
实时数据仓库的建设,当前主流方案集中在两种技术路线:Lambda架构和流批一体架构。两者各有适用场景,选择取决于业务需求与技术成本约束。
传统数据仓库的核心在于批处理。常见场景是:各业务系统的数据在白天进入数据库,需要经历漫长的等待,通常在每天深夜或固定时段被统一抽取,经过数小时的清洗、转换,最终加载进入仓库。这种模式下,业务人员清晨打开报表,看到的往往是昨日甚至更早的数据。这并非技术人员的懈怠,而是架构本身决定了“T+1”甚至“T+N”的宿命。其存储引擎也常在行存与列存间艰难抉择:行存利于更新点查,列存擅长分析扫描,却难以兼得,常常需要复杂的Lambda或Kappa架构拼接,徒增运维负担。
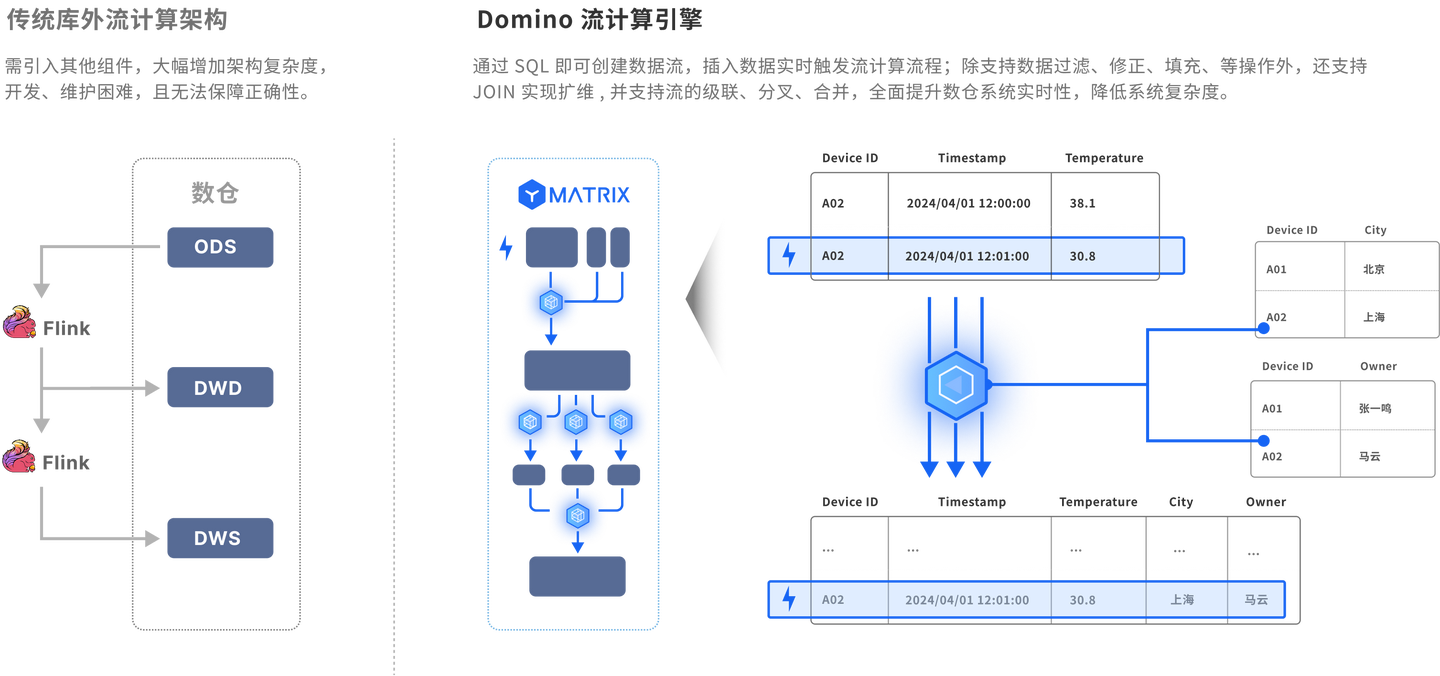
而现代实时数据仓库则带来了根本性的变革。它采用流批一体架构,如同为数据流动铺设了一条高速公路。数据产生后,能以秒级甚至毫秒级的极低延迟,通过像YMatrix,SuperSQL这样的原生流计算引擎,直接汇入数仓。这意味着,生产线上传感器的最新读数、用户刚刚完成的交易记录、服务器集群的瞬时负载状态,都能近乎实时地被捕捉、处理和分析。更关键的是,流批一体并非简单叠加,而是实现了底层统一,一份数据可同时服务于实时监控与深度历史分析。
在存储层面,多模融合技术彻底打破了传统单一模式的桎梏。以YMatrix为代表的超融合数据库,其核心在于一个存储引擎同时高效支撑行存、列存、时序乃至KV等多种数据模型。以新能源汽车为例,一份车辆运行数据,既能被工程师快速查询某个传感器在特定时刻的状态(行存点查优势),又能被分析团队用于计算全车队过去一个月的平均油耗(列存扫描优势),还能被用于预测某个关键部件的剩余寿命(时序计算优势)。这种融合消除了数据冗余拷贝和同步延迟,简化了技术栈,释放了前所未有的性能潜力。
速度是实时数仓最直观的体现。传统数仓的数据延迟通常在小时级到天级徘徊,业务决策如同空中楼阁。而实时数仓则将延迟压缩至秒级甚至亚秒级,让决策者能够清晰感知当下情况,这个时候BI的实时仪表盘才真的实现。
同时,实时数仓在并发处理能力上也展现出巨大优势。传统架构在面对用户激增和查询复杂度提升时,往往力不从心,扩容复杂且成本高昂。而现代分布式实时数仓设计之初就面向高并发与线性扩展,能够从容应对数千乃至上万用户的同时在线交互分析,确保业务高峰期的流畅体验。
强一致性保证了数据质量。某些专用场景(如财务结算)宜采用流批一体的ACID事务保障。
技术服务于场景。传统数据仓库在特定领域仍有其价值。但有些场景对实时的需求已经无法忽视:
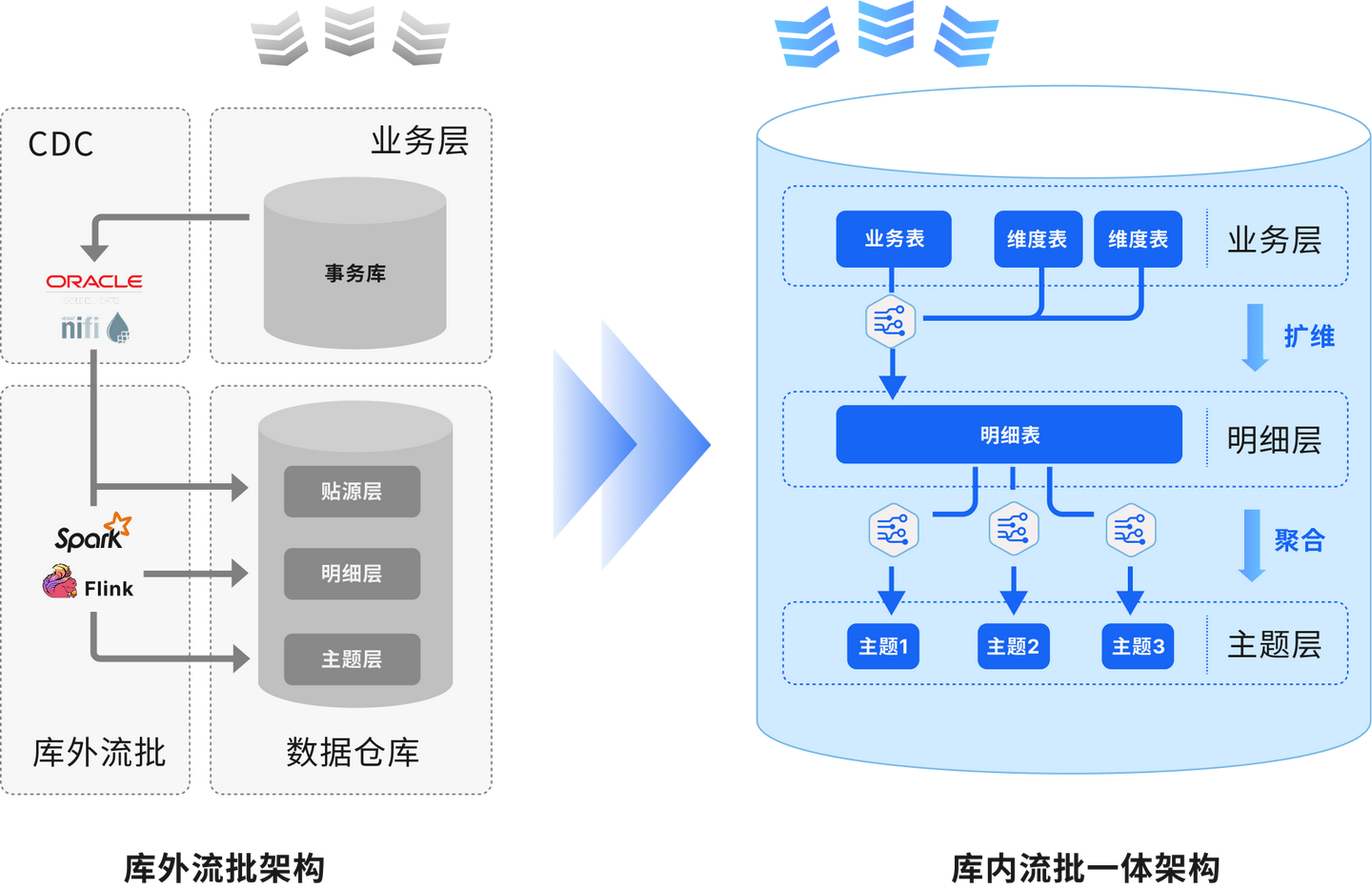
而流批一体架构通过统一存储与计算层解决Lambda的痛点。存储层采用支持事务更新的数据湖(如Iceberg)或MPP数仓,同一份数据既能接收实时写入,也能支持历史批量查询。计算层利用流引擎的批流融合能力,通过相同SQL语法处理实时流与离线数据。例如零售企业用Flink SQL同时计算实时订单流水(流模式)和历史用户复购率(批模式),避免逻辑重复开发。
该架构的核心价值在于降低运维复杂度。当金融业务需修正历史交易记录时,直接在数据湖中更新分区即可,无需重跑全量任务。但流批一体对时效性存在妥协:复杂查询可能产生分钟级延迟,不适合毫秒级响应的反欺诈场景。
实时数据仓库的兴起,绝非简单的技术升级,而是一场从理念到架构的深刻变革。它用流批一体打破了批处理的枷锁,用多模融合终结了存储的割裂,最终实现了从“事后诸葛亮”到“当下决策者”的跨越。这场变革的本质,是将数据从历史的记录者,转变为驱动业务实时前行的核心引擎。






