上一节介绍了MatrixDB如何为时序数据建模。而MatrixDB是一款分布式数据库,在数据存储上与单机数据库不同。本节将介绍MatrixDB的分布式架构,以及基于现有分布式架构应该如何设计数据表的分布方式。
本课程教学视频请参考MatrixDB数据建模与时空分布模型
MatrixDB是一款中心化架构的分布式数据库,包含master和segment两种类型节点。
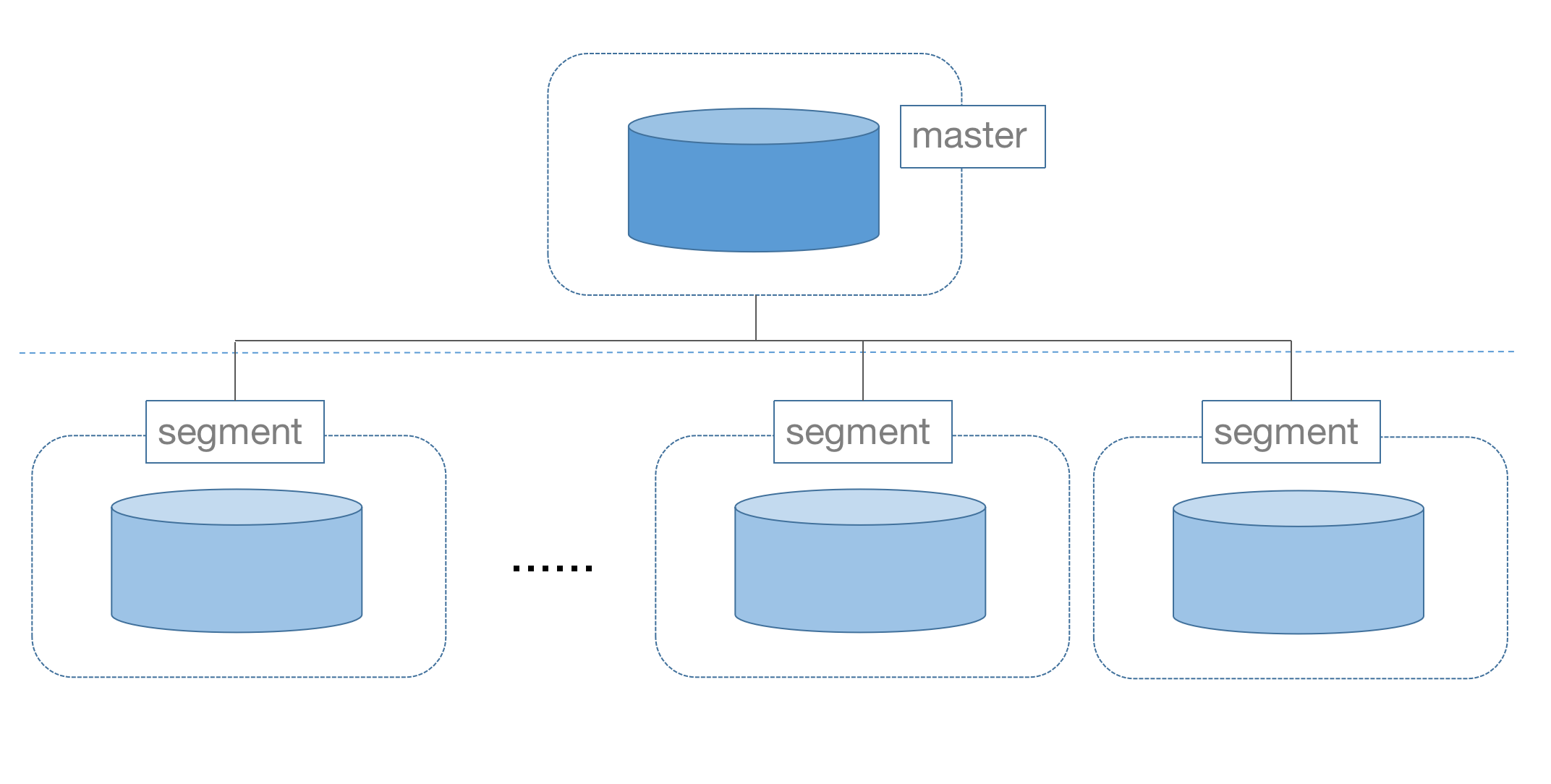 master是中心控制节点,用来接收用户请求并生成查询计划。master节点并不存储数据,数据存储在segment节点上。
master是中心控制节点,用来接收用户请求并生成查询计划。master节点并不存储数据,数据存储在segment节点上。
master节点只有一个,segment节点至少有一个,可以更多,几十个甚至上百个。segment节点越多,集群可以存储越多数据,计算能力也越强。
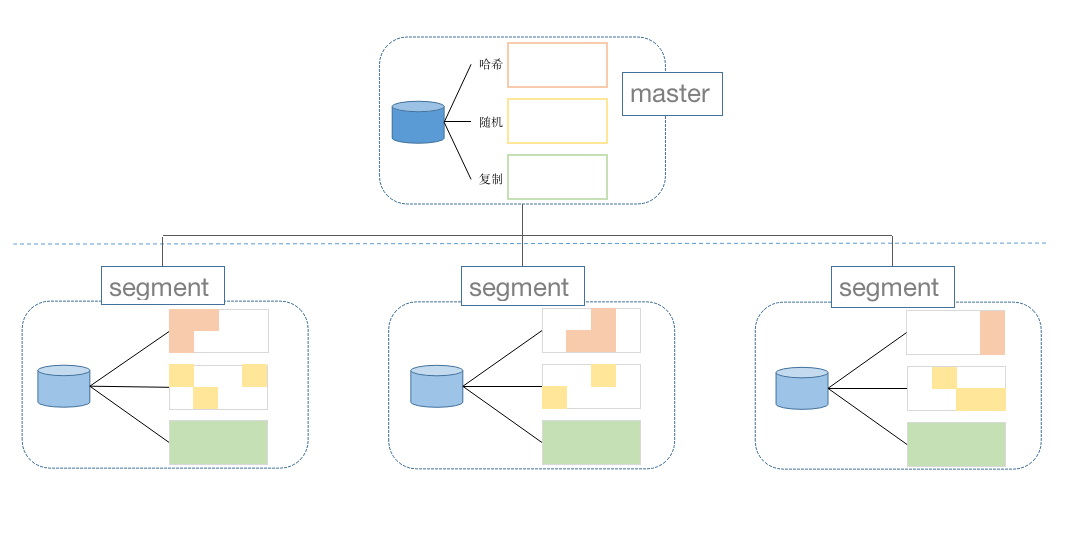
MatrixDB数据表在segment上有两种分布策略,分片和冗余;分片又分为哈希和随机两种分片方式:
分片分布即将数据水平切分,一份数据只存储在其中一个节点上。哈希分片需要定义哈希键,可以是一个或多个,数据库对哈希键计算键值来决定存储在哪个节点上。随机分片则将数据随机分配到一个节点上。
冗余分布则将数据冗余存储在每个数据节点上,即每个数据节点都包含表中的所有数据。这种方式会占用大量存储空间,所以只有经常需要做连接操作的小表才使用冗余分布。
综上,数据分布总共3种策略,不同的分布策略,在创建表的时候可以通过Distributed by关键字来设置:
分布式架构下的MatrixDB,大部分数据表都采用分片存储,但是可以支持全部关系查询。从用户角度来看,就是一个空间无穷大的PostgreSQL。
那么,对于跨节点的数据连接如何做呢?这得益于MatrixDB的Motion操作,当满足连接条件的数据不在同一个节点上时,会将它们移动到相同节点上做连接。
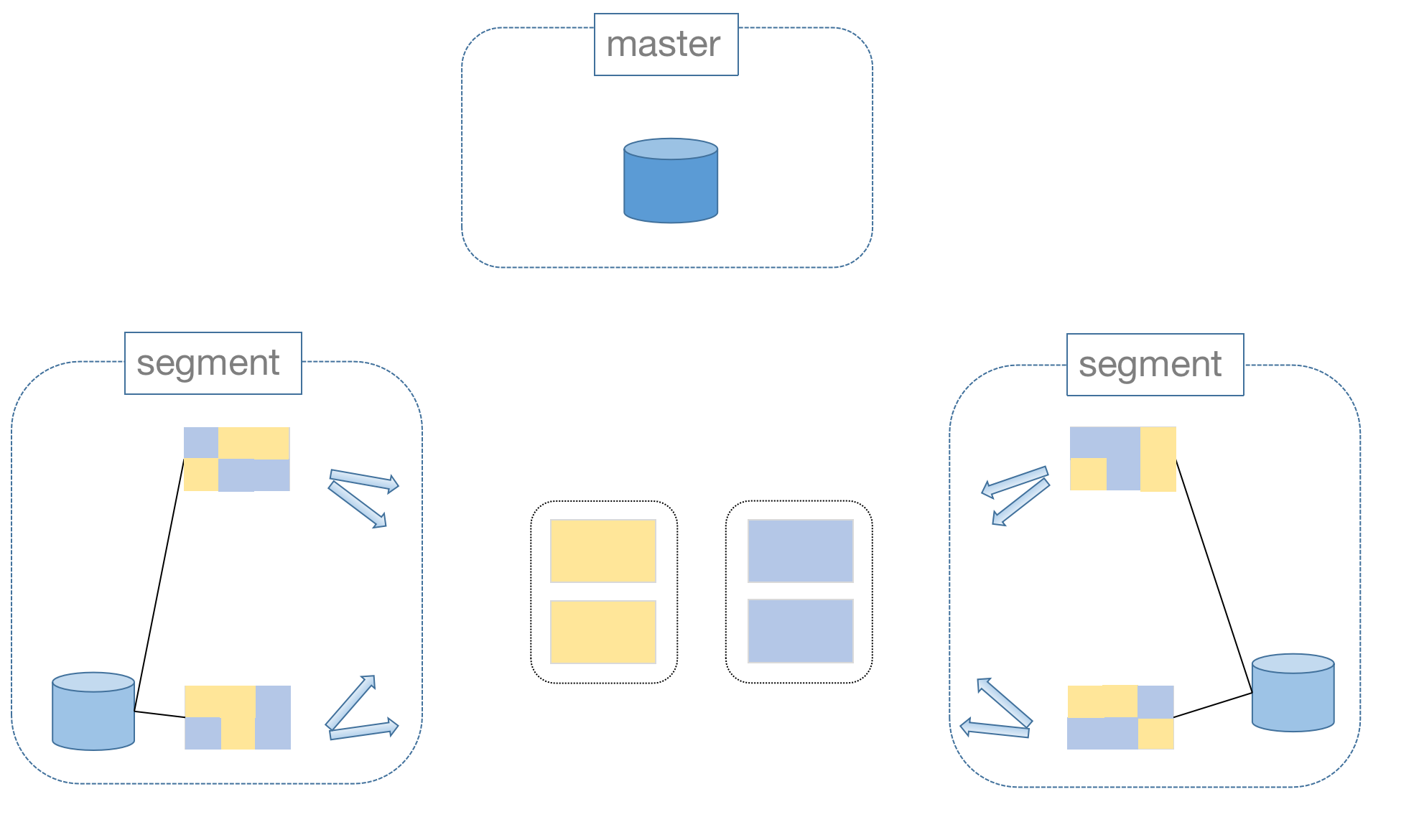
当然,做移动操作是有成本的。所以,在设计表的时候,要充分考虑数据分布特征与后期要进行的查询类型来综合决定分布策略。
只有满足连接条件的数据完全分布在相同的节点上才可以避免移动操作。所以经常要做连接操作的大表,最好将连接键设置为分布键。
了解了MatrixDB数据分布方式与利弊,下面讨论一下时序数据表应该采用哪种分布策略。
首先考虑一下指标表,指标数据量非常大,不可能采用冗余分布方式,而随机分布又没有任何规律,不利于后面的统计分析,所以哈希分布是首选。那又该如何确定分布键呢?
时序表数据包含3个维度:
后面的统计分析基本都是以设备并连接设备表的其他属性作为分组键,所以使用设备ID作为分布键。
设备表数据规模相对固定,不会像指标数据那样无限增长,所以一般采用冗余分布方式。这样,在和指标表做连接操作时无需做跨节点的数据移动。






