
导读:2012年伴随“工业4.0”概念的出现,工业大数据能够创造更大的潜在商业价值,核心就是将工业技术与IT技术进行结合,以挖掘工业大数据的价值。本文主要从工业设备的预测性维护(Predictive Maintenance),文中简称(PdM)这一角度出发展开详细介绍。
全文将会围绕下面五点展开:
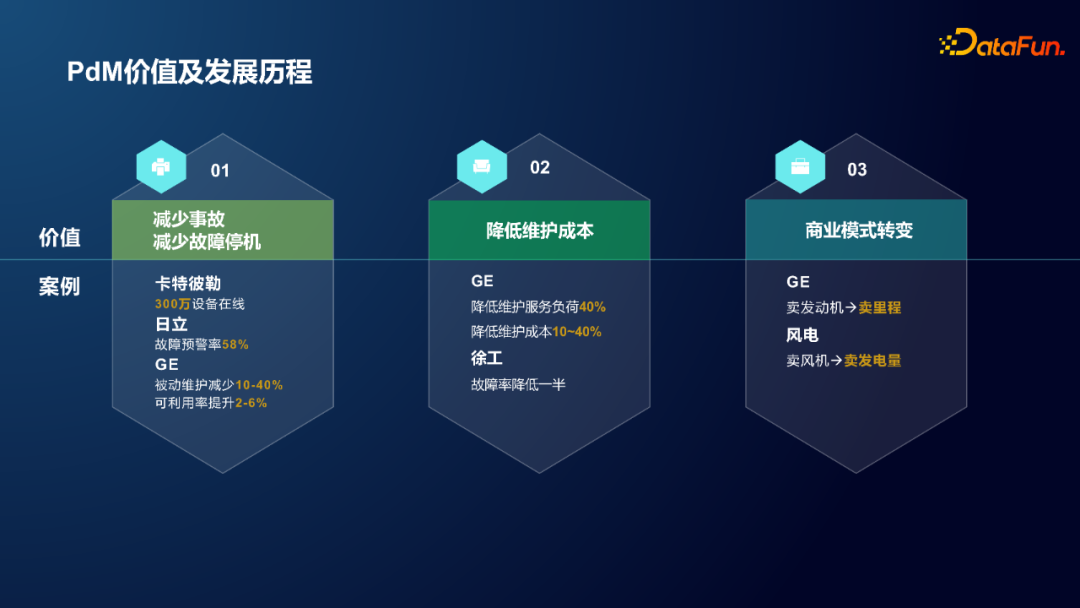
① 减少事故,减少故障停机
保障卡特彼勒300万设备在线。
日立故障预警率可达58%。
GE 在风电和火电这两个领域,被动维护减少10%-40%,可利用率提升2%-6%(可利用率每提升1%,可带来上万户家庭1年的用电量)。
② 降低维护成本
GE 降低维护服务负荷40%,降低维护成本10~40%。
徐工故障率降低了一半。
③ 商业模式转变
以 GE 为例,早先的商业模式是产品制造商,20世纪80年代中期转变成为客户提供服务导向的整体解决方案。比较直观的理解就是从单纯卖发动机这个实体,变成了卖可以保障稳定运行 1000KM 的发动机这样带有业务价值的实体。这其中 PdM 占据了举足轻重的地位。
对于风电行业,在 PdM 的支持下,可以将商业模式从卖风机转变为卖发电量。打破了产品本身因为制造能力扩张和过剩导致的利润转移的约束。
 PdM 是工业设备维护历经百年后的终极产物,发展历程如下:
PdM 是工业设备维护历经百年后的终极产物,发展历程如下:
① 事后维护
早期的设备维护都是事后维护,即事故或故障发生后才维修。
这种维护方式属于被动维护,成本高,效率低。
② 预防性维护
根据设备厂商的建议以及现场人员的经验,定期进行维护。
虽然相较于被动维护有了很大的进步,然而对于运行完好的设备,过多次数的维护会显得冗余且意义不大,而且人工维护也难免造成细节的疏漏,因此这种维护方式依然存在成本较高和效率较低这类问题。
③ 基于状态的维护
基于设备运行状态的实时监控,并结合设备机理模型,在性能评估异常时主动维护。
这种维护方式较为先进,然而仍然免不了突发故障停机的风险。
④ PdM
基于数理统计、数据挖掘模型,对初期部件故障预测及定位,指导设备维护工作。
这种维护方式,可以在故障未发生时提前介入,最大程度地避免故障及事故的发生。
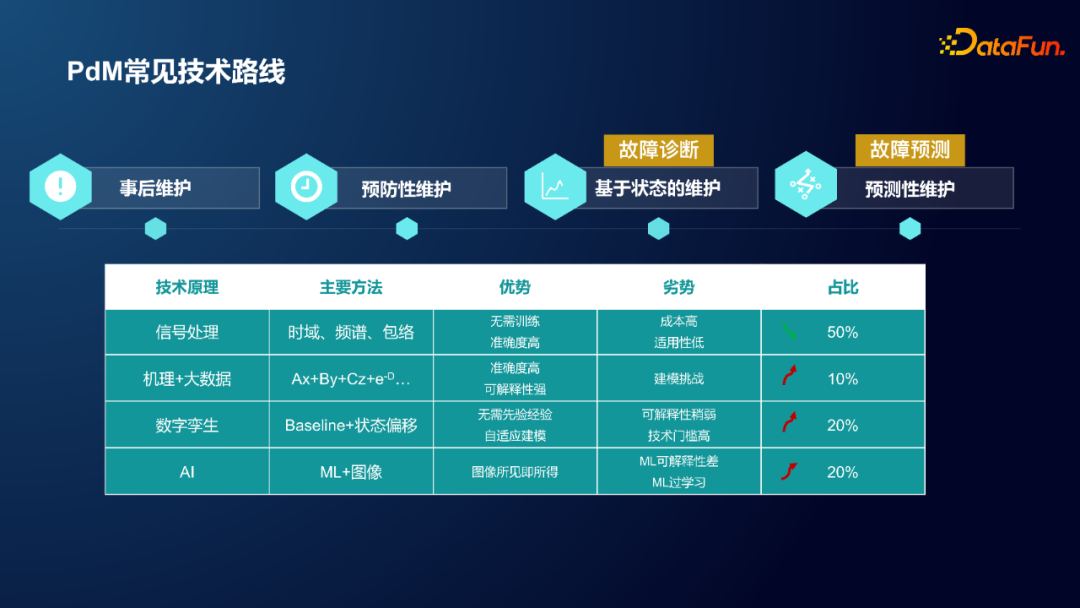 基于前文所述,PdM 的技术路线部分主要会详细介绍基于状态的维护和 PdM 这两个部分,主要技术涵盖大数据、物联网以及人工智能等诸多方面;基于状态的维护又被称为故障诊断,PdM 又被称为故障预测。
基于前文所述,PdM 的技术路线部分主要会详细介绍基于状态的维护和 PdM 这两个部分,主要技术涵盖大数据、物联网以及人工智能等诸多方面;基于状态的维护又被称为故障诊断,PdM 又被称为故障预测。
业内常用4种方法:
① 信号处理
主要是基于 IoT 高频采集信号,使用时域、频域、包络、小波分解等经典方法,对测量信号和噪声进行分析。
该方法无需对数据进行训练,且分析结果准确性高,方法成熟度高,在业内的使用超过50%。
然而从工程应用的角度看,传感器具有较高的安装和维护成本,且难以覆盖全面测点,因此该方法的适用范围具有较大的局限性。
② 机理 + 大数据
对于成本较敏感的行业(例如工程机械领域),可以使用机理建模方法,结合大数据方法进行分析。
首先建立基础的机理模型(例如气动方程、液压动力方程等),通过采集关键信号(例如转速、压力、电压、电流等),从而拟合方程中的参数。
该方法可解释性强,结果准确性高,且不易出现过拟合现象,不过机理建模的过程具有挑战性。
③ 数字孪生
数字孪生方法,摆脱了前两种方法对于机理的依赖。
该方法基于历史运行数据,通过一系列相似性模型构建设备的基准状态(baseline)并进行预测;将预测的结果与设备的实时运行状态进行对比,对状态偏移进行预警。
该方法是一种自适应的建模方法,可解释性弱于机理模型,且需要一定的技术门槛。
④ AI
最后一种方法是使用 AI 领域的一些技术(例如机器学习、深度学习、CV、NLP 等方法)。
该方法场景清晰且易得,图像所见即所得,然而该方法可解释性差,且容易过拟合。
综上所述,机理+大数据的方法和数字孪生方法,应该会成为未来的趋势。
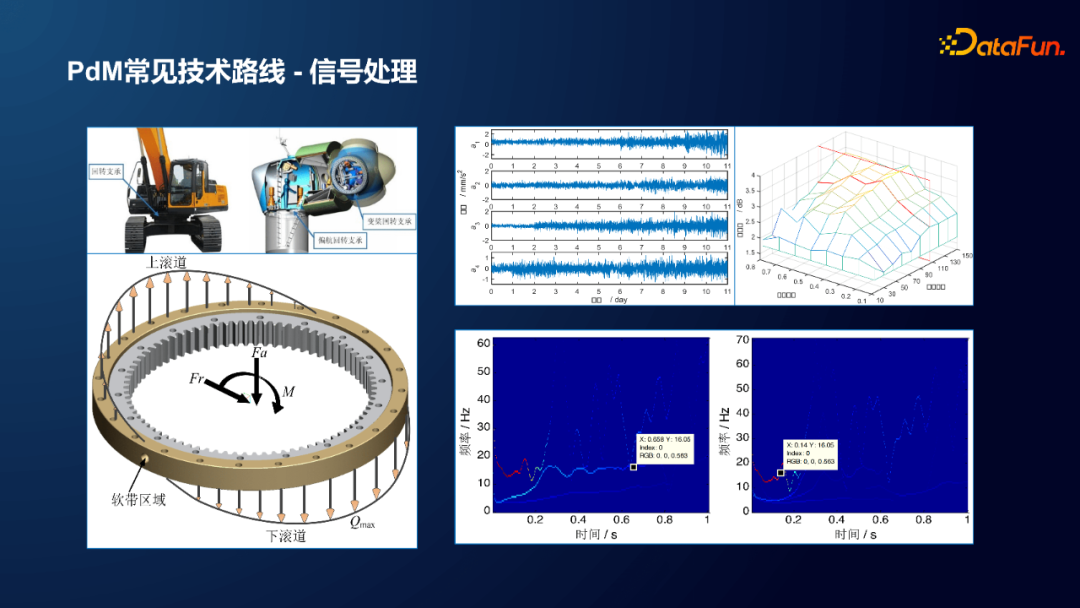 针对一台工程机械,以大轴承为例,长期运转会不可避免地带来一些损坏。通过采集振动信号(如图所示,采集了4路振动信号),通过傅里叶变换、EMD、小波、包络等方法进行信号分解得到某时段内的时频谱;通过分析信号的频域特征,来推断轴承在什么时段可能会出现问题。
针对一台工程机械,以大轴承为例,长期运转会不可避免地带来一些损坏。通过采集振动信号(如图所示,采集了4路振动信号),通过傅里叶变换、EMD、小波、包络等方法进行信号分解得到某时段内的时频谱;通过分析信号的频域特征,来推断轴承在什么时段可能会出现问题。
 以某液压系统为例,左下图中的红色直线为该液压系统的基准线,然而事先并不知道斜率、截距等参数的具体取值;此时可以基于样本数据进行拟合,以推测出实际的参数值。如果设备运行良好,则散点应该集中分布在拟合直线的周围;图中列举了两种拟合不理想的情况:左图中,由于参数控制不当,图的右侧出现了“死区”,右图中,由于系统出现内泄,直线和红线的趋势产生了差异(说明在高压和低压状态下系统的特性是有所不同的)。基于此,我们可以通过斜率的绝对值与原厂的油泵特性理论值对比判断油泵整体效率,再通过高低压模式差异值反应液压系统内泄程度(性能退化程度)。
以某液压系统为例,左下图中的红色直线为该液压系统的基准线,然而事先并不知道斜率、截距等参数的具体取值;此时可以基于样本数据进行拟合,以推测出实际的参数值。如果设备运行良好,则散点应该集中分布在拟合直线的周围;图中列举了两种拟合不理想的情况:左图中,由于参数控制不当,图的右侧出现了“死区”,右图中,由于系统出现内泄,直线和红线的趋势产生了差异(说明在高压和低压状态下系统的特性是有所不同的)。基于此,我们可以通过斜率的绝对值与原厂的油泵特性理论值对比判断油泵整体效率,再通过高低压模式差异值反应液压系统内泄程度(性能退化程度)。
使用机理+大数据这种方法可以很大程度地减少对数据标签的依赖。
(1)数字孪生介绍
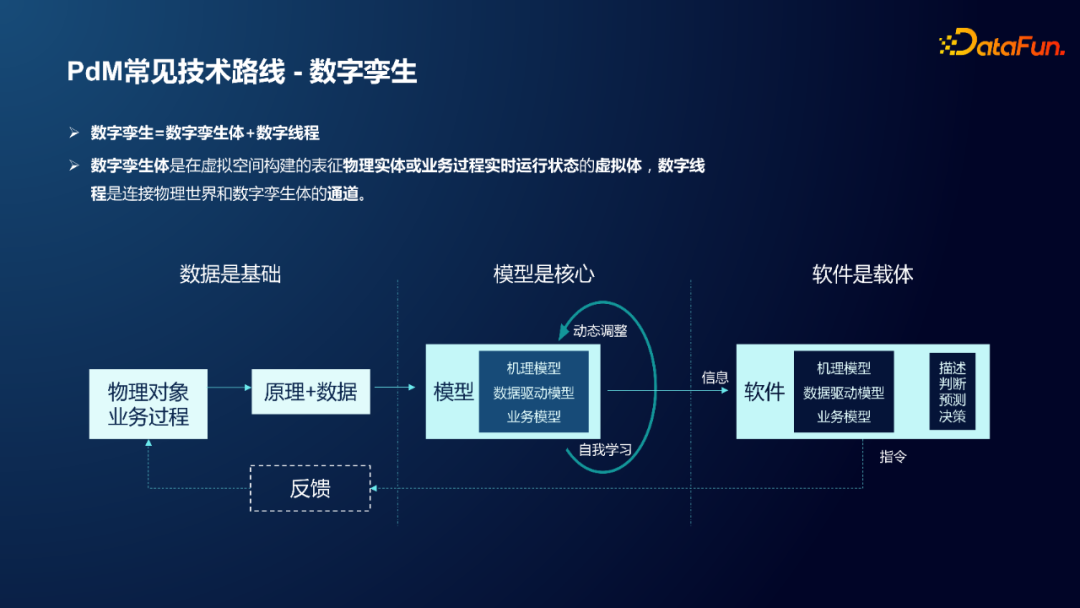 数字孪生是个很宽泛的概念,这里所讲的数字孪生,主要是基于国际标准 ISO23247/TC184 工作组定义的数字孪生,包括数字孪生体和数字线程两个部分。数字孪生体是在虚拟空间构建的表征物理实体或业务过程实时运行状态的虚拟体,数字线程是连接物理世界和数字孪生体的通道。
数字孪生是个很宽泛的概念,这里所讲的数字孪生,主要是基于国际标准 ISO23247/TC184 工作组定义的数字孪生,包括数字孪生体和数字线程两个部分。数字孪生体是在虚拟空间构建的表征物理实体或业务过程实时运行状态的虚拟体,数字线程是连接物理世界和数字孪生体的通道。
通过设备的原理和运行数据,将数据给到模型,模型通过自我学习和动态调整将分析结果输出到终端软件中,由终端软件控制和反馈物理对象和业务过程,最终形成闭环。上述闭环以数据为基础,以模型为核心,以软件为执行载体,这是数字孪生的主要实现手段,而实现闭环的链路通道就是我们常说的数字线程。
(2)使用数字孪生实现 PdM
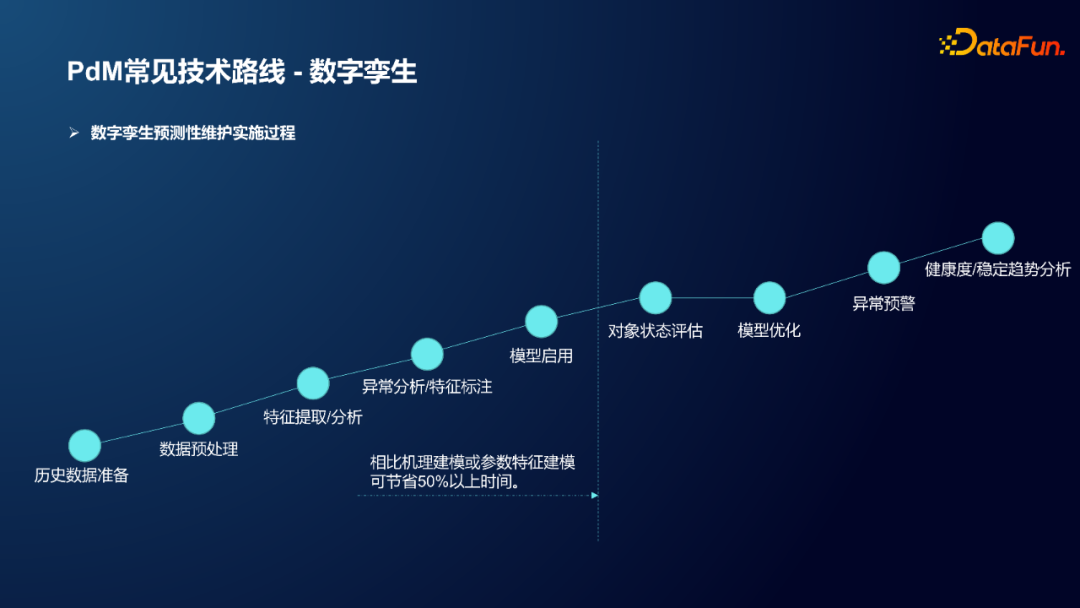
基本步骤如下:
历史数据准备
数据预处理
特征提取/分析
异常分析/特征标注
模型启用
对象状态评估
模型优化
异常预警
健康度/稳定趋势分析
相比机理建模或参数特征建模,该方法可节省50%以上时间。
(3)数字孪生 PdM 技术原理
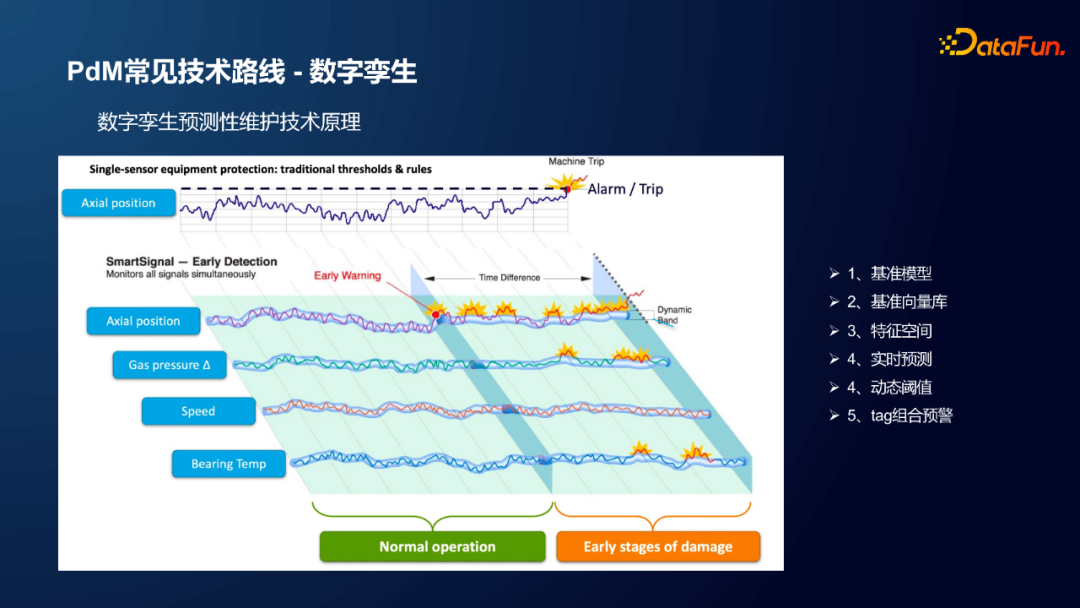
在数字孪生 PdM 领域,常用的方法是相似性模型。
传统方法的故障预警是预先设定报警阈值,一旦监控到数据超过阈值,就会发出警报;然而这种方法存在滞后性,即发出警报的时刻设备已经故障了,因此即使报警也无法避免设备的停机甚至损坏。更好的方法是将这个固定的阈值转化成动态的阈值,不同时刻、不同工况下,监控信号的报警阈值都是动态变化的,这样就可以基于设备的不同运行工况进行实时报警。

基于数字孪生的 PdM ,主要包括异常识别(预测模型)和故障推导(故障机理)这两个部分。
可以拿我们自身做一个形象地比喻:我们在跑100米的时候会有一个正常范围的心跳值。同样,在跑1公里、跑20公里的时候,以及在安静状态甚至睡眠状态下,分别会有不同的心跳范围。基于过去半年或者一年累计的数据进行统计,可以推算出当今某种特定状态下(例如跑200米)身体的机能是否和往年比有所下降,进而而可以判断出自己身体的是否健康。
因此,基于数字孪生做 PdM 的核心思想是:
收集丰富工况下物理对象的状态矩阵,并将它们汇聚成基准状态空间,即为数据驱动的数字孪生模型。
此模型能够根据当前工况,预测出这个工况下状态“应该”是怎么样的,通过它与现实状态的偏差识别异常(即异常识别)。
根据异常指标的组合,结合专家知识,判定可能的异常根因和应对方法(即故障推导)。
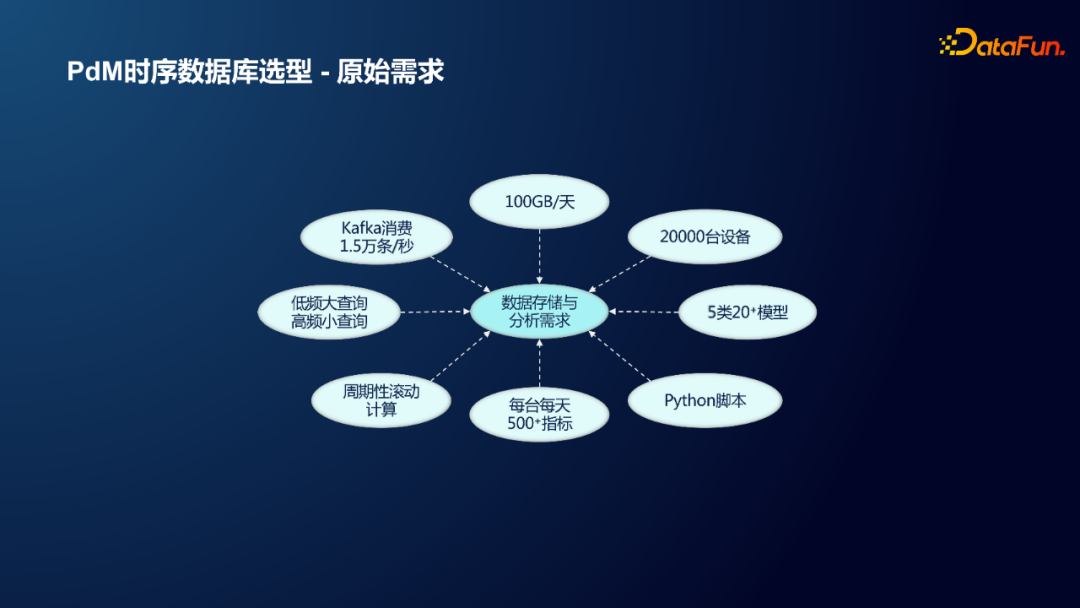
基于上述方法在 IoT 方向上做 PdM ,无论是汽车行业还是工程机械、批量机械设备等方向,都会涉及大量设备的监测和分析;因此,如何在海量数据中应用上述方法对设备进行 PdM,并精准分析出每台设备的分析结果,都是一项具有挑战性的工作。
例如,针对以下场景:
① 对某现场 2W 台设备进行维护
② 每天会产生 100~200G 的数据量
③ Kafka 消费每秒可达 1.5W条
④ 通常涉及低频大查询和高频小查询
大查询:每台车有 200 个指标,每个指标都要跑。
实时小查询:例如挖机,需要实时查看我的挖机的工作量。
⑤ 往往需要进行周期性滚动计算
⑥ 每台设备每天进行超过 500 个指标的计算
⑦ 涉及 5 类,累计超过 20 个算法模型
⑧ 算法逻辑往往通过 python 开发实现而不是SQL
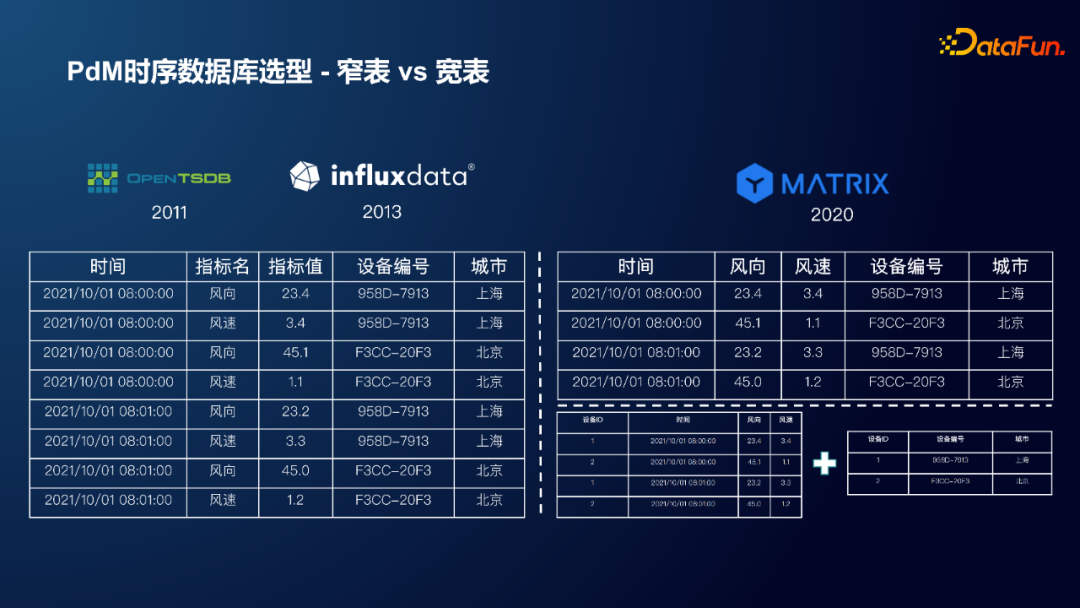 基于以上原始需求,带来了一个核心问题——使用窄表存储还是宽表存储。从运维人员的角度考虑,使用窄表会更加便于维护,因为窄表的列名是固定的,不会发生改变;从业务应用的角度考虑,使用宽表会使业务语义更加清晰,可以快速获得某一特定指标的某一段时间的数据。
基于以上原始需求,带来了一个核心问题——使用窄表存储还是宽表存储。从运维人员的角度考虑,使用窄表会更加便于维护,因为窄表的列名是固定的,不会发生改变;从业务应用的角度考虑,使用宽表会使业务语义更加清晰,可以快速获得某一特定指标的某一段时间的数据。
 从存储角度来看:
从存储角度来看:
行列混合存储,可以对数据进行压缩,对分析查询更加友好。
同一类型的数据放在同一个列中,有利于数据压缩。
同一个设备的数据,按时间顺序存储在一个 block 内,对设备的分析查询和向量化来说更加友好。
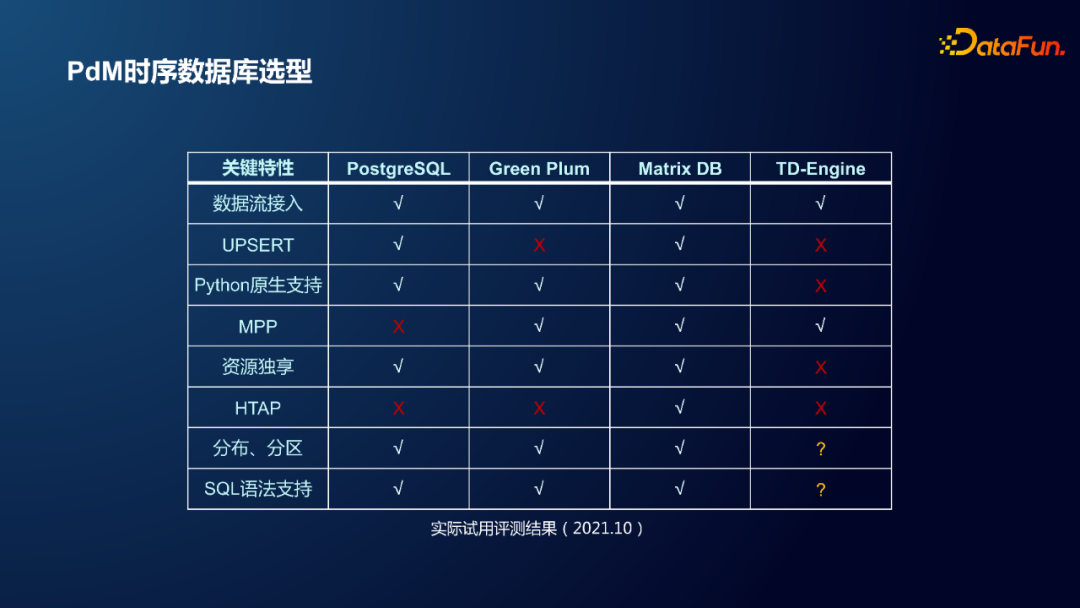
基于以上需求,通过调研,对比了常用的 PostgreSQL、GreenPlum、MatrixDB、TD-Engine 等数据库的优劣,最终选择了 MatrixDB 作为存储工具,可以实现2W台设备,每天100~200G的数据量,每台设备每天进行超过20个算法模型、超过500个指标的计算分析需求。
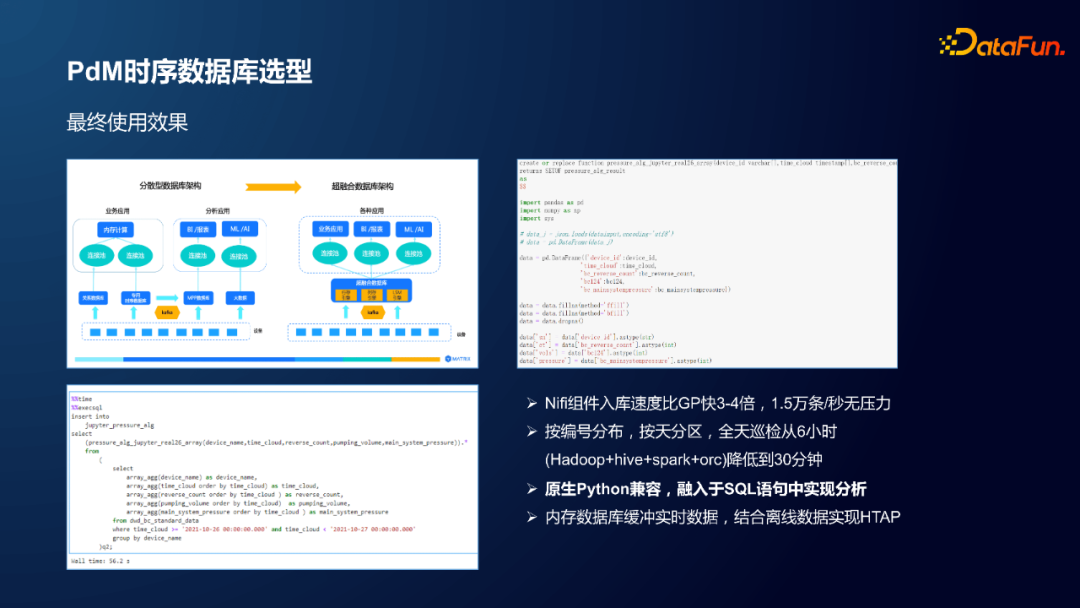
MatrixDB 数据库是个超融合数据库:
支持 HTAP。对于导入数据库的数据,既可以做实时查询,也可以做离线 OLAP 分析。
支持 plpython 编程。实现了数据库维护工作和算法开发工作的解耦,大大提高了算法开发的效率。
Nifi 组件入库速度比GP快3-4倍,1.5万条/秒无压力。
Plpython+UDF 的效率更高。例如:按编号分布,按天分区,全天巡检从(Hadoop+hive+spark+orc) 6小时降低到30分钟。
原生 Python 兼容,融入于 SQL 语句中实现分析。
内存数据库缓冲实时数据,结合离线数据实现HTAP。

无论是数据库的提供方,还是作为使用数据库的甲方,甲方会关心收益。因此,PdM 需要更多地聚焦在客户的痛点上,抓住要点,给客户提供看得到的价值,客户的问题会逐渐得到解决。

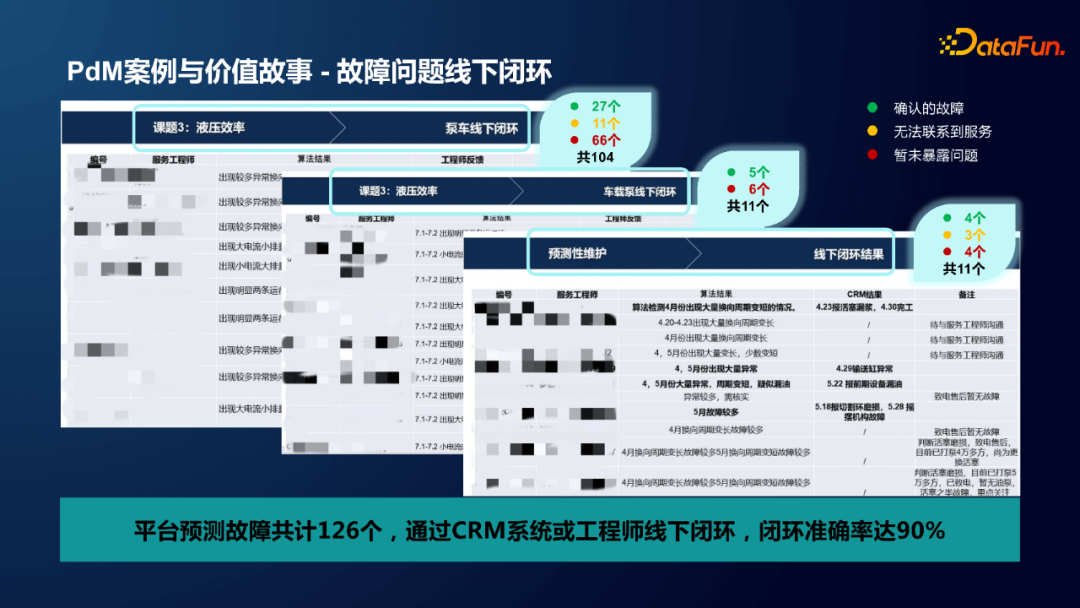
无论企业规模大小,制造业的数字化转型人才大多来自互联网,首先带来的必然是互联网的最佳实践:围绕 Hadoop + Spark + HIVE 等搭建生态,这是第一层认知。
转型初期,上述生态的确可以承载企业急需解决的部分数字化的问题,比如“研产供销服”对应的业务数据的打通、各种KPI的计算、BI类的报表等,解决一部分问题,这是第二层认知。
当转型进入深水区,比如在研发侧,公司研发的设备客户哪里不满意,我需要怎样的改进,改进的效果如何?在生产侧,我的生产管理流程如何优化,我如何提升工厂生产的各类指标?当我们面临这些问题时,才发现,每一个问题都需要分析海量的数据,并且分析的方式再也不是统计、聚合类的,而是要结合工业机理的,甚至是要逐条地分析,基于Hadoop的那套生态几乎彻底不能承载我们快速开发算法、调度算法的性能需求。此时,公司面临的将是要么不断贴膏药勉强维持,要么再斥巨资引入适应这些需求的IT技术,这是第三层认知。
令人遗憾的是,大多数先驱公司都是从第1条慢慢往后演进的,不过同样令人欣慰的是,也有越来越多的人看到这个过程,在业务初期就尝试运用像 MatrixDB 这样的跨界产品来一站式解决问题。
Q:为什么 TDengine+Spark 不是最优选择?
A:TDengine 需要用 Spark 集群做分析,而 Spark 从数据入库到分析,存在诸多的不稳定性。而使用Hadoop+Spark的方式,要比使用 MatrixDB 分析效率慢7-10倍。
Q:在工业领域,除了时序数据,是否还有其他数据类型和时序数据协同分析?
A:在PdM 方面,大部分还是来自IoT时序数据;在一些极端情况下,会有描述设备本身标识的维度数据,比如设备的每个子系统、每个零部件的供应商、编号、部件特性等的维度数据。这类数据作为关系型数据库,可以被兼容到 MatrixDB 这样的超融合数据库中。
Q:频域能否做 PdM 研究?
A:虽然在风电等领域,频域分析仍占半壁江山。但是由于其成本的原因,其扩张速度正在收敛,甚至呈现出下降的趋势。随着成本竞争日趋激烈,很难大规模部署传感器;另一方面,从存储成本角度考虑,也很难支持大量1kHz甚至10kHz这类高频数据上云。因此,在物联网、大数据领域,更多地会使用机理+大数据,以及数字孪生这两种方式进行PdM。
Q:是否分析过 IoTDB 或者 MatrixDB 结合 model in 将数据下载做离线计算?
A:这方面没有具体尝试。不过只要是先将数据下载进而离线分析计算,这类工作都会增加工作的难度,降低工作的效率。团队之所以放弃Hadoop+Spark的方式,正是因为这类方式需要预先下载数据进而分析计算。分析和存储查询分离的方式,一般会出现大量的数据迁移,通常情况下会降低分析的效率。
Q:工业时序领域哪些时序类函数是强需求?例如异常检测、预测类算法等,如果集成在数据中,开发效率会不会更友好?
A:工业领域的数据分析和互联网领域存在截然的不同:工业数据分析,很难用一个公式解决大量设备通用问题。信号处理方法在一定程度上可以解决一大类通用问题的分析,但是采样率要求很高,因此会带来成本的增加,从而导致适用范围的局限性;因此,大部分企业会使用机理+大数据,以及数字孪生这两种方式,而这两种方式不具备通用性,对于不同设备甚至同一设备不同型号,机理模型都会发生变化。因此,工业领域的机理模型或者数据模型,很难得到抽象的、通用的、能够注入到数据中的模型;因此通常做法是先获取相关数据,进而通过不同的尝试,最终确定模型。
今天的分享就到这里,谢谢大家。






