

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
系统配置参数
索引
扩展
SQL 参考
常见问题(FAQ)
本文档介绍了 YMatrix 架构的以下内容:
全局架构
局部架构
YMatrix 为降低数据生态的复杂性,设计了具有超融合基因的简洁架构,将计算、存储和网络资源整合在一个统一系统中。其基于大规模并行处理(MPP)系统构建,符合微内核架构特点。
此架构可灵活、融合适应多个场景,不仅对于物联网时序场景友好,也支持传统分析型数据仓库环境及商业智能(BI)工作。
使用超融合架构替换传统数据技术栈看似是一项艰巨的任务。那么,为什么我们一定要这样做?
实际上,无论在哪种情况下,全面使用超融合架构对于许多企业都能带来助益,为企业庞杂的 IT 系统提供统一的数据基座,包括智能网联汽车、工业互联网、智能制造、智慧城市、能源、金融、制药等。
相比于如 Hadoop 生态等复杂数据技术栈,YMatrix 架构有以下优势:
超融合
高可用
丰富的工具链生态
支持标准 SQL
完整支持 ACID 事务
与其他架构的数据库相比,YMatrix 的超融合体现在融合了多种数据类型与数据操作,从而在一个数据库内实现多种数据类型 + 多场景的高性能支持;就 YMatrix 内部架构而言,其具有微内核特征。在公共基础组件之上,为不同业务场景需求提供不同的存储、执行引擎组合,实现不同的微内核,以得到针对性的写入、存储、查询性能提升。
下图描述了 YMatrix 内部的超融合架构组成及其功用:
_1696644131.png)
以下部分详细介绍了 YMatrix 超融合架构的组成。
YMatrix 的高层数据库架构在经典的 MPP(大规模并行处理)数据库技术架构基础上有所发展。
下图描述了组成一个 YMatrix 数据库系统的核心组件以及它们如何一起工作:
_1693302582.png)
以下部分详细介绍了 YMatrix 数据库系统中的各个组件及其功能。
YMatrix 使用自研的 ALOHA(Advanced least Operation High Availability) 技术来保障集群的高可用性。当集群出现实例单点故障时,其对应的备用实例将发生角色切换,代替故障实例提供服务,从而保障了集群服务不中断。
| 故障节点实例 | 影响 | 时间 |
| Mirror | 当 Mirror 故障,不会影响用户对于相应 Primary 中数据的查询,但需手动恢复故障的 Mirror | 网络通畅的情况下可达秒级别 |
| Standby | 当 Standby 故障,不会影响用户集群数据的查询,但需手动恢复故障的 Standby | |
| Primary | 当 Primary 故障,用户无法查询相应数据,需要等待系统自动提升对应的 Mirror 为 Primary 后再进行查询 | |
| Master | 当 Master 故障,集群不可用,用户无法查询相应数据,需要等待系统自动提升对应的 Standby 为 Master 后再进行查询 |
注意!
故障恢复详细操作步骤详见故障恢复。
ALOHA 服务采用了基于 ETCD 集群的高可用架构。该架构可以解决故障自动转移(Failover)的问题,本质上来说即是实现自动选举主节点(Master)机制,并保持数据强一致性。
该机制包括以下环节:
状态数据采集
数据集群上报给 ETCD 的数据有两个来源:
状态数据存储
状态数据存储在 ETCD 集群中。ETCD 是基于 Raft 协议实现的,成熟的分布式存储解决方案。其作为状态存储层,能够在集群出现故障的情况下,为进程的管理控制提供可靠、唯一的集群状态信息。
注意!
ETCD 集群在存储状态时会有较多的磁盘操作,因此理想状况下,应有单独的几个物理机用于部署 ETCD 集群,这样可以充分保证 ETCD 的性能。但实际应用中,物理机的数量可能是不足以支撑 ETCD 独立部署的,因此奇数个 ETCD 实例会随机部署于数据集群的部分或全部物理机上,用以保存节点、实例的状态数据。
原理图如下:
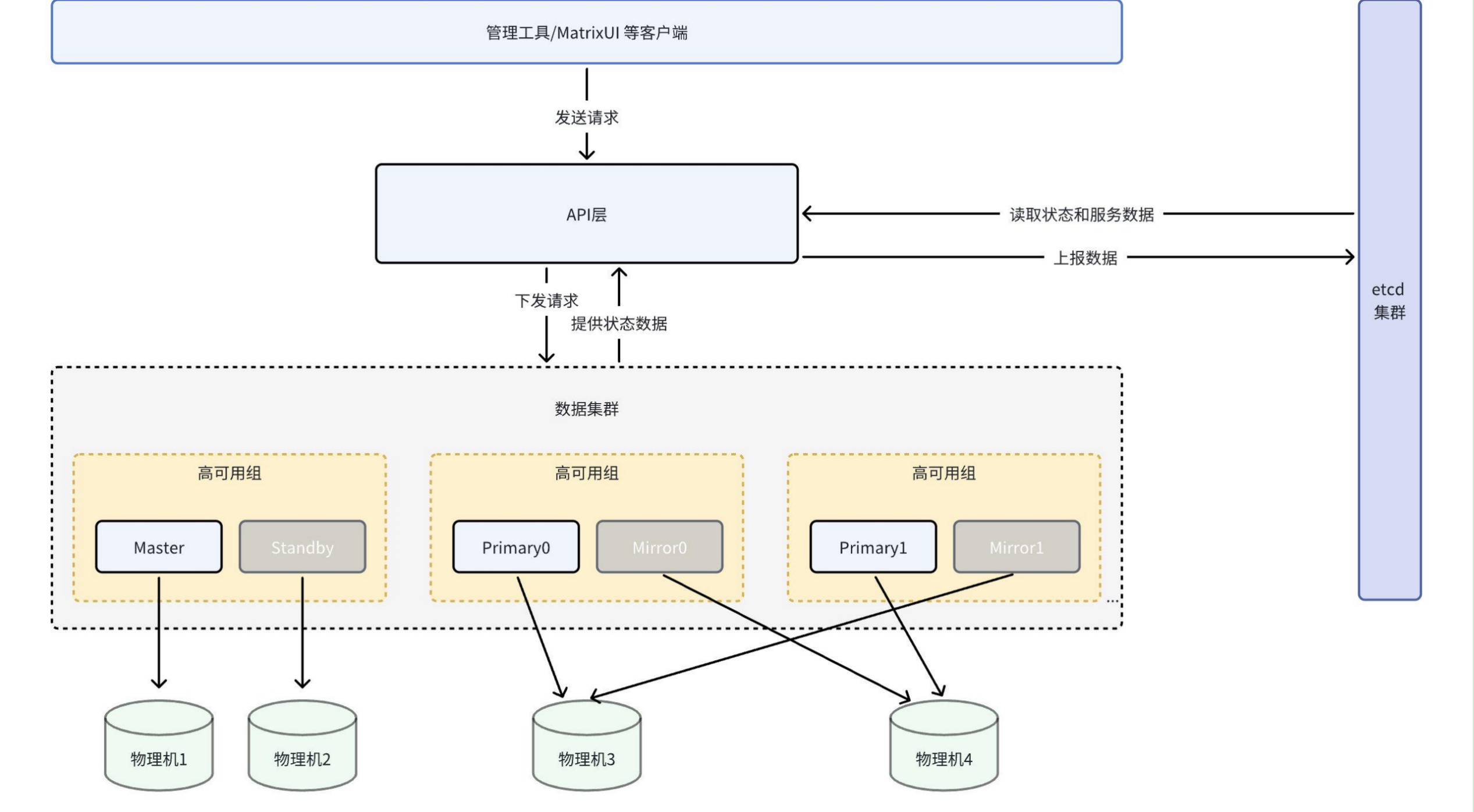
可以看到:
ETCD 是一个分布式的键值存储集群,用于在分布式系统中存储和检索数据。ETCD 使用 Raft 一致性算法来确保数据的一致性和可靠性。它被设计为高度可用的,具有强大的故障恢复能力。ETCD 提供了简单的 RESTful API 接口,使得应用程序可以方便地访问和操作存储在其上的键值对。
重要概念:



