

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
集群部署
SQL参考
工具指南
 overview版块显示了集群的整体运行状态,包括:
overview版块显示了集群的整体运行状态,包括:
| 参数名 | 描述 | 参考报警阈值 |
|---|---|---|
| 集群状态 | 集群节点状态,包括: 0:正常 1:无Standby 2:无Mirror 10:分布不均衡(部分节点宕机恢复后,没有重新平衡主从角色) 11:存在主从不同步节点(部分mirror节点与primary不同步) 12:只有Master(集群只启动了Master节点,通常在诊断时使用) 20:Segment宕机(存在不可用的Segment节点,集群不可用) |
Segment宕机为严重事件,需要报警 |
| 运行时间 | 包括MatrixDB自启动以来的运行时间和master宿主机操作系统运行时间 | |
| 版本 | MatrixDB的版本 | |
| 连接状态 | 连接状态显示了数据库系统中的连接数统计,包括:连接总数、连接查询被阻塞数、空闲连接数、事务中空闲数 | |
| 慢查询 | 当前系统中,执行时间超过1天的查询数量 | 大于0则说明有特别慢的查询,需要报警 |
| 事务 | 事务提交与回滚数量统计 | 可以设置回滚报警阈值 |
| 磁盘使用量 | master节点和segment节点的磁盘使用量与剩余空间 | 报警建议直接在node_exporter里设置 |
| 节点状态 | 每个节点的状态,包括: 0:UP(正常) 10:Switched(角色互换,说明出现过主从切换,需要重新平衡) 11:Resync(主从同步中) 20:Down(宕机) |
11、20两个值需要增加报警 |
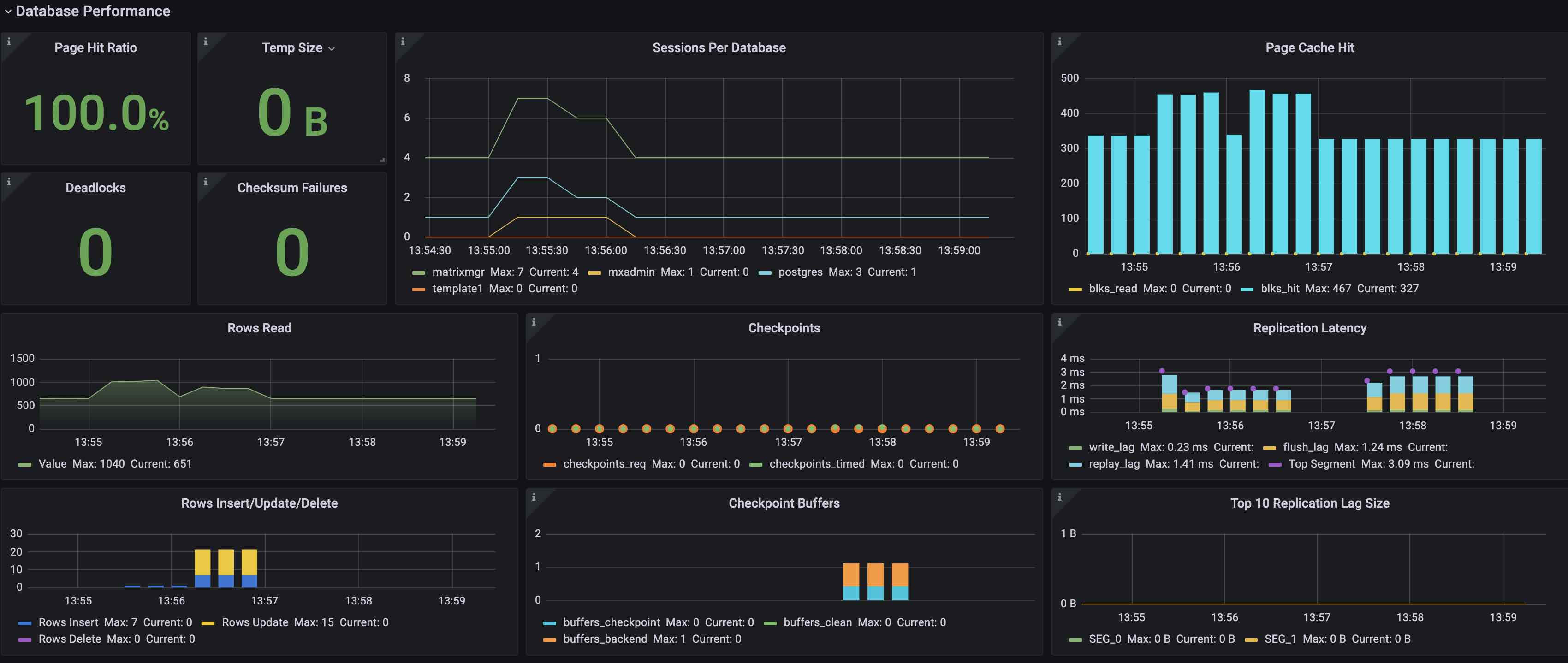 Database Performance版块展示了数据库性能,包括:
Database Performance版块展示了数据库性能,包括:
| 参数名 | 描述 | 参考报警阈值 |
|---|---|---|
| Page Hit Ratio | 读取数据页时命中缓冲区比率 | |
| Temp Size | 临时文件用量 | |
| Deadlocks | 发生死锁次数 | 大于0可报警 |
| Checksum Failures | 数据页校验失败的次数 | 大于0可报警 |
| Sessions Per Database | 每个数据库的连接数 | |
| Page Cache Hit | blks_hit:读取数据页时命中缓存次数 blks_read:未命中缓存而要读磁盘的次数 |
|
| Rows Read | 查询读取和返回tuple数 | |
| Checkpoints | checkpoints触发次数,包括: checkpoints_req:手动触发 checkpoints_timed:周期触发 |
|
| Replication Latency | 主从复制延迟,单位ms write_lag:日志写到mirror文件缓存中的延迟 flush_lag:日志刷新到mirror磁盘的延迟 replay_lag:日志在mirror回放完毕的延迟 Top Segment:所有节点write_lag+flush_lag+replay_lag延迟和最大值 |
可以根据情况设置报警阈值 |
| Rows Insert/Update/Delete | 行操作统计 Rows Insert:插入行数 Rows Update:更新行数 Rows Delete:删除行数 |
|
| Checkpoint buffers | 写脏页统计 buffers_checkpoint:checkpoint写脏页数量 buffers_clean:bgwriter写脏页数量 buffers_backend:backend进程写脏页数量 |
|
| Top 10 Replication Lag Size | Top10节点延迟量统计,计算方法为发送的lsn与回放lsn差值 | 可以根据情况设置报警阈值 |
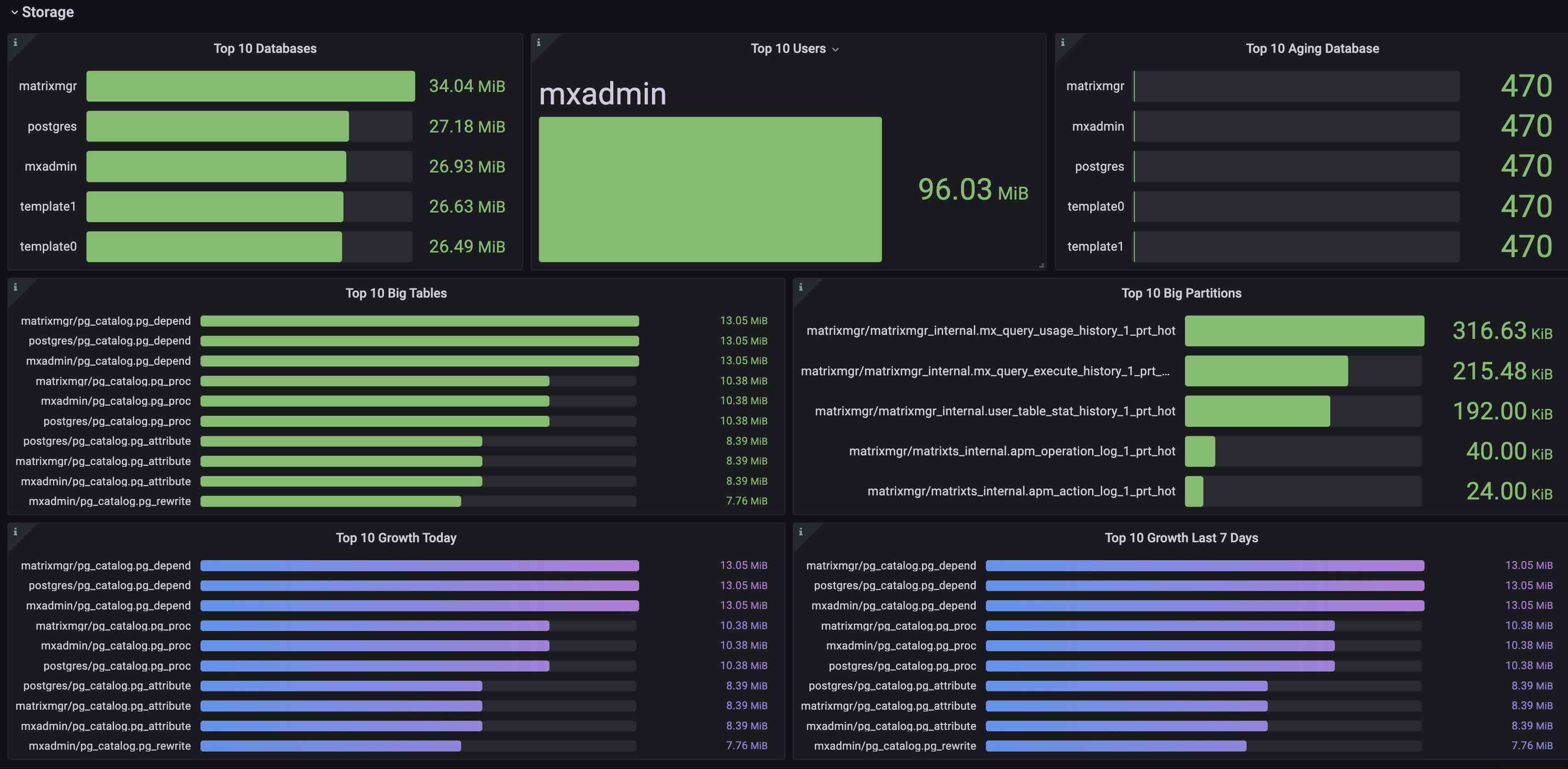 storage版块展示了存储相关的统计,包括:
storage版块展示了存储相关的统计,包括:
| 参数名 | 描述 | 参考报警阈值 |
|---|---|---|
| Top 10 Databases | Top10数据库大小 | |
| Top 10 Users | Top10用户产生数据大小 | |
| Top 10 Aging Database | Top10 数据库年龄(小于该值的事务ID被替换为Frozen) | |
| Top 10 Big Tables | Top10数据库表大小 | |
| Top 10 Big Partitions | Top10分区表大小 | |
| Top 10 Growth Today | 当天Top10表大小增量 | |
| Top 10 Growth Last 7 Days | 过去7天Top10表大小增量 |



