本节使用一个真实场景,来告诉大家如何在 YMatrix 中创建时序表:设备表与指标表。
本课程教学视频请参考 YMatrix 数据建模与时空分布模型
场景中要采集风机的转速、温度和湿度。风机设备包含名称、编号、区域、坐标等属性。
| 字段 | 类型 | 描述 |
|---|---|---|
| device_id | int | device_id 为风机的唯一id,用自增主键(SERIAL 类型) |
| name | text | 风机名称 |
| serial_number | text | 风机序列号 |
| region | text | 风机所属区域 |
| longitude | float4 | 风机经度 |
| latitude | float4 | 风机纬度 |
| 字段 | 类型 | 描述 |
|---|---|---|
| device_id | int | 风机 id |
| time | timestamp | 时序数据的时间戳 |
| speed | float4 | 风机转速 |
| temperature | float4 | 风机温度 |
| humidity | float4 | 风机湿度 |
和其他数据库一样,在 YMatrix 中,数据表是按库组织起来的,所以先创建数据库 stats。
可以连接默认数据库 postgres,然后使用 CREATE DATABASE 创建:
[mxadmin@mdw ~]$ psql postgres
psql (12)
Type "help" for help.
postgres=# CREATE DATABASE stats;
CREATE DATABASE也可以直接使用 YMatrix 的命令行工具 createdb 创建:
[mxadmin@mdw ~]$ createdb stats创建好数据库后,要连接进去才能使用。在 YMatrix 中每个连接只能隶属于一个固定的库。
可以在执行 psql 命令尾随数据库参数连接:
[mxadmin@mdw ~]$ psql stats
psql (12)
Type "help" for help.
stats=#也可以从其他数据库连接中,使用 \c 元命令,切换连接到新的数据库中:
postgres=# \c stats
You are now connected to database "stats" as user "mxadmin".连接数据库后,开始创建数据表:
创建设备表:
postgres=# CREATE TABLE device(
device_id serial,
name text,
serial_number text,
region text,
longitude float4,
latitude float4
)
DISTRIBUTED REPLICATED;创建指标表:
由于指标表中将实时写入并存储大量时序数据,我们推荐你基于列存引擎 MARS2 创建它,并视情况使用编码链压缩算法优化数据的存储与查询性能。 MARS2 表依赖 matrixts 扩展,在建表前,首先需要你在使用该存储引擎的数据库中创建扩展。
CREATE EXTENSION matrixts;注意!
matrixts扩展为数据库级别,一个数据库里面创建一次即可,无需重复创建。
postgres=# CREATE TABLE metrics(
time timestamp with time zone encoding (minmax),
device_id int encoding (minmax),
speed float4 encoding (minmax),
temperature float4 encoding (minmax),
humidity float4 encoding (minmax)
)
USING MARS2
WITH (compresstype=zstd, compresslevel=1)
DISTRIBUTED BY (device_id);从上面的建表语句会发现,两个表的分布方式不同,详细介绍见下文“ 4.2 数据分布策略”。
device 表使用得是 DISTRIBUTED REPLICATEDmetrics 表使用得是 DISTRIBUTED BY (device_id)在此示例中,为便于应用端维护设备信息,标识设备数据需具有唯一属性,所以建立如下唯一索引:
postgres=# CREATE INDEX ON metrics
USING mars2_btree(device_id) WITH (uniquemode=true);注意!
MARS2 表在建表后需要创建 mars2_btree 索引才能进行数据读写,如果要求索引键上读出的数据是唯一的,可在 CREATE INDEX 语句上加上参数 WITH (uniquemode=true);这和常规上的 UNIQUE 约束不同,其不会在写入时检查唯一约束,而是在读的时候对索引键相同的数据进行合并。
创建完表之后,下面介绍一下简单的数据写入与查询操作。
应用方在进行指标数据接入的时候,需要按如下步骤进行:
那么设备标识如何转换成 ID 呢? 设备 ID 并不是设备自身的一个属性,不会随指标数据发送过来,需要应用方进行转换。
最简单的做法就是每次根据设备编号查库,如果存在则直接读取;不存在则插入新设备并生成 ID。
这种方法需要每个指标在插入前都要查库,大大增加数据库负载,影响吞吐量。所以推荐做法是,物联网网关或者 Kafka 消费程序维护一个内存哈希表。每条数据在到来的时候从内存哈希表查询设备 ID,存在则直接使用;不存在则插库获取设备 ID 并更新哈希表。
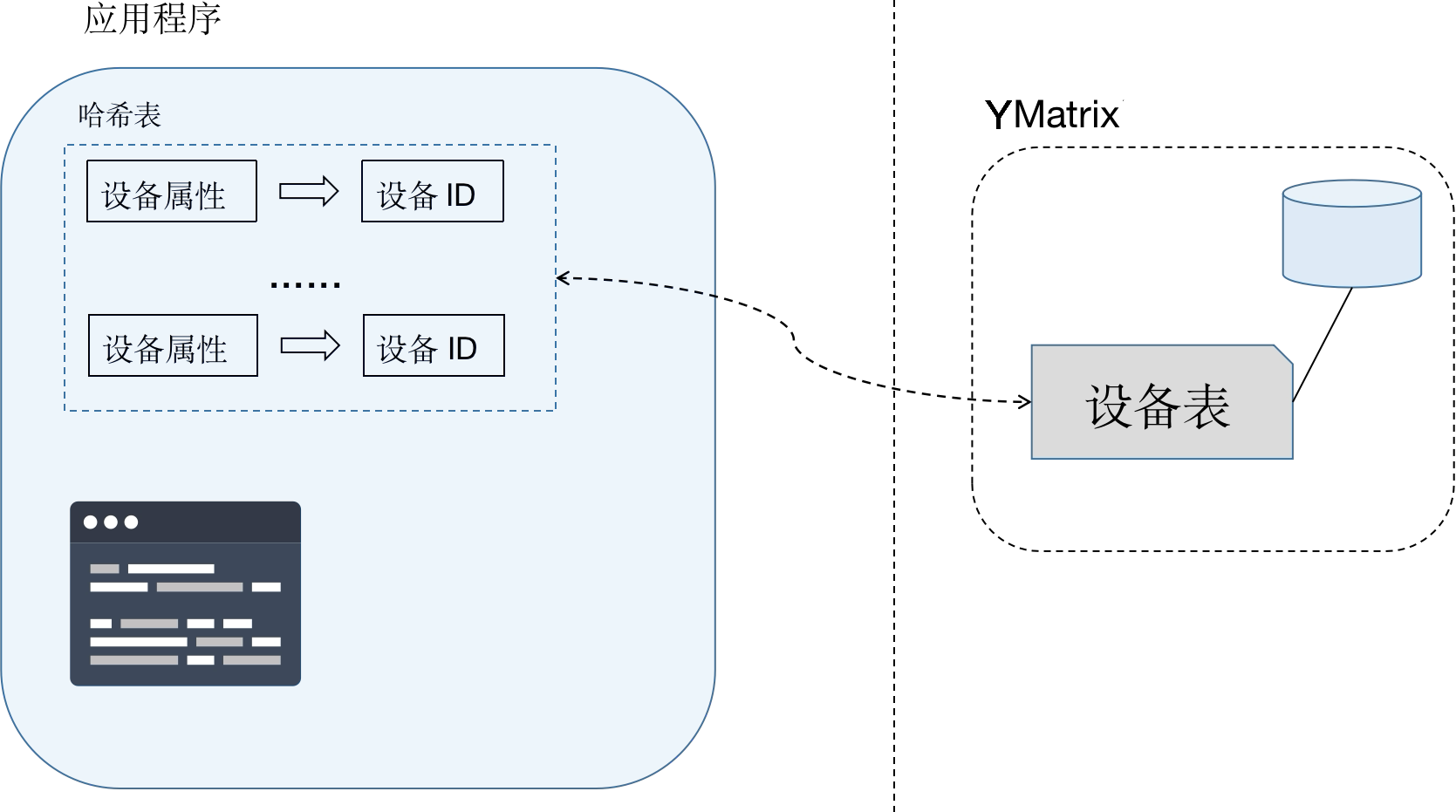
既然设备信息和指标数据分开到两个表存储。在做查询的时候,如果既要获得指标统计信息又要获得设备信息,要基于设备 ID 做连接。
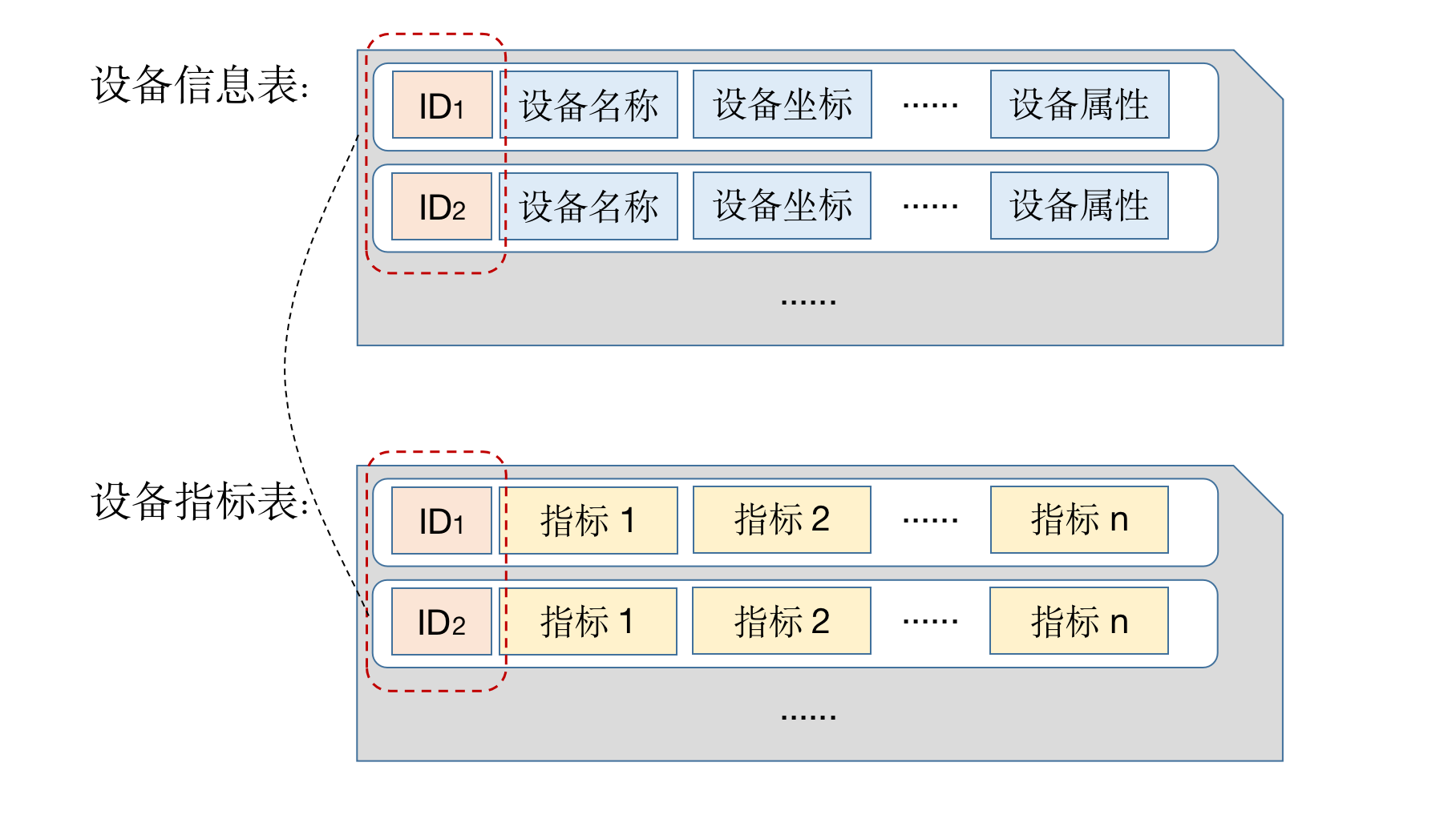
如下 SQL 统计了 '2021-07-01' 日每个风机的平均温度、平均湿度和最大转速:
postgres=# SELECT device.name,
AVG(metrics.temperature),
AVG(metrics.humidity),
MAX(metrics.speed)
FROM device JOIN metrics USING (device_id)
WHERE metrics.time >= '2021-07-01'
AND metrics.time < '2021-07-02'
GROUP BY device.device_id, device.name;YMatrix 是一款中心化架构的分布式数据库,包含 Master 和 Segment 两种类型节点。
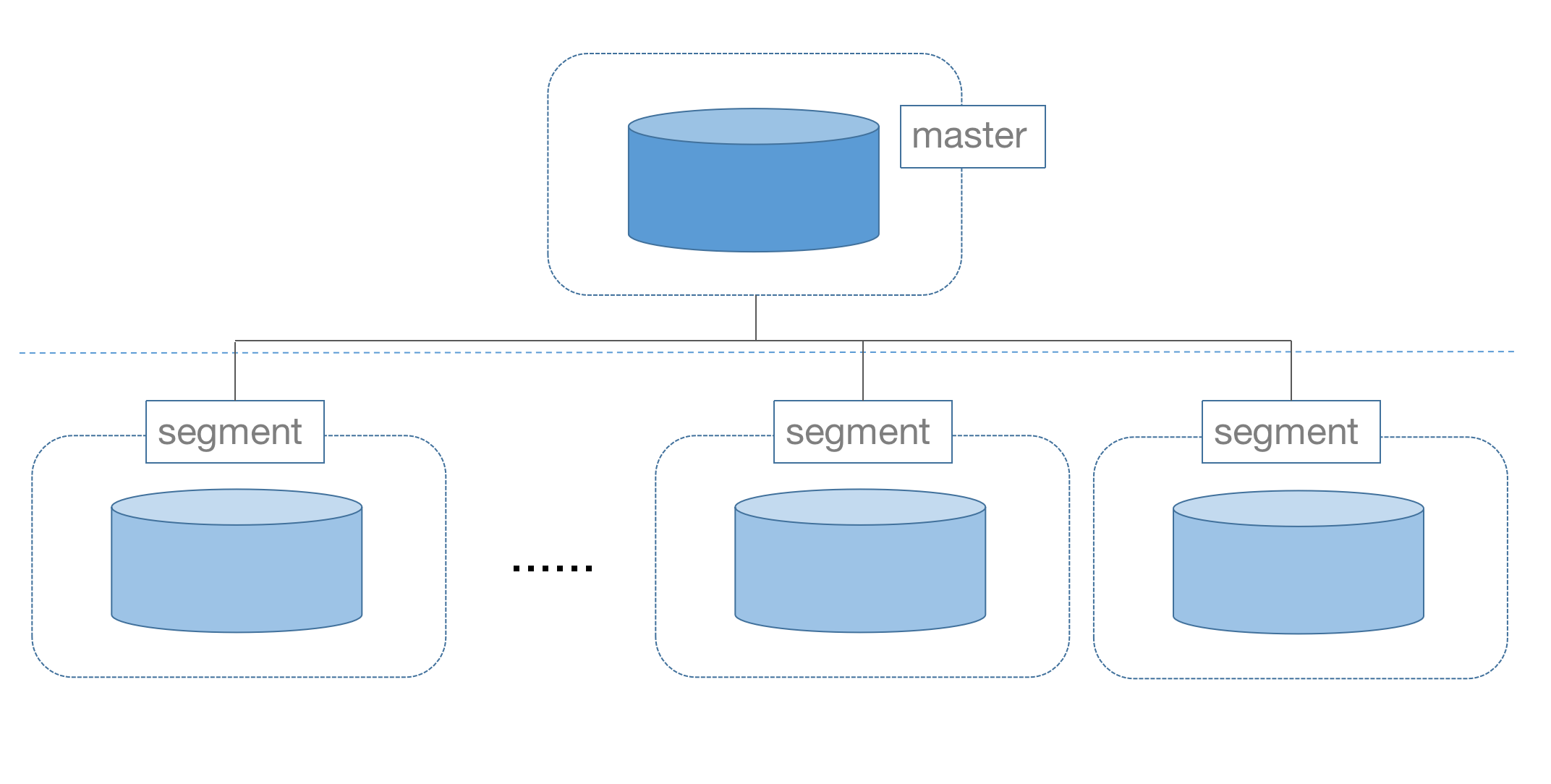 Master 是中心控制节点,用来接收用户请求并生成查询计划。Master 节点并不存储数据,数据存储在 Segment 节点上。
Master 是中心控制节点,用来接收用户请求并生成查询计划。Master 节点并不存储数据,数据存储在 Segment 节点上。
Master 节点只有一个,Segment 节点至少有一个,可以更多,几十个甚至上百个。Segment 节点越多,集群可以存储越多数据,计算能力也越强。
YMatrix 数据表在 Segment 上有两种分布策略,分片和冗余;分片又分为哈希和随机两种分片方式:
分片分布即将数据水平切分,一份数据只存储在其中一个节点上。哈希分片需要定义哈希键,可以是一个或多个,数据库对哈希键计算键值来决定存储在哪个节点上。随机分片则将数据随机分配到一个节点上。
冗余分布则将数据冗余存储在每个数据节点上,即每个数据节点都包含表中的所有数据。这种方式会占用大量存储空间,所以只有经常需要做连接操作的小表才使用冗余分布。
综上,数据分布总共 3 种策略,不同的分布策略,在创建表的时候可以通过 DISTRIBUTED BY 关键字来设置:
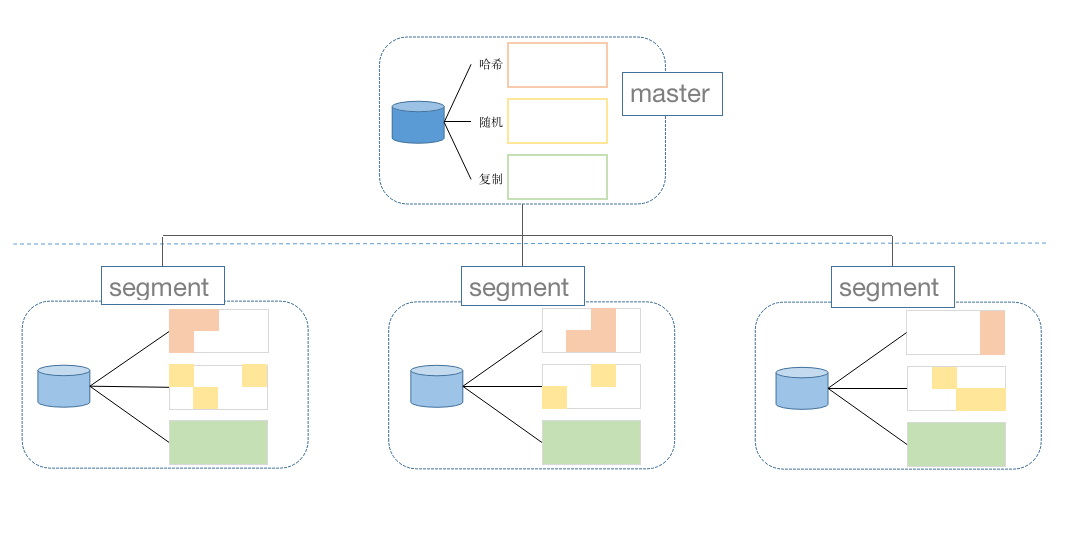
分布式架构下的 YMatrix,大部分数据表都采用分片存储,但是可以支持全部关系查询。从用户角度来看,就是一个空间无穷大的 PostgreSQL。
那么,对于跨节点的数据连接如何做呢?这得益于 YMatrix 的 Motion 操作,当满足连接条件的数据不在同一个节点上时,会将它们移动到相同节点上做连接。
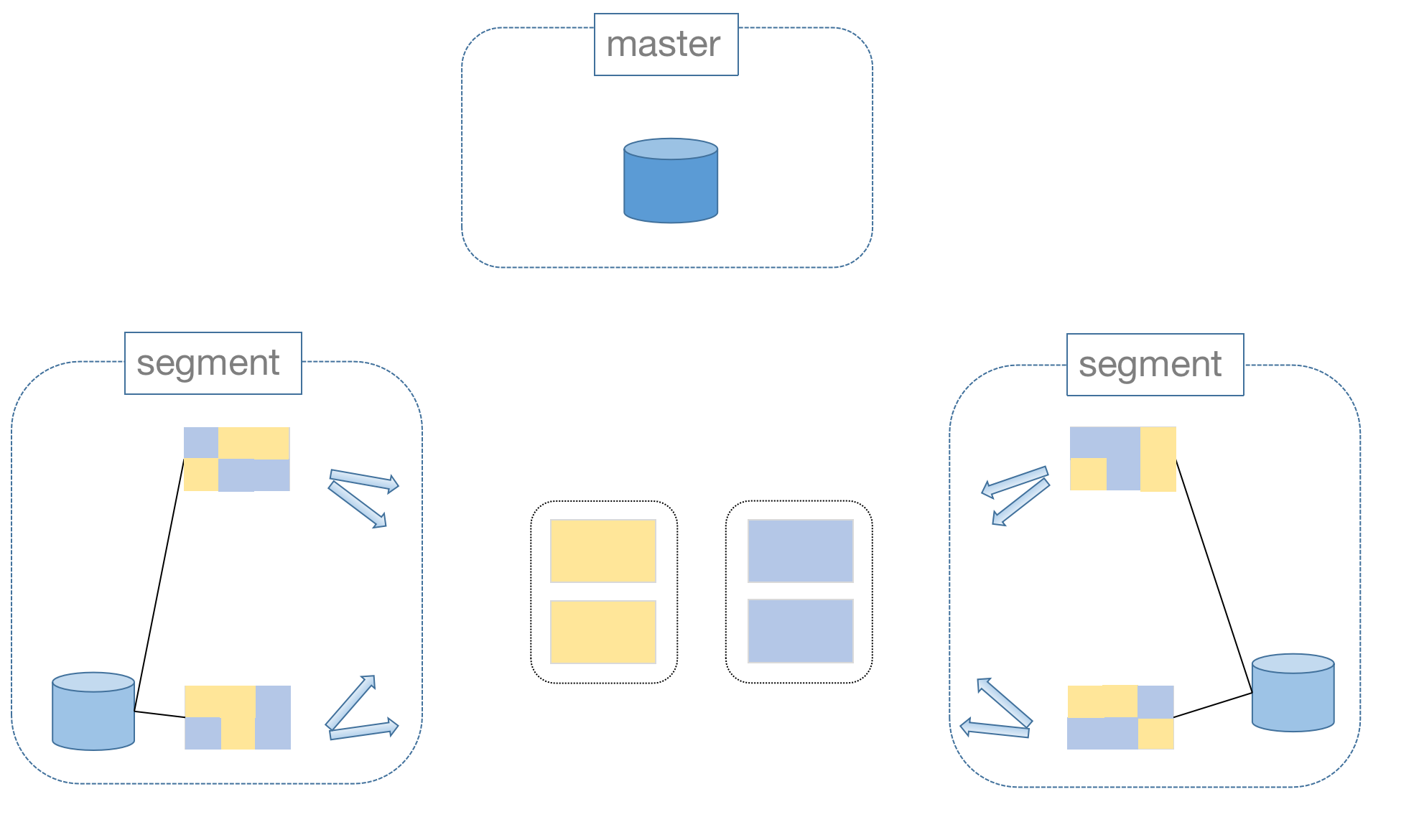
当然,做移动操作是有成本的。所以,在设计表的时候,要充分考虑数据分布特征与后期要进行的查询类型来综合决定分布策略。
只有满足连接条件的数据完全分布在相同的节点上才可以避免移动操作。所以经常要做连接操作的大表,最好将连接键设置为分布键。
了解了 YMatrix 数据分布方式与利弊,下面讨论一下时序数据表应该采用哪种分布策略。
首先考虑一下指标表,指标数据量非常大,不可能采用冗余分布方式,而随机分布又没有任何规律,不利于后面的统计分析,所以哈希分布是首选。那又该如何确定分布键呢?
时序表数据包含 3 个维度:
后面的统计分析基本都是以设备并连接设备表的其他属性作为分组键,所以使用设备 ID 作为分布键。
设备表数据规模相对固定,不会像指标数据那样无限增长,所以一般采用冗余分布方式。这样,在和指标表做连接操作时无需做跨节点的数据移动。





