
数据库行业,经常出现三个概念:数据库、数仓、数据湖,经常出现在不同数据处理场景中,这三个概念确实容易混淆,但它们代表了数据存储和处理的不同理念和阶段。简单来说:
就像你日常使用的银行账户系统或购物网站后台,设计用来处理实时交易(如存取款、下单),强调快速读写和数据一致性。
更像一个专门为分析决策设计的“历史数据中心”。它把来自不同数据库、业务系统的数据清洗、整理、结构化后存储,便于你用SQL进行复杂的查询、报表生成和商业智能分析。
如同一个巨大的“原始数据池塘”。它不挑剔数据格式(文字、图片、日志、视频等都能存),以低成本存储大量原始数据,供你未来进行探索性分析、机器学习或数据挖掘。
下面我们来详细比较它们的主要使用目的,适用数据类型、数据处理方式等维度,来分析三者的核心区别:
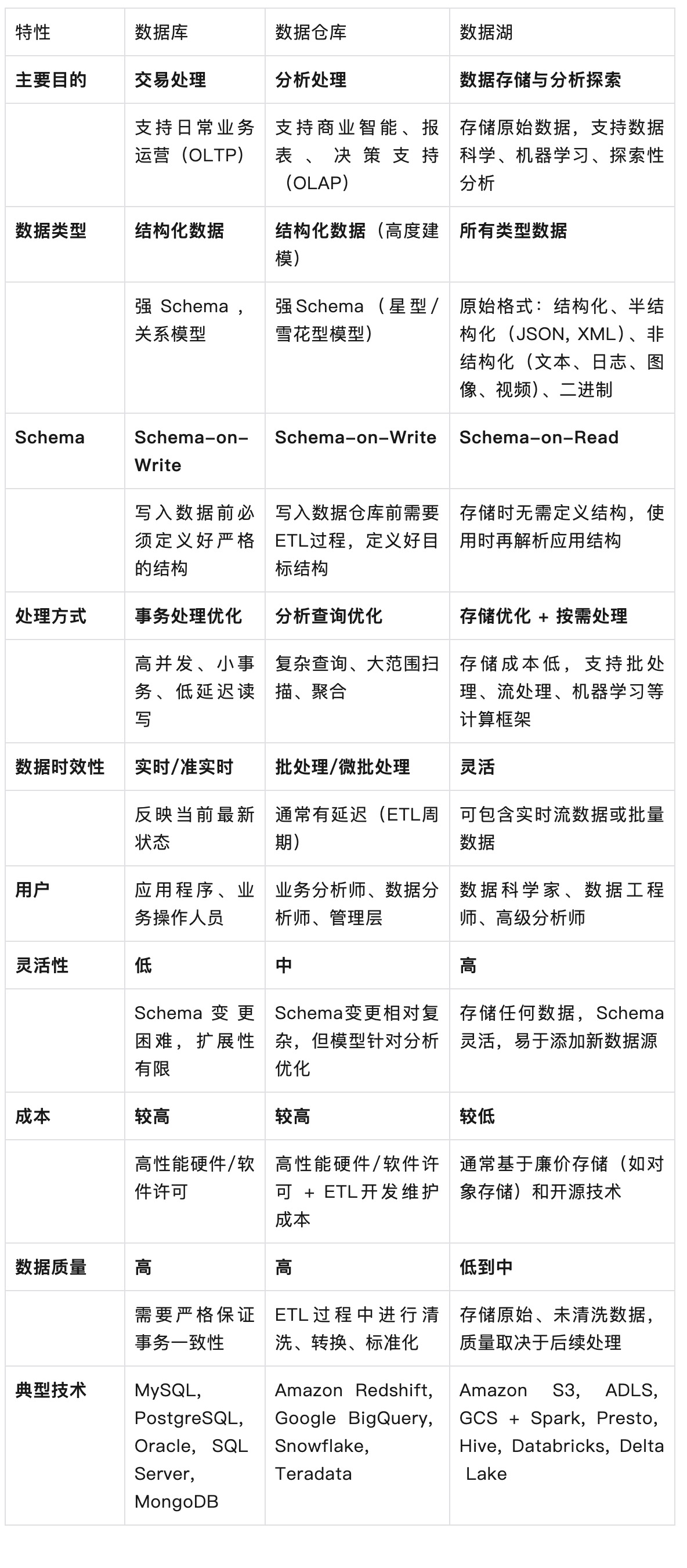
由上文特性分析我们可以得知
核心目标: 支持在线事务处理。确保业务操作(如创建订单、更新库存、转账)能够快速、准确、可靠地完成。
数据模型: 通常是结构化的,遵循预定义的(如关系模型)。写入数据时必须严格遵守这个结构。
优化: 针对低延迟读写和高并发进行优化。强调 ACID(原子性、一致性、隔离性、持久性)特性来保证数据完整性。
使用场景: 应用程序的后端存储(用户账户、产品目录、交易记录)、内容管理系统等。
局限性: 处理复杂分析查询(涉及大量历史数据扫描和聚合)效率较低;存储成本相对较高;Schema 变更可能比较繁琐。
加载: 将处理好的结构化数据加载到仓库中。这个过程是 Schema-on-Write。
核心目标: 支持在线分析处理。为商业智能、报告、数据可视化、历史趋势分析和制定战略决策提供单一、集成的数据视图。
数据来源: 从多个操作型数据库、事务系统和其他来源抽取数据。
数据处理(ETL/ELT):
抽取: 从源系统获取数据。
转换: 清洗(处理缺失值、错误、不一致)、标准化(统一格式、单位)、集成(合并不同来源的数据)、聚合(预计算汇总数据)、建模(组织成星型/雪花型模式)。
加载: 将处理好的结构化数据加载到仓库中。这个过程是 Schema-on-Write。
数据模型: 高度结构化和优化用于分析查询(如星型模式、雪花模式)。维度表和事实表是核心。
优化: 针对复杂查询性能(大量数据扫描、连接、聚合)进行优化,通常使用列式存储。
使用场景: 生成月度销售报告、分析客户行为趋势、跟踪关键绩效指标、进行市场细分等。
局限性: ETL 过程复杂耗时,可能导致数据延迟;存储和处理成本较高;主要处理结构化数据,对半结构化和非结构化数据处理能力有限;Schema 设计需要预先规划,后期修改可能影响下游报表。
核心目标: 以低成本存储巨量、多样化的原始数据(结构化的、半结构化的、非结构化的、二进制的),保留其最原始的形式。
核心理念: Schema-on-Read。在存储时不强制定义数据结构或转换数据。当数据被读取用于特定用途(如分析、机器学习)时,才应用所需的 Schema 和转换。
存储: 通常建立在可扩展且成本低廉的存储系统上,如对象存储。
灵活性: 极高的灵活性。可以轻松添加任何来源、任何格式的新数据源,无需事先进行复杂的建模。非常适合存储日志文件、传感器数据、社交媒体数据、图像、视频等。
处理: 数据湖本身主要是存储层。处理(SQL 查询、机器学习、流处理)由上层计算引擎(如 Spark, Presto, Hive, Flink)在需要时执行。
使用场景: 高级分析、机器学习模型训练、探索性数据分析、存储尚未明确用途的原始数据、处理 IoT 设备产生的海量数据、作为数据仓库的补充或来源。
挑战: 如果不加管理,容易变成“数据沼泽”,数据难以查找和理解;数据质量参差不齐;需要强大的数据治理、元数据管理和目录工具;查询性能可能不如针对特定查询优化的数据仓库(虽然现代技术如 Delta Lake、Iceberg、Hudi 正在弥合这个差距,提供类似仓库的能力如 ACID 事务)。
像是高速运转的生产线,精确处理每一笔“当下”的交易。
像是精心整理过的公司档案馆,里面的文件(数据)都按标准分类装订好,方便管理人员快速查找历史报告和决策依据。
更像是一个巨大的原始材料仓库,里面堆放着从各处收集来的矿石、木材、零件(原始数据),工程师(数据科学家)可以随时进来挑选所需材料进行实验或建造新东西。
现代数据架构常常是混合或融合的模式:
Lakehouse:
一种新兴架构(如 Databricks 的 Delta Lake,Apache Iceberg, Apache Hudi),旨在结合数据湖和数据仓库的优点。它在数据湖的低成本存储基础上,添加了数据仓库的关键特性:ACID 事务、模式执行与演进、数据治理、BI 支持等,提供统一的平台处理所有类型的数据和分析工作负载。
数据仓库现代化:
现代云数据仓库(如 Snowflake, BigQuery, Redshift)也在扩展能力,能更好地处理半结构化数据,提供更灵活的弹性计算。
选择哪种解决方案(或组合)取决于你具体的业务需求、数据类型、分析目标、预算和技术栈。理解它们之间的根本区别是设计有效数据架构的第一步。






