本文档介绍了 MatrixDB 支持的存储引擎及存储诊断工具,主要包含以下内容:
存储引擎是数据库系统的存储基座,数据库基于存储引擎进行数据的创建、查询、更新和删除等操作。根据你的需要,不同的存储引擎将提供不同的存储机制,在物理布局,索引类型,锁的粒度等不同维度进行设计。
目前 MatrixDB 数据库系统支持以下存储引擎的使用:基于 PostgreSQL 的 HEAP、MatrixDB 自研发的 MARS2以及列存引擎 AOCO、行存引擎 AORO。
HEAP 表为传统 PostgreSQL 数据库提供的存储引擎,又称堆表。该类型的表支持大量并发读写、事务、索引等特性。
MARS2 表凭借其物理有序的合并方式,减少 I/O 寻址的次数,从而提高对表内数据的查询性能。同时,MARS2 支持压缩、列存、自动归档、预聚集等功能,在时序场景中表现优越。
MARS2 当前暂不支持更新和删除。
依据两种存储引擎的不同特性,你可以在不同的场景需求下灵活创建不同的表。我们给出以下示例。
HEAP 表为 MatrixDB 默认存储引擎,因此如果你建表时没有特殊指定存储引擎,创建的则均为 HEAP 表。
=# CREATE TABLE disk(
time timestamp with time zone,
tag_id int,
read float,
write float
)
DISTRIBUTED BY (tag_id);MARS2 表依赖 matrixts 时序扩展,在建表前,首先需要你在使用该存储引擎的数据库中创建扩展。
注意!
matrixts扩展为数据库级别,一个数据库里面创建一次即可,无需重复创建。
=# CREATE EXTENSION matrixts;建表时使用 USING MARS2 来指定存储引擎:
=# CREATE TABLE vehicle_basic_data_mars2(
daq_time timestamp encoding (minmax),
vin varchar(32) COLLATE "C" encoding (minmax),
lng float encoding (minmax),
lat float encoding (minmax),
speed float ,
license_template varchar(16) ,
flag integer
)
USING MARS2
WITH (compresstype=zstd, compresslevel=3)
DISTRIBUTED BY (vin)
PARTITION BY RANGE (daq_time)
( START ('2022-07-01 00:00:00') INCLUSIVE
END ('2022-08-01 00:00:00') EXCLUSIVE
EVERY (INTERVAL '1 day')
,DEFAULT PARTITION others );我们将对 vehicle_basic_data_mars2 表中的具体参数和语句做一些说明:
min、max、avg、sum、count 等聚集查询,或者进行 WHERE 条件过滤时需要加上这个选项。这个选项的添加需要根据业务场景来确定,不要不加思考地添加至全部的字段,否则这种操作会带来很多无端的数据写入 CPU 以及磁盘 I/O 的消耗。 zstd,还有 rle_type,zlib,lz4 压缩算法,此表中推荐使用 zstd,压缩级别使用 3 级。压缩性能相关参数具体见下文表格。设备编码字段作为分布键,从而可以查询同一个设备的的数据,并进行相关计算。避免了节点之间的数据重分布带来的性能损耗。设备采集数据的时间作为分区键。通常大量查询都是筛选数据采集的时间。例如,当你想要查询一天内的数据并进行相关的计算,你就需要加上过滤条件 WHERE daq_time >= CURRENT_DATE - INTERVAL '1 day' ,这样数据库就会快速的判断出数据在哪个分区子表上,从而快速的将数据定位并查询表出来。START...END 语句以及 INCLUSIVE、EXCLUSIVE 关键字创建从 2022-07-01 00:00:00 开始到 2022-08-01 00:00:00 截止的子分区表。1 天,除了以 day 为单位,你也完全可以使用 hour、month、year 等,根据数据量的规模来确定即可。例如,在一天的时间里,你的服务器接收到了高达 100万~1000万 条数据,那天以 1 day 作为时间间隔就是最佳选择;如果一天的数据量只有十几万或几十万,那么选择 1 month 就很合适;如果每天的数据量不过万级,那么 1 year 子分区表生成一次即可。 注意!
我们希冀你会根据我们的建议设计建表思路,但我们不希望你盲目套用。具体的时序场景千变万化,具体情况具体分析仍是非常必要的。
上文提到的 MARS2 表压缩性能相关参数:
| 参数名 | 默认值 | 最小值 | 最大值 | 描述 |
|---|---|---|---|---|
| compress_threshold | 1200 | 1 | 8000 | 压缩阈值。用于控制单表多少元组(Tuple)进行一次压缩,是同一个单元中压缩的 Tuple 数上限 |
| compresstype | lz4 | -- | -- | 压缩算法,支持: 1. zstd 2. zlib 3. lz4 |
| compresslevel | 1 | 1 | -- | 压缩级别。通常值越小压缩率越小,但压缩越快;值越大压缩率越高,但压缩越慢。不同的算法有效值范围都不同: zstd:1-19 zlib:1-9 lz4:1-20 |
注意!
一般而言,zstd符合压缩级别越高,压缩率越高,同时速度越低。但这并不绝对。
创建 MARS2 表成功后,你必须额外创建一个 mars2_btree 类型的索引,这样才能进行正常的数据读写。使用索引排序的目的是使得同一维度或相似特性的数据尽可能的在物理上靠近,以减少 I/O 寻址的次数,提高查询效率。因此排序键的选择需要符合主要的业务查询特征。
例如需求是单设备点查询,那么排序键就是时序场景中的设备号 (vin),如果需求是单设备在某时间段内明细查询、聚集查询或多设备查询,那么排序键就是设备号以及时间戳 (vin,daq_time)。
=# CREATE INDEX idx_mars2 ON vehicle_basic_data_mars2
USING mars2_btree(vin, daq_time);
注意!
当设备相同时间点数据分批上报时,MARS2 可以对相同时间(此表中为daq_time值)相同设备(此表中为vin值)的数据进行合并。合并特性需要在创建索引时手动指定uniquemode=true,因为此选项的默认值是false。例如,当你指定uniquemode=true,设备A01在2022-01-01 00:00:00这个时间传回来3条数据,最后会根据最后一条数据将原来的两条数据覆盖,只保留一条数据;但如果你默认了uniquemode=false,那么设备A01在2022-01-01 00:00:00这个时间传回来的3条数据,最后会全部保留,不做任何处理。
datainspect 是 MARS2 自带的存储诊断工具,它可以提供底层数据洞察,以精确地优化你的数据的存储和查询性能。
存储优化需要关注数据在物理文件中的实际内容,与 PostgreSQL 的 Pageinspect 类似,你可以使用 datainspect 来方便的提取 MARS2 物理存储中的数据段来做进一步分析。此外,datainspect 整合了 MARS2 中相关的索引和元信息,以提供 NULL 分布和 minmax 等基本信息,从而辅助 I/O 扫描过程的优化。
注意!
此工具只适用于 MARS2 表。
datainspect 是 MARS2 中内置的系统函数,在正确安装 MARS2 后即可使用。MARS2 表依赖 matrixts 时序扩展,在建表前,首先需要你在使用该存储引擎的数据库中创建扩展。
注意!
matrixts扩展为数据库级别,一个数据库里面创建一次即可,无需重复创建。
=# CREATE EXTENSION matrixts;首先,创建一张测试表,示例中命名为 tb1,我们将以此测试表为用例介绍三个相关函数。
=# CREATE TABLE tb1(
f1 int8 encoding(minmax),
f2 int8 encoding(minmax),
f3 float8 encoding(minmax),
f4 text
) USING MARS2;创建 MARS2 索引。
=# CREATE INDEX ON tb1 USING mars2_btree(f1);构造 24000 条测试数据。
=# INSERT INTO tb1 SELECT
generate_series(1, 24000),
mod((random()*1000000*(generate_series(1, 1200)))::int8, (random()::int8/100 + 100)),
(random() * generate_series(1, 24000))::float8,
(random() * generate_series(1, 24000))::text;desc_ranges 函数整合了 MARS2 底层元信息及索引,以提供如 minmax 索引信息和空值信息等,还支持对数据底层存储空间占用情况进行精确监测。
语法
SELECT <* / column1,column2,...> FROM matrixts_internal.desc_ranges(<tablename TEXT>)参数
tablename:表名,分区表时为分区表名。(必选)
返回
| 字段 | 说明 |
|---|---|
| segno | Segment 编号,从 0 开始 |
| attno | Attribute Number,列编号,从 0 开始 |
| forkno | 物理文件分片的编号。是数据库底层的编号,可以认为它对应一个具体的文件,默认从第一个 fork 开始 |
| offno | RANGE 在物理文件中的偏移量,单位字节。默认从 0 开始。在 MARS2 中数据按批存储入库,以设置好的 compress_threshold(压缩阈值参数)为单位形成一个存储 RANGE,以在物理文件中的偏移量形成自身的位置标识 |
| nbytes | RANGE 在物理文件中占用的实际空间,单位字节 |
| nrows | 建表时设置的 compress_threshold,默认 1200。compress_threshold 即压缩阈值。用于控制单表多少元组(Tuple)进行一次压缩,是同一个单元中压缩的 Tuple 数上限 |
| nrowsnotnull | RANGE 内非空条数 |
| mmin | 该列如果支持 minmax 索引,就是显示该 RANGE 内的最小值,如果不存在为 NULL |
| mmax | 该列如果支持 minmax 索引,就是现实该 RANGE 内的最大值,如果不存在为 NULL |
=# SELECT attno, sum(nbytes)/1024 as "Size in KB"
FROM matrixts_internal.desc_ranges('tb1') GROUP BY attno ORDER BY attno;
attno | Size in KB
-------+----------------------
0 | 94.9062500000000000
1 | 7.8203125000000000
2 | 187.3437500000000000
3 | 386.3515625000000000
(4 rows)=# SELECT * FROM matrixts_internal.desc_ranges('tb1') WHERE segno = 1;
segno | attno | forkname | forkno | offno | nbytes | nrows | nrowsnotnull | mmin | mmax
-------+-------+----------+--------+--------+--------+-------+--------------+--------------------+--------------------
1 | 0 | data1 | 304 | 0 | 4848 | 1200 | 1200 | 15 | 7240
1 | 1 | data1 | 304 | 16376 | 856 | 1200 | 199 | 0 | 99
1 | 2 | data1 | 304 | 17712 | 9072 | 1200 | 1200 | 1.4602231817218758 | 704.8010557110921
1 | 3 | data1 | 304 | 50024 | 20272 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 4848 | 4856 | 1200 | 1200 | 7243 | 14103
1 | 1 | data1 | 304 | 17232 | 160 | 1200 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 26784 | 9760 | 1200 | 1200 | 705.0931003474365 | 1372.9018354549075
1 | 3 | data1 | 304 | 70296 | 19680 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 9704 | 4856 | 1200 | 1200 | 14125 | 21417
1 | 1 | data1 | 304 | 17392 | 160 | 1200 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 36544 | 9760 | 1200 | 1200 | 1375.043496121433 | 2084.906658862494
1 | 3 | data1 | 304 | 89976 | 19792 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 14560 | 1816 | 445 | 445 | 21429 | 23997
1 | 1 | data1 | 304 | 17552 | 160 | 445 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 46304 | 3720 | 445 | 445 | 2086.0748374078717 | 2336.065046118657
1 | 3 | data1 | 304 | 109768 | 7576 | 445 | 445 | NULL | NULL
(16 rows)show_range 函数选取一段 MARS2 中的物理数据,将这段数据展示成可读的数据的方法,当前支持的数据类型有:int2,int4,int8,float4,float8,timestamp,date,text。
语法
SELECT <* / column1,column2,...> FROM matrixts_internal.show_range(
tablename text,
attno int4,
forkno int4,
offno int4,
nbytes int4
)参数
0 开始编号。(必选)注意!
以上参数详见上文desc_ranges函数的返回介绍。
| 字段 | 说明 |
|---|---|
| rowno | 行编号。此编号由此 RANGE 中的相对偏移量决定,而非整张表的绝对偏移量 |
| val | 实际内容 |
注意!
浮点型数据展示的val可能会有误差。
=# SELECT * FROM matrixts_internal.show_range('tb1', 1, 304, 16176, 808) LIMIT 20;
rowno | val
-------+-----
1 | 4
2 | 36
3 | 81
4 | 58
5 | 17
6 | 75
7 | 11
8 | 84
9 | 60
10 | 78
11 | 69
12 | 0
13 | 87
14 | 40
15 | 72
16 | 58
17 | 17
18 | 48
19 | 70
20 | 6
(20 rows)dump_range 函数将 MARS2 中选定的物理数据经过解压后导出为一个二进制文件,用以二次分析。
语法
=# SELECT <* / column1,column2,...> FROM matrixts_internal.dump_ranges(
tablename text,
attno int4,
outfile text,
forkno int4,
offno int4,
limits int4
);参数
tb1-f2.bin,导出后在 Segment1 上显示为 tb1-f2.bin-seg1。(必选)forkno 和 offno 指定的位置为起始位置来确定限制的 RANGE 个数。(可选)注意!
此处limits只限制单个 Segment 上的导出的 RANGE 数。
注意!
以上参数详见上文desc_ranges函数的返回介绍。
返回
示例
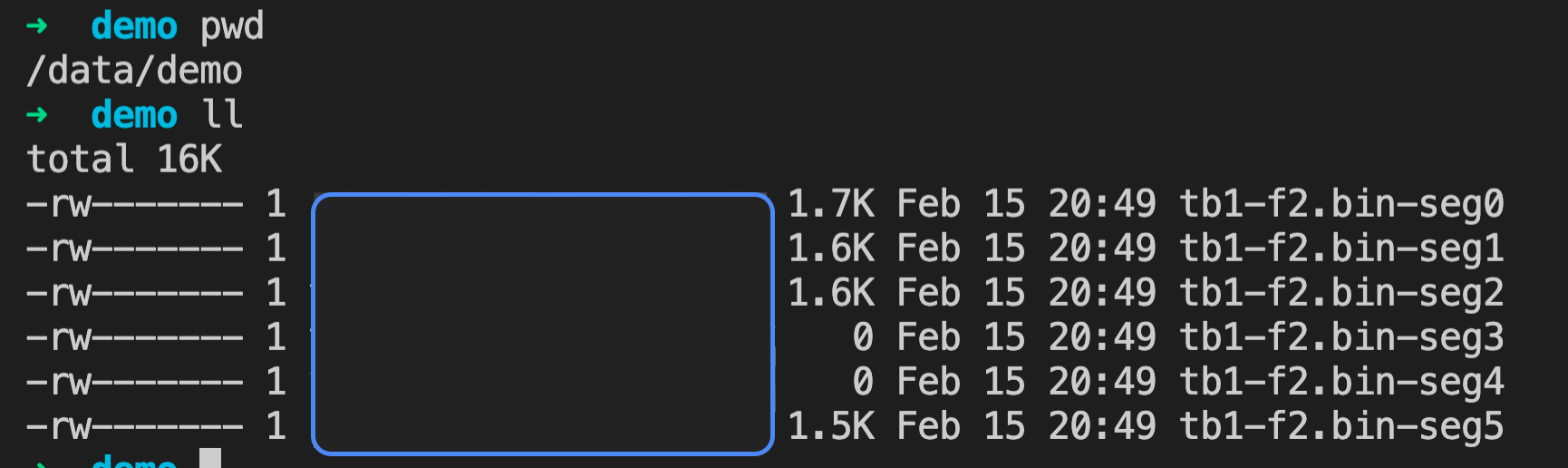
=# SELECT * FROM matrixts_internal.dump_ranges('tb1', 1, '/data/demo/tb1-f2.bin', 304, 16176, 1) LIMIT 20;
nbytes
--------
0
0
1480
1632
1704
1592
(6 rows)例子中执行 dump_ranges 之后发现返回了 6 条结果,这是因为导出是 Segment 独立执行的,这里面每一条都代表下游一个 Segment 上的导出结果,随后在相应的目录会出现;其中有 2 条结果的 nbytes 为 0,是因为 Segment 上没有满足过滤条件的数据。
执行完成后每个 Segment 所在主机都会生成在原有后缀后又添加独立后缀标识 .-seg<no> 的二进制文件。