

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
系统配置参数
索引
扩展
SQL 参考
常见问题(FAQ)
本文档介绍了时序场景下的数据写入特征,以及 YMatrix 在时序特征下的数据写入架构。
存储是数据库的核心功能之一,完成数据建模和数据库连接后,就要向表写入数据。
时序场景的写入主要有以下特征:
时序场景中数据写入的典型特点即数据规模大,反应到实际场景中包括 3 个方面:
综上,在不断增长的庞大的实体数量,以及高频的采集频率的影响下,时序场景产生的数据量巨大,对数据库的吞吐性能形成了极大挑战。
YMatrix 开发了 MatrixGate 高速写入工具,通过数据节点(Segment)并行接入数据的实现方式,最高可以达到亿级数据点/秒的写入速度。
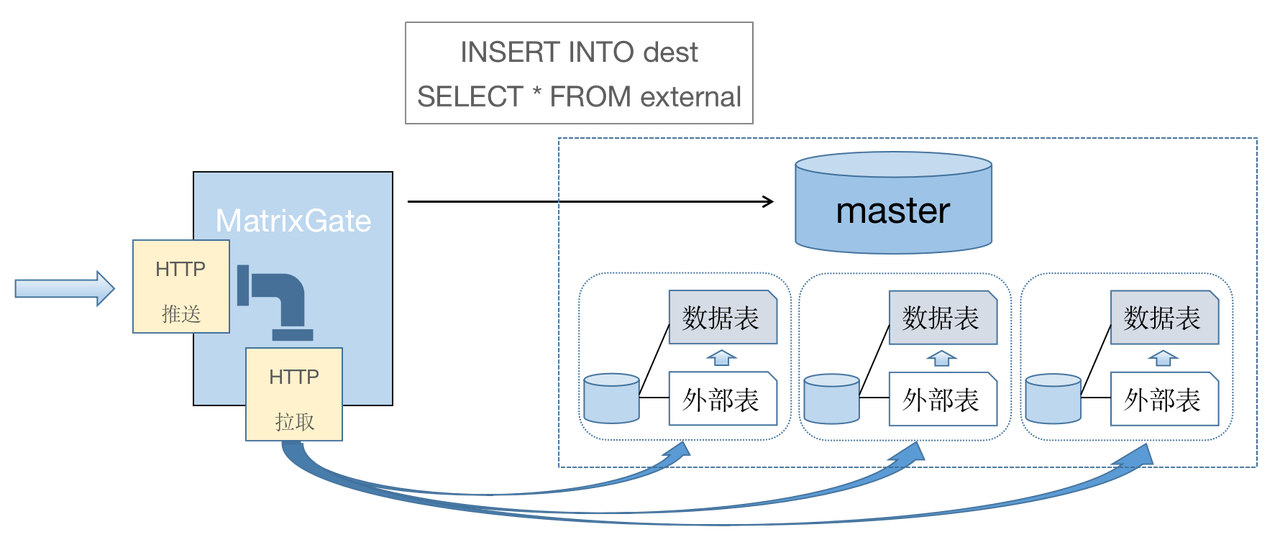
注意!
mxgate 实现方式,请见 YMatrix - YMatrix 如何实现单机 5000万 数据点/秒写入速度;评测报告,请见 YMatrix - 时序数据库插入性能评测:YMatrix 是 InfluxDB 的 78 倍;工作原理请见 数据写入工具;
在实际场景中,数据写入面临的问题不仅仅是数据规模大、来源形式多样化,还包括一些复杂的异常情况,如:
在某些场景中,设备在某个时刻的采集指标不会一次性的全部发送回来,而是分批次回传。多次回传的数据需要合并到一起,而不是分多条记录存放。
对于这种场景,YMatrix 支持通过 UPSERT 功能来应对。此场景的详细介绍与 UPSERT 功能用法见 数据分批合并场景(UPSERT)。
延迟指的是设备故障或者采集链条某个节点出现问题时,数据不能按时上报。在采集链条恢复正常时,再上报数据。譬如汽车进入无信号区后行驶数天,进入有信号区域时会恢复上报链路。这种延迟常常可以按照天来计算,甚至可以按照周来计算。
乱序则意为设备故障或者采集链条某个节点故障时,上报将延迟。故障修复后,有时需要先上报最新的数据,然后逐步补齐缺失的数据。这种情况就会发生乱序上报,即上报的数据可能是比已经上报过的数据还要旧。
因这两种场景常常无需数据库进行特别的数据合并处理,在此不再赘述。
异频是指设备的不同指标分别按照不同的频率来采集,比如,有的是 1s 采集一次,有的是 2s 采集一次。如下图所示:
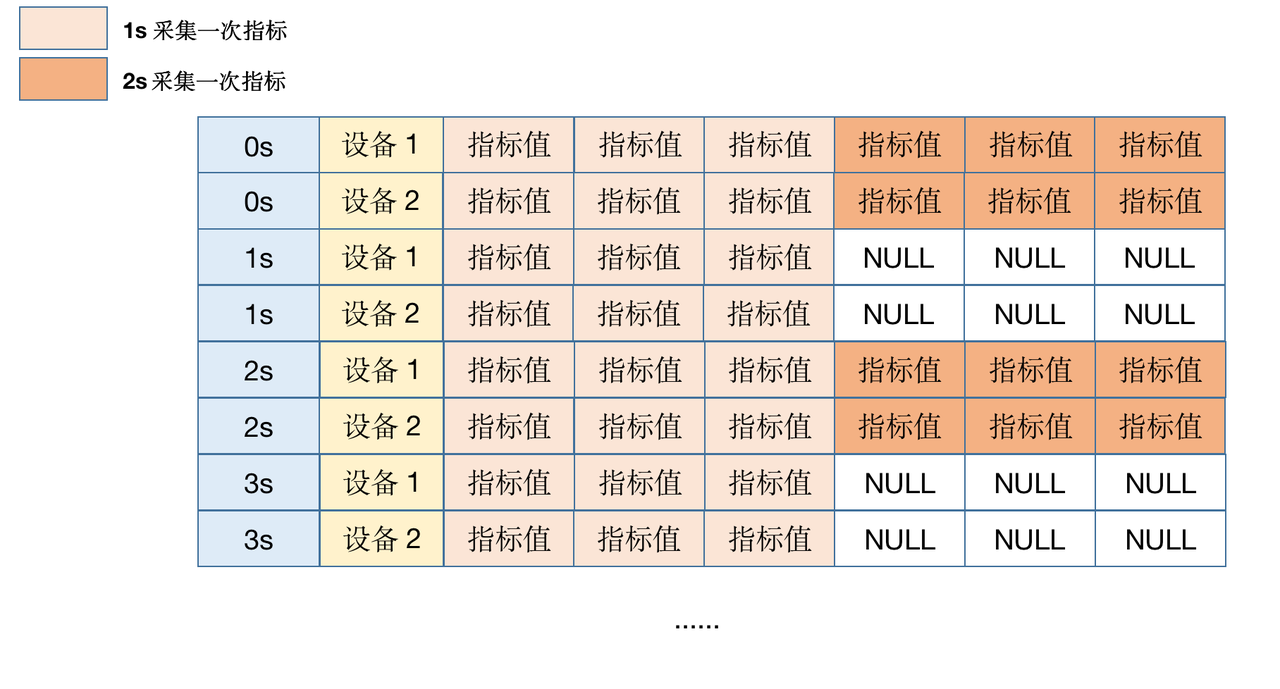
异频上报会导致在存储数据的时候,对于低频采集的指标值中会存在大量 NULL,而 NULL 值同样会占用一定的存储空间:对于 HEAP 表,存储开销为列数/ 8 字节;对于 MARS2 表,存储开销为 RowGroup 行数/ 8 字节。所以要根据 NULL 的情况综合考虑解决方案。
YMatrix 可以将多个来源,不同形式的数据接入到自己的系统中,下图包含了常见的接入数据来源和存储形式。
注意!
直接点击对应的图标即可跳转到相应文档。



