据时,系统被迫在大量历史记录中筛选,显著拖慢响应速度。智能分层存储技术可自动识别数据热度,将热数据置于高速存储介质,冷数据迁移至低成本设备,兼顾性能与经济性。
实时查询的延迟波动常源于计算层设计缺陷。计算层对于数据实时查询至关重要,重点需关注两点:
虽然向量化引擎能批量处理数据列提升效率,但复杂查询仍需逐行计算。这就像用集装箱卡车高效运输标准货物,遇到异形物品仍需手工搬运。现代系统通过查询编译器将复杂逻辑预编译为机器码,消除解释执行的开销,缩小性能差距。

实时分析、报表生成、即席查询等多类任务并行时,资源分配失衡会导致关键业务延迟。类比医院急诊室被体检人群挤占,危重患者反而无法及时救治。动态优先级调度机制可确保高时效性任务优先获取计算资源,必要时暂停低优先级作业。
灾备能力常被简化为主从复制,实则存在致命盲区:
全量数据跨区同步会产生巨额带宽成本,如同要求每辆通勤车都往返于京广两地。增量快照技术仅传输变更数据,结合高效压缩算法,可降低70%以上的带宽需求。
主节点故障时,传统主从架构需人工判断是否切换,决策延迟可能扩大事故。三副本强同步机制通过多个实时镜像,确保任意节点宕机时,其他副本能即刻无缝接管,消除切换犹豫期。· 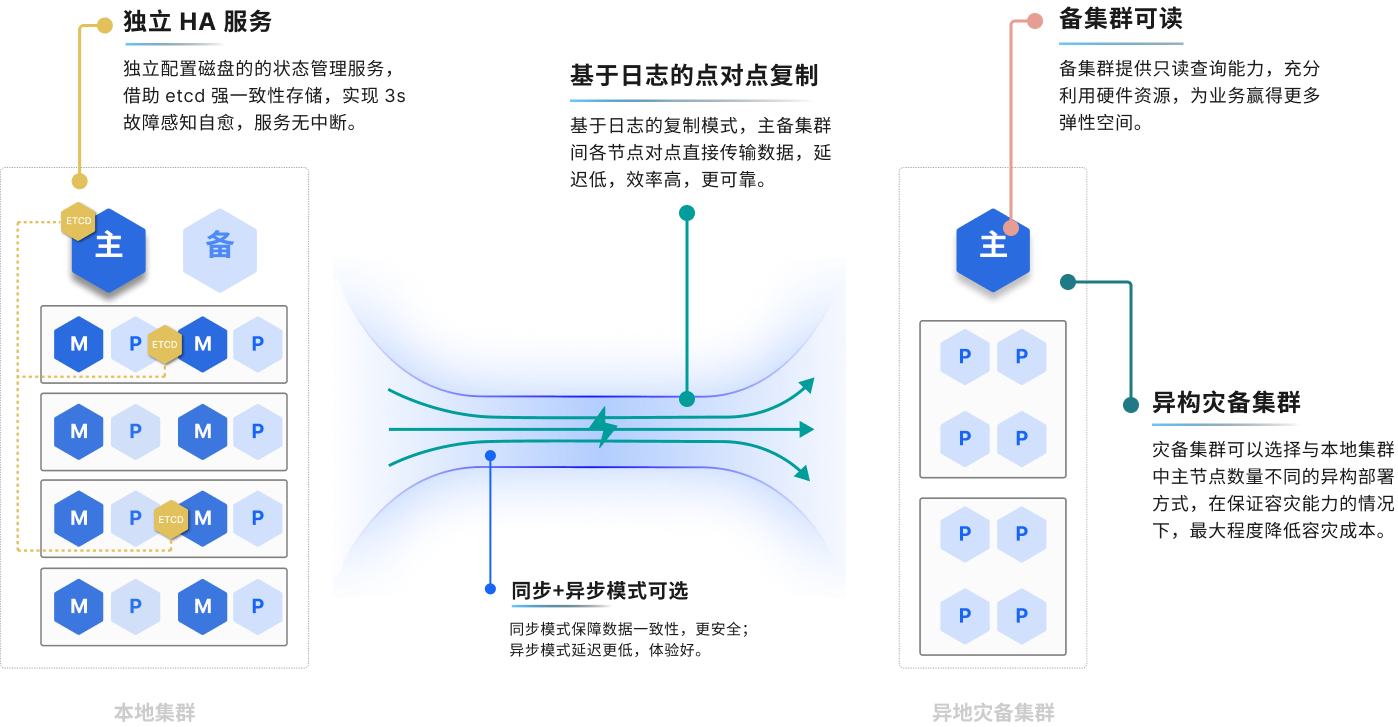
定期审视这些指标可预判风险:
实时数据仓库的稳定性不取决于某个组件的高性能,而在于整个数据管道中流动阻力的系统性消除:
当数据的流动能够像健康的“血管”一样自由时,实时数仓才能真正成为企业的数字心脏。






