
目前,三一重工泵诵云平台的数据接入采用 Nifi + YMatrix Database 的方案已正常运行 4 个月。
其中,NiFi 集群由3 台配置为内存 32G、硬盘 1T 的服务器组成,平均 5 分钟消费 Kafka 数据 6.4GB,每秒处理数据 14784 条。NiFi 本身提供大量组件,用以应付各式各样 ETL 场景,实现了 hdfs、本地文件系统、主流数据库 (mysql/oracle/postgres) 之间数据的流转。

Apache NiFi,专门用于解决与数据流有关问题的工具,易于使用、功能强大、可靠的数据 ETL 系统。基于 WEB 图形页面,通过组件的拖拽、连接及配置,即可搭建完整的数据流,实时监控数据在各个处理组件之间流转的情况。
MatrixGate,简称 mxgate,是 YMatrix 自带的高性能流式数据加载服务器。使用 mxgate 进行数据加载性能,要远远高于原生INSERT语句。
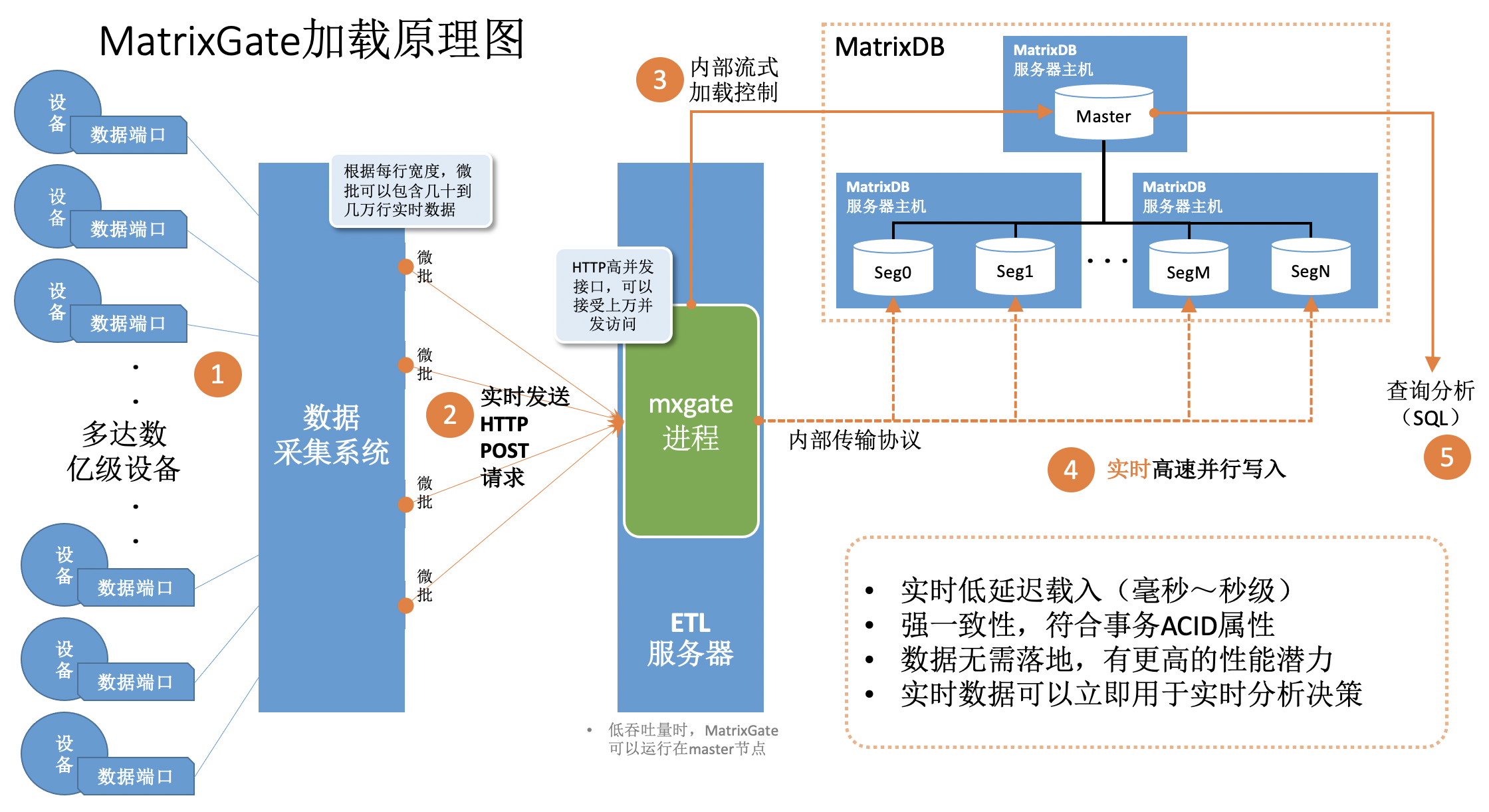 其加载数据逻辑和特性包括:
其加载数据逻辑和特性包括:
我们将二者相结合,实现了数据实时入库,并且解决了标准化的问题。
首先,在进入案例细节前,先介绍一下 NiFi 中一个重要的概念 FlowFile。在我们的案例中,数据的流转在 NiFi 中,就是 Flowfile 的生成与转化:
我们数据处理思路,使用 NiFi 搭建数据流的过程如下:
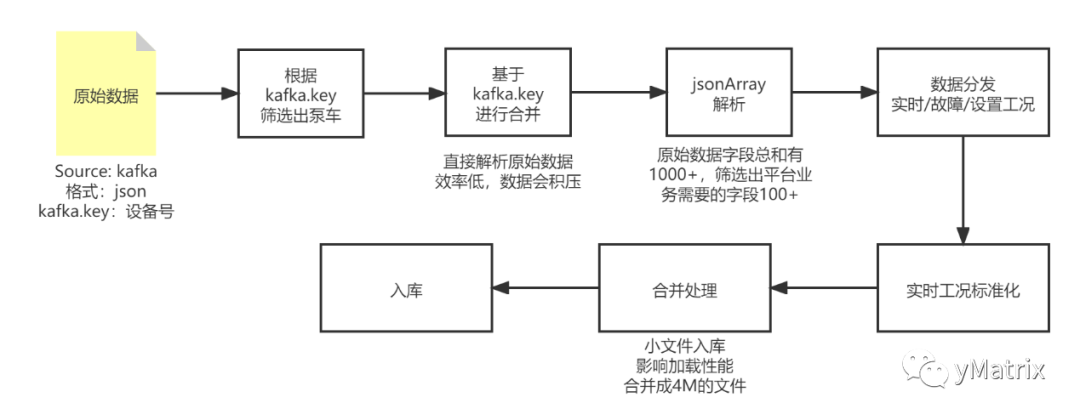
用 NiFi 自带的 ConsumeKafka_2_0 组件,只需配置 broker、topic,即可消费数据输出到下一组件。

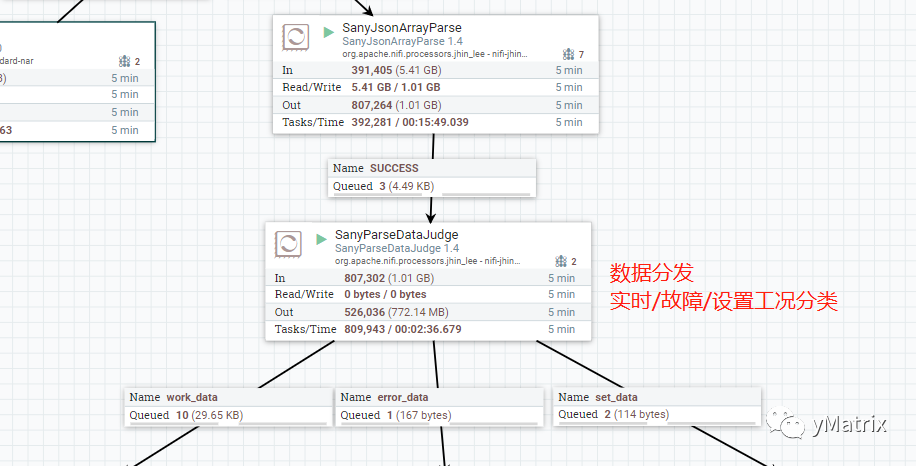
功能为根据 kafka.key 分发车载泵和泵车的数据,也可以用 NiFi 自带的 RouteOnAttribute 组件。官方组件实现的分发规则更加的灵活,但是效率要低许多。样例如下:

我们使用了NiFi自带的MergeContent 组件,合并策略采用桶策略。
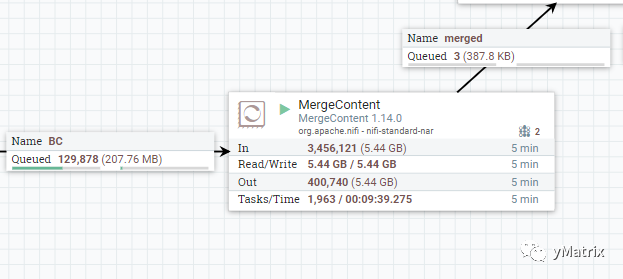
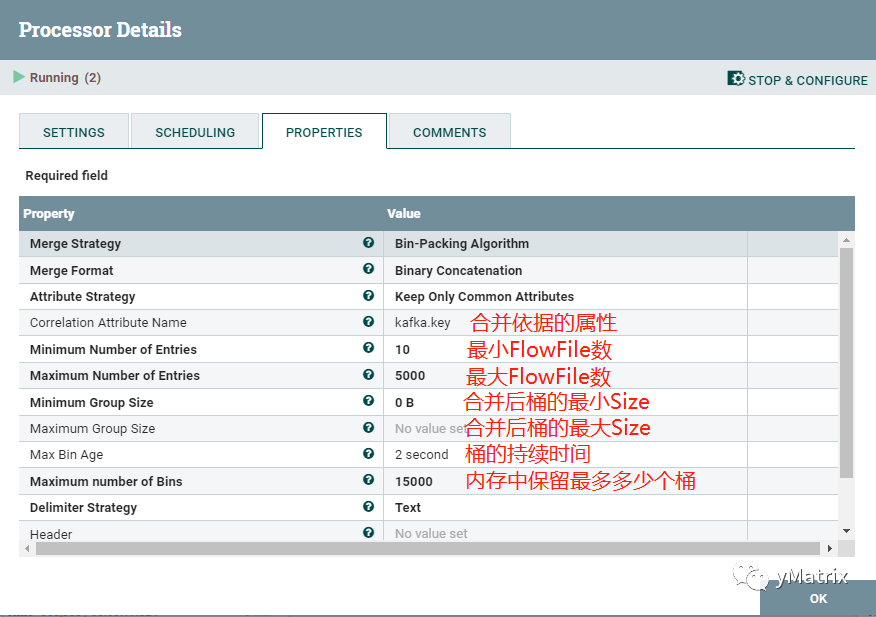
我们对桶策略定义如下:

我们用到的组件为自定义组件,因为原始的 json,key 不固定,而 NiFi 自带的 jsonReader 组件只能用单一的 schema 去读。
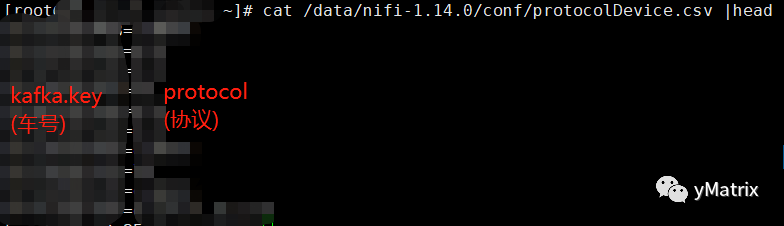
设备上传的数据是由控制协议定义的,随着控制协议以及设备的更新,新老设备对于同一个物理量会存在不同的字段映射,比如转速这个物理量,在1车型中是字段A,在2车型中是字段B,我们希望根据车型的不同,填充A or B 到转速这个物理量。 以下是实现标准化涉及的组件:
NiFi 自带的 LookupAttribute 组件,根据前文提到的 kafka.key 这一属性,为每条记录添加 protocol 属性,为后续每条记录输出A还是输出B提供依据。


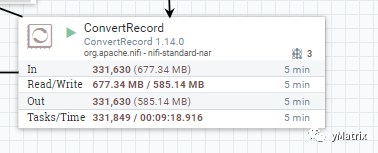
为每个 FlowFile 添加上 protocol 这个属性后,在使用 NiFi 自带的 ConvertRecord 组件根据 protocol 的值动态地输出A or B,以此达到标准化的效果。
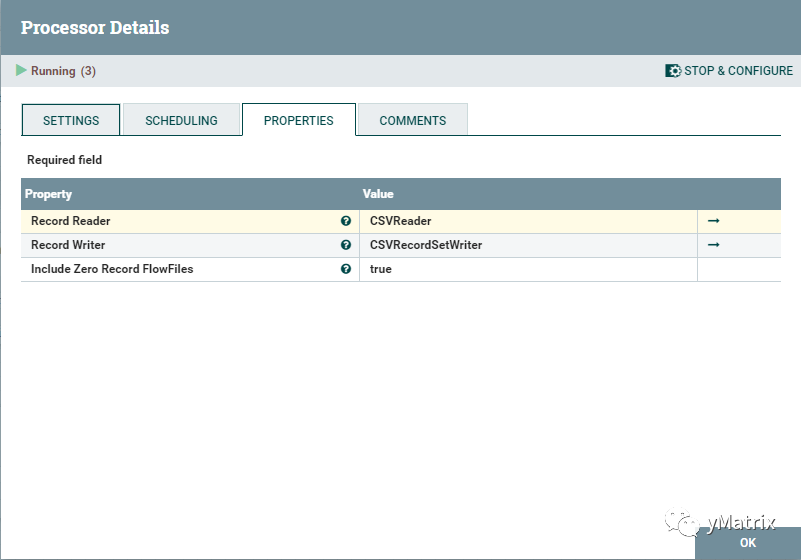

这个组件能 put 数据到市面上主流的数据库,只需指定 jdbc 的 jar 包,以及配置 url,数据库名等,但是入库效率会表较低。
所以,我们结合 mxgate 的 java api,自定义一个组件,用于加载数据到 YMatrix Database。
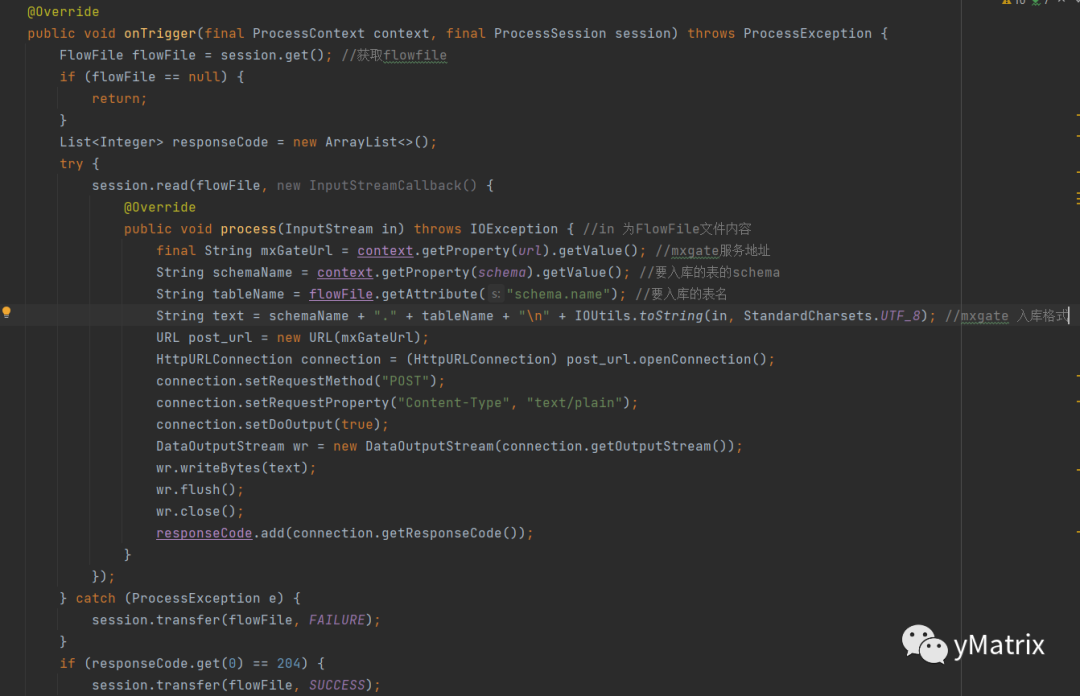
 PutDatabaseRecord 自定义组件的代码实现如下:
PutDatabaseRecord 自定义组件的代码实现如下:
在我们的实践中发现,需要特别注意,NiFi 为了防止数据丢失,会将接入的数据内容作为内容声明保存在本地,可以通过更改 NiFi 配置,再重启来改变内容声明留存时间。
前期由于使用默认的留存时间,再加上服务器本身磁盘有限。因此,在很短的时间内出现磁盘满了的情况,通过改变留存时间以及定时清理内容声明,可以解决磁盘爆满的问题。这离存在的问题是,一旦碰到某种原因导致 NiFi 未及时入库数据,而被定时清理了内容声明,那数据就会丢失,还是需要通过对磁盘扩容来解决。
总的来说,“NiFi+Mxgate” 二者的结合完美地解决了数据接入的问题。






