
在传统数据库架构下,随着数据规模的增长、查询复杂度的提升、实时写入的增加等,通常意味着服务器数量线性甚至超线性增长。企业在面对上述场景时,扩容往往是最直接的答案:数据量变大了,加磁盘;查询变慢了,加 CPU;并发上来了,加节点;实时分析压力变大了,再加一套流处理系统。
但在今天,这个答案正变得愈发昂贵。AI 基础设施的快速扩张,正在持续推高服务器产业链的价格中枢。公开数据显示:2026 年一季度,常规 DRAM 合约价环比上涨约 90% ~ 95%;二季度,DRAM 预计还会继续上涨 58% ~ 63%,NAND Flash 合约价预计上涨 70% ~ 75%。IDC 相关数据也显示,2025 年全球服务器市场收入同比增长 80.4%,Q4 同比增长 52.4%。
以一台典型的中高端数据库节点为例,双路 CPU、数百 GB 内存、多块企业级 SSD/NVMe、高速网络、RAID 卡和三年原厂维保叠加在一起,单台报价来到三四十万元甚至更高,已经十分常见。如果再把机柜、电力、网络、备份、维保和运维人力算进去,三年周期的 TCO 压力会被进一步放大。
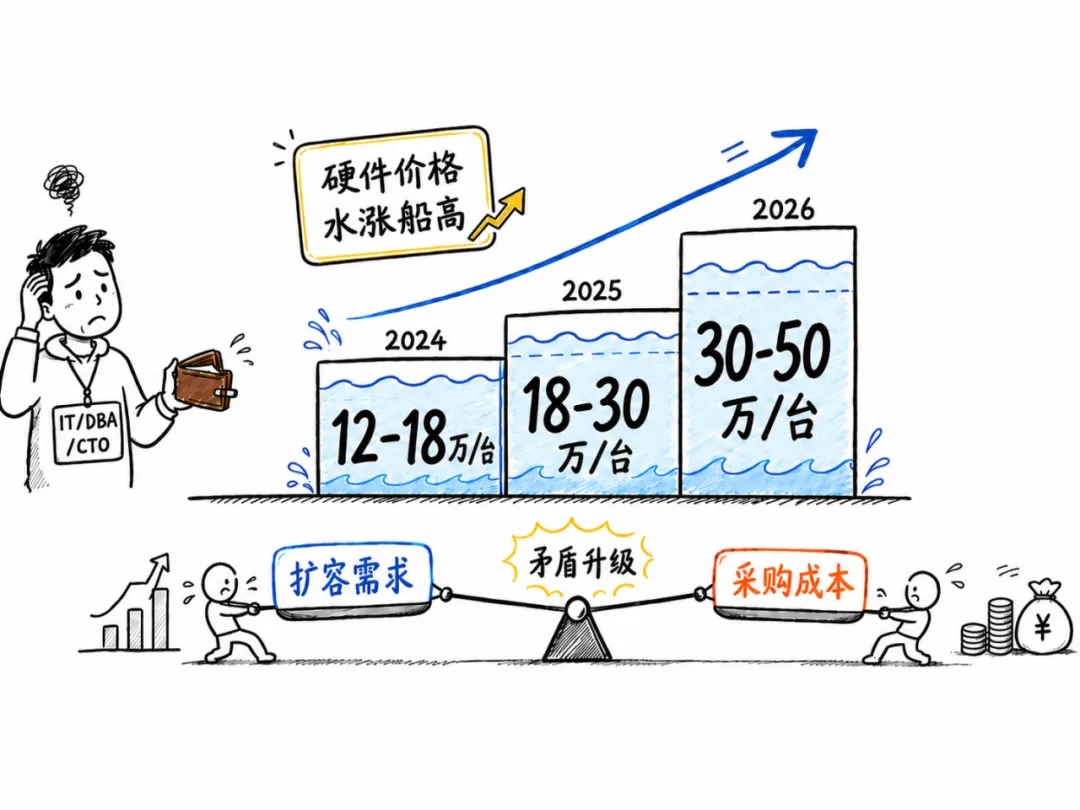
对众多企业来说,数据库成本已经不只是软件成本,而是体现在服务器、存储、网络、备份、外围系统和运维上的综合投入。这也是数据库选型逻辑正在变化的地方。过去客户更关心数据库能不能跑、性能够不够快;现在越来越多客户还会关心同样的服务器配置,能否跑得更稳、更久、更高效。
在某头部金融交易机构的一次迁移场景中,我们遇到了一个非常典型的数据库场景。这套环境一共使用 16 台数据库服务器,每台服务器都是面向数据库负载配置的高规格机器:128C CPU、512GB 内存、双 25GbE 组网、企业级 SATA SSD、硬 RAID,整套集群的硬件投入、维保成本、机柜空间和后续扩容成本都不是小数目。
在原始 Greenplum 环境中,数据规模约为 115TB。迁移到 YMatrix 后,同一批业务数据落库后的规模下降到约 80TB。也就是说,仅数据存储这一项,就减少了约 35TB 数据量,存储空间下降约 30%,在同等硬件下,数据承载密度提升约 45%。如果把该特定场景的资源效率收益放到客户完整生产规模中测算,节省空间会被进一步放大。按照其生产扩容口径折算,潜在节省规模可超过约 100 台服务器,对应硬件与配套成本约 3000 万元。
随着服务器价格的水涨船高,资源效率,也就不再只是数据库内核里的优化细节,而是企业数据基础设施能否持续建设、持续演进的关键问题。这也正是 YMatrix 希望解决的,YMatrix 的核心价值并不只是简单地少买几台服务器、少堆砌一些额外的组件,而是通过数据库内核和系统架构层面的资源效率优化,让企业在相同硬件资源下承载更多数据、更复杂的查询和更高的业务吞吐,从而降低过早扩容、重复建设和资源浪费带来的长期成本。
面对企业数据库成本不断攀升的现实,YMatrix 提供了一整套系统性的解决方案,从根本上提升单位服务器的有效承载能力,这套方案可以概括为五个方向:
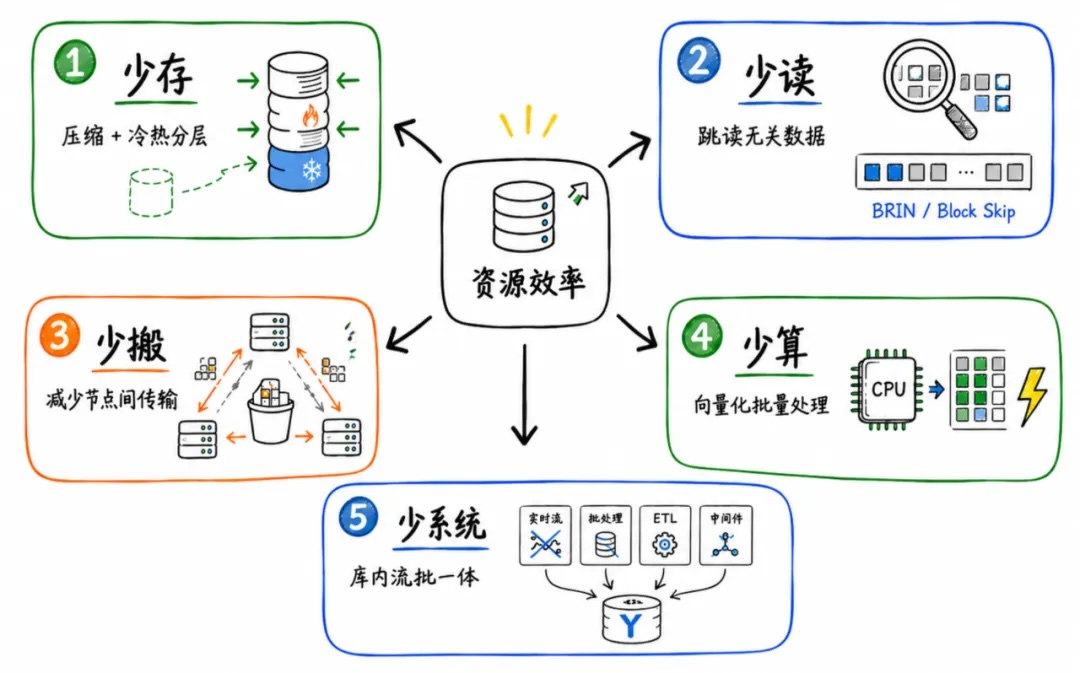
少存
YMatrix 通过自研 MARS3 存储引擎,快速承接新写入数据,并在后台整理为更适合分析和压缩的列式存储形态。同时结合列压缩、索引压缩、自研编码链和降级存储,让数据不仅存得更紧凑,也能根据冷热程度使用更合适的存储资源,减少无效占用和高成本存储浪费。
少读
YMatrix 的 MARS3 存储引擎通过 BRIN、Block Skip 等数据跳读能力,让数据库在扫描前先判断哪些数据块可能匹配查询条件,不相关的数据直接跳过。结合块级统计信息和索引访问路径优化,只有真正需要的数据才被读取。
少搬
分布式查询中,网络传输也是一项大头,YMatrix 通过网络通信压缩和 MARS3 Bucket 降低数据搬运压力。网络通信压缩可以显著减少节点间传输的数据量,而 MARS3 Bucket 则将每个数据节点内的数据进一步按 Bucket 组织,确保在单个数据节点内使用并行查询的场景下,每个并行进程只处理自己负责的数据组,保留本地数据计算和分布语义。这样,节点间不必要的数据搬运将大幅减少。
少算
前面提到的少存、少读、少搬等,本质是在减少磁盘占用、减少无效 I/O 和减少数据传输等。但数据库最终还是要完成计算,CPU 的执行效率直接决定了同样服务器能处理多少查询。YMatrix 通过向量化执行引擎,将数据按批次进行处理,让 CPU 一次处理一批数据,而不是逐行处理,这样便可以更好地利用 CPU 缓存和现代处理器的能力,减少重复开销,让扫描、过滤、聚合、排序、Join 等分析型操作执行得更加高效。
少系统
现今很多企业的成本压力,还来自于数据库之外越来越重的数据链路。为了实现实时分析,传统架构通常需要引入消息队列、流处理引擎、ETL 平台等多套系统。数据在这些系统之间反复流转、落盘和计算,不仅带来更多服务器、存储和网络成本,也让开发、运维、排障和数据一致性管理变得更加复杂。YMatrix 通过 Domino 库内流批一体能力,将部分实时计算、连续聚合和指标更新直接放在数据库内部完成。业务可以使用 SQL 定义持续计算逻辑,当源表数据发生变化时,下游结果可以随之增量更新,像查询普通表一样使用实时分析结果。这样一来,原本需要在外部流处理系统中完成的一部分数据加工,便可以在数据库内闭环完成。
以上这些能力单独看,分别对应磁盘、I/O、网络、CPU 和外围系统成本;放在一起看,则构成了 YMatrix 面向企业级分析场景的资源效率体系。
服务器成本高企时代,数据库系统的竞争逻辑正在发生变化。过去,企业面对数据增长、查询变慢等问题时,最直接的方式往往是通过堆硬件来解决,现今,单纯依赖加机器、加磁盘、加网络、加外围系统的模式,正在变得越来越昂贵,也越来越难以为继。
在这样的背景下,数据库的核心能力不再只是能不能存下数据,而是同样的资源,能不能承载更多有效工作。这也意味着,资源利用效率正在成为比单点性能更关键的评价维度。YMatrix 所强调的降本,并不是简单压缩某一类成本项,而是通过存储、计算、IO、网络以及系统架构层面的整体优化,让数据系统在同等硬件条件下,获得更高的承载密度与更低的扩展频率,让数据库从"依赖堆服务器"走向"真正用好服务器"。






