
摘要
Oracle 被广泛应用于制造业生产流程中,承载 MES、ERP 等核心系统。但近几年,随着业务加快扩张,以及企业数字化运营程度的不断加深,数据量翻倍、新数据类型不断涌现、分析报表需求愈发复杂,都让基于 Oracle 的传统数据链路不堪重负。
本文基于 YMatrix 在新能源制造领域的真实案例实践,介绍基于 YMatrix 替换 Oracle 的场景架构方案及迁移过程,以及替换后真实的性能对比结果与业务收益。
作者:YMatrix 架构工程师 徐福贵
新能源产业近几年发展迅速,行业竞争愈发激烈,而产线的生产效率直接决定了企业的核心竞争力。
以我们服务的某新能源电池制造商为例,在其工厂产线中, MES、ERP、PLM、QMS 等诸多业务系统产生的数据,会统一汇总进 Oracle RAC 集群。
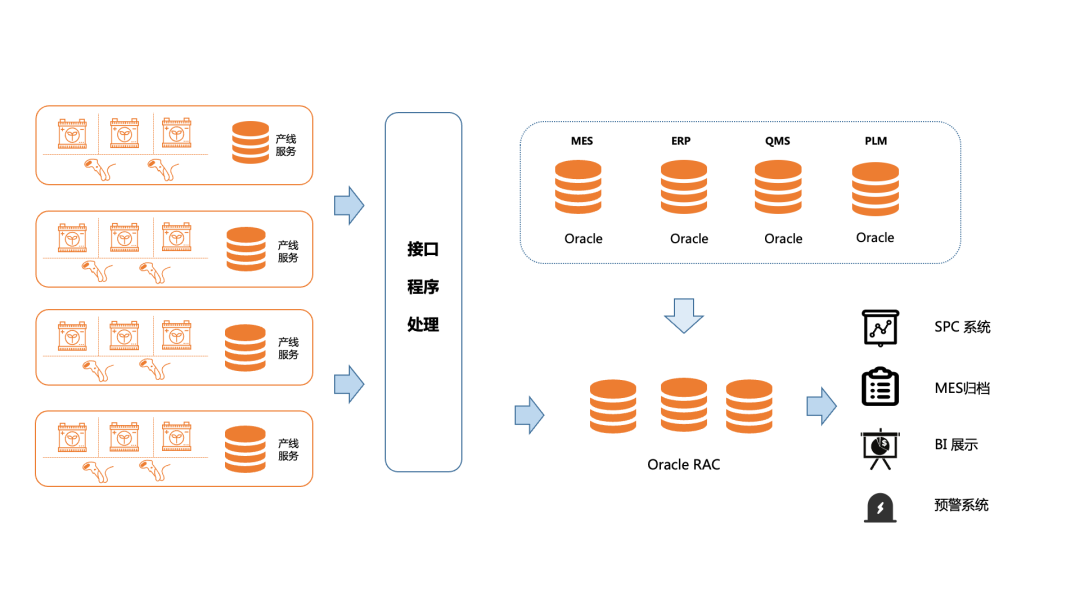
基于 ORACLE 的业务架构
然而,随着业务的快速扩张,新产线不断增加,同时生产设备/装备全面数字化,现有的 Oracle 集群面临着巨大压力:
无论数据的规模、类型和分析应用,都经历了巨大的量变,并引发质变。
在这样的背景下,现有的 Oracle 逐步暴露出诸多功能和性能问题:数据储存不足、数据分析的实效性降低、不支持实时计算、数据接入效率慢、数据孤岛严重、数据质量差等等,严重影响了生产交付和经营决策管理。
数据存储能力不足
现有 Oracle RAC 集群保存了大量历史数据,占用了较大的空间,而随着新产线的增加,设备产生的大量数据无法满足储存要求;
数据写入性能不足
现有平台在使用多个客户端同时写入时,会出现超时、连接中断、无响应等现象,导致大量数据无法入库,数据丢失等现象,严重影响业务决策的正确性;
查询实效性不足
在执行复杂查询时,无法计算出结果,导致重要的运营数据无法及时提供,严重影响业务正常运转;
无法支持大规模实时分析计算
面对新增的生产制造、产品运营、数字看板、数字孪生、实时洞察需求,现有数据库无法支撑实时计算,制约了实时业务的开展;
数据孤岛严重
数据分散在 ERP、PLM、CRM 系统中,在计算时需要搬来搬去,加大了计算数据的开销,同时在搬数据过程中也会导致数据丢失、数据重复等现象,严重影响到关键分析的准确性。
数据质量差
当客户端快速增加,并同时写入大量数据时,现有集群出现了入库速度慢、运行不稳定等现象,因此经常会出现数据的重传、漏传、错传等,导致数据不准确,或保存大量的冗余数据;
无法支持高并发查询
BI 报表、SPC 和预警系统进行高并发查询时,现有的 Oracle RAC 无法支撑。
面对 Oracle RAC 存在的问题,需要使用新的数据库来支撑产线中的数据储存和大量查询计算,以跟上业务飞速发展的节奏。经过反复调研测试,客户决定采用 YMatrix 超融合数据库替换现有 Orcale RAC。
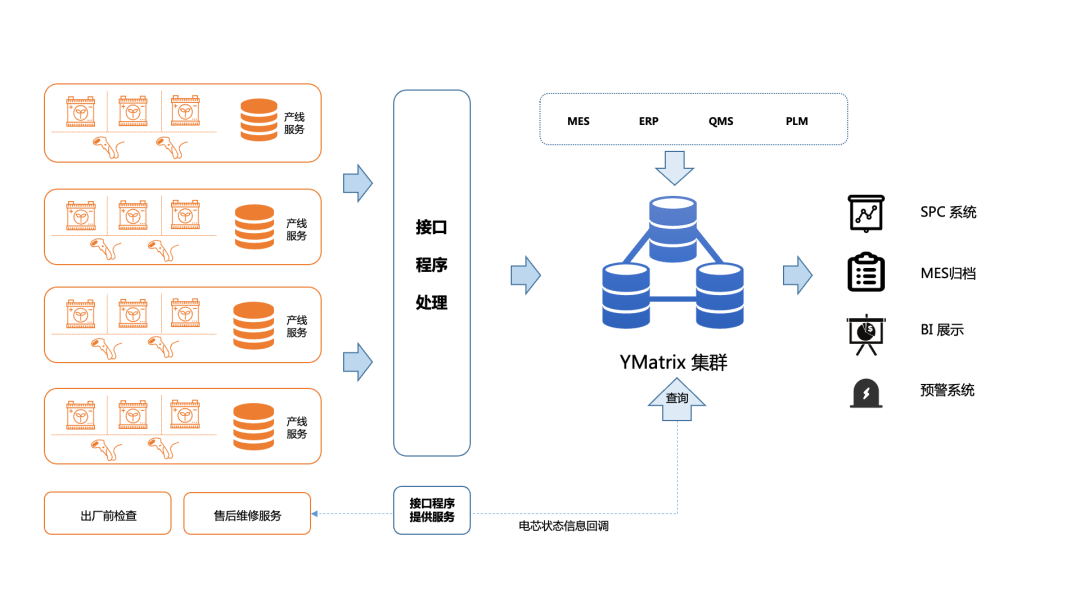
迁移后基于 YMatrix 的业务架构图
针对用户场景中的实际痛点,YMatirx 提供以下特性有效应对:
超融合架构
YMatrix 超融合架构,可以解决传统数据库的"信息孤岛"的问题,实现"一库多用"。在制造业产线场景中,一库即可完成对 ERP 数据、MES 数据、设备数据等的采集、存储、计算、建模、查询、分析的场景。
分布式 MPP 架构,又称无共享(Shared Nothing)架构。指具有两个或多个处理器协同执行一个操作的系统,每一个处理器都有其自己的内存、操作系统和磁盘。YMatrix 使用这种高性能系统架构来分布数据库的负载同时可使用系统的所有资源并行处理一个查询,以达到高性能。
高性能
YMatrix 关注全场景性能表现,包括写入能力、时序查询能力、OLAP 分析、机器学习(Machine Learning)性能以及 OLTP 能力等。
写入:流式写入工具 MatrixGate 同时支持多种数据类型的高速写入,具有高并发、分布式、流式、批量写入数据等特性,可以超越期待地满足企业时序场景下的实时入库,同时提供完整的事务保证;
YMatrix 联合 Intel 在 TPC-B 基准测试下吞吐超 150万 TPS。
高可用
故障自动转移:得益于 YMatrix 的全新自动运维机制,当集群主节点(Master)、数据节点(Segment)发生故障时,可自动切换主备节点,完成故障转移。
流式复制:Master 和 Segment 都可通过流式复制机制实现数据的高可用。
并发查询
此次需要迁移工序表、设备台账、指令单信息表、工艺表、流程设计表、指令单表、过站表等 11 张表,大约 40TB 左右的全量数据和增量数据。首先进行表结构的迁移,之后进行表数据的迁移,而表数据的迁移又分为全量和增量数据两部分。
Step1 :迁移表结构
首先需要迁移表的 DDL。在改造 DDL 时采用 YMatrix 的 MARS2 储存引擎,该引擎具有写入速度快、数据压缩率高和查询速度快等特点,而 Oracle 的数据类型和 YMatrix 的数据类型存在较大的差异:
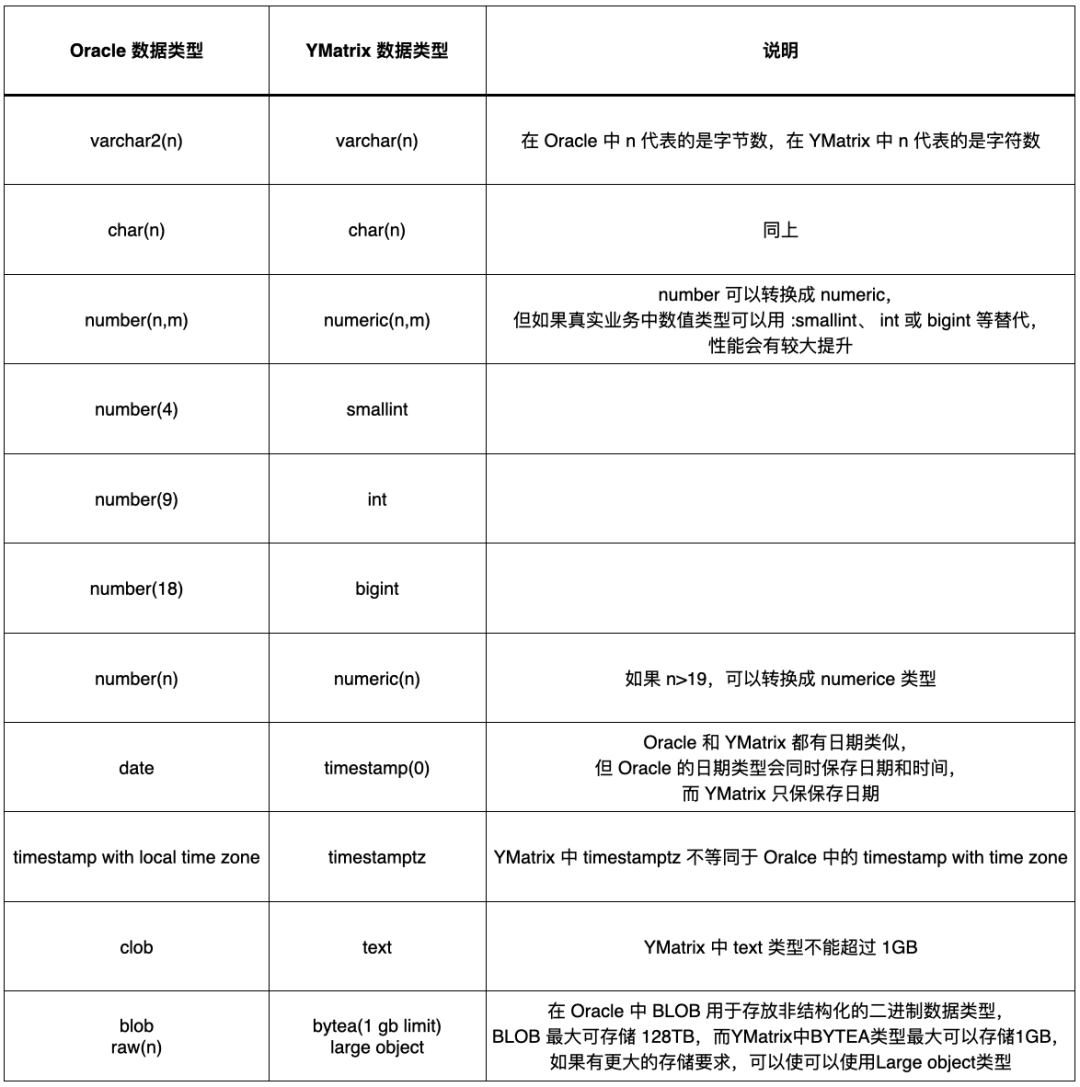
Oracle 与YMatrix 数据类型对照表
create table t_device_interface(
time timestamp,
device_number varchar2(100),
product_sn varchar2(200),
hcfr_id number
) tablespace testtablespace
partition by range (time)
interval(numtodsinterval(1,'Day'))
(
partition part_init values less than (timestamp '2022-01-01 00:00:00')
nologging
nocompress
tablespace testtablespace
);Oracle 表的结构
create table t_device_interface(
time timestamp encoding (minmax),
device_number varchar(100) encoding (minmax),
product_sn varchar(200) encoding (minmax),
hcfr_id numeric
)
USING mars2 WITH (compresstype=zstd, compresslevel=3)
DISTRIBUTED BY (device_number)
PARTITION BY RANGE (time)
(
START ('2023-01-01') INCLUSIVE
END ('2023-03-31') EXCLUSIVE
EVERY (INTERVAL '24 hour'),
DEFAULT PARTITION default_p
);
CREATE INDEX t_device_interface_index ON t_device_interface USING mars2_btree(device_number,time);YMatrix 表的结构
在改造成 YMatrix 的 DDL 时,使用了向量化与 MARS2 存储引擎结合的方式,具有写入速度快、数据压缩率高和查询速度快等特点。
Step 2: 迁移表数据
数据迁移分为全量和增量两部分进行:
全量数据:在业务低峰期时,使用 sqluldr2 工具把全量表数据导出成 CSV,然后使用高速加载工具 MatrixGate 将数据同步到 YMatrix 数据库集群中。写入速度高达 200 万行每秒,同步后的数据的压缩率高达 10.69 倍。
增量数据:采用 FlinkCDC 的方式同步:通过 FlinkCDC 读取 Oracle RAC 的多张表的 Binarylog,将变化的增量数据同步到 YMatrix 中,同步也会过滤异常数据,同步速度最高达 1200 条每秒。
在增量数据迁移的过程中,按照业务的优先级,逐步将业务也逐渐迁移到 YMatrix 上,YMatrix 和 Oracle 同时并行一段时间。最后,在测试确定能够稳定运行后,逐渐停掉 Oracle RAC 。
在真实的同步的过程中,该方案实现了长时间运行平稳,而且在整个迁移过程中,可以确保业务的正常进行,不需要让业务停掉。
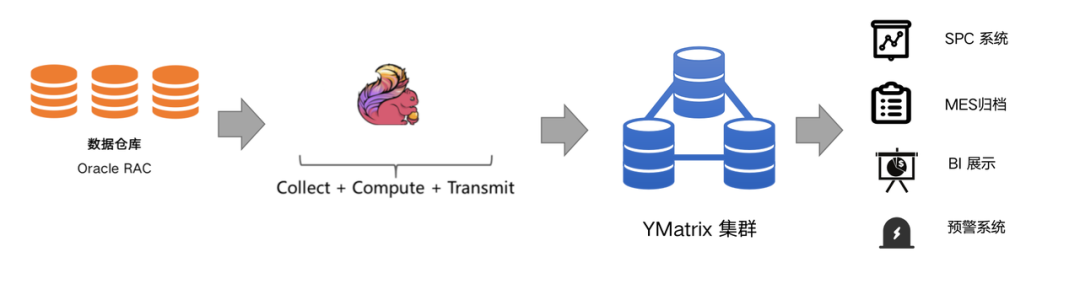 增量数据同步流程图
增量数据同步流程图
Flink 运行效果图
3-2 迁移后的效果与收益:
完成迁移后,所有业务接口程序由之前写入到 Oracle RAC 中,全部换成写入到 YMatrix数据库中,并把 Oracle RAC 中的储存函数改造成 YMatrix 的储存函数,在 YMatrix 中能兼容 80% 以上 Oracle 的函数,极大的缩减迁移的工作量。
降低储存空间
YMatrix 提供了较高的数据压缩率,有之前的 40TB+ 的数据同步到 YMatrix 后,磁盘空间仅有 3.7TB 左右,数据的压缩率为 10.69 倍,大大节省了硬件成本开销。
提高分析时效性
YMatrix 利用分布式并行的优势,在计算时最大化使用系统的资源并行处理查询,发挥集群的最高性能。在 Oracle RAC 有 150 多亿大表关联 11 张小表时需要使用 77 分钟多才出结果,在 YMatrix 中仅用1分钟半,足足提高了 47 多倍之多。甚至在 Oracle 中的复杂查询 57 分钟多的的查询在 YMatrix 也仅用 8 秒就能返回结果。
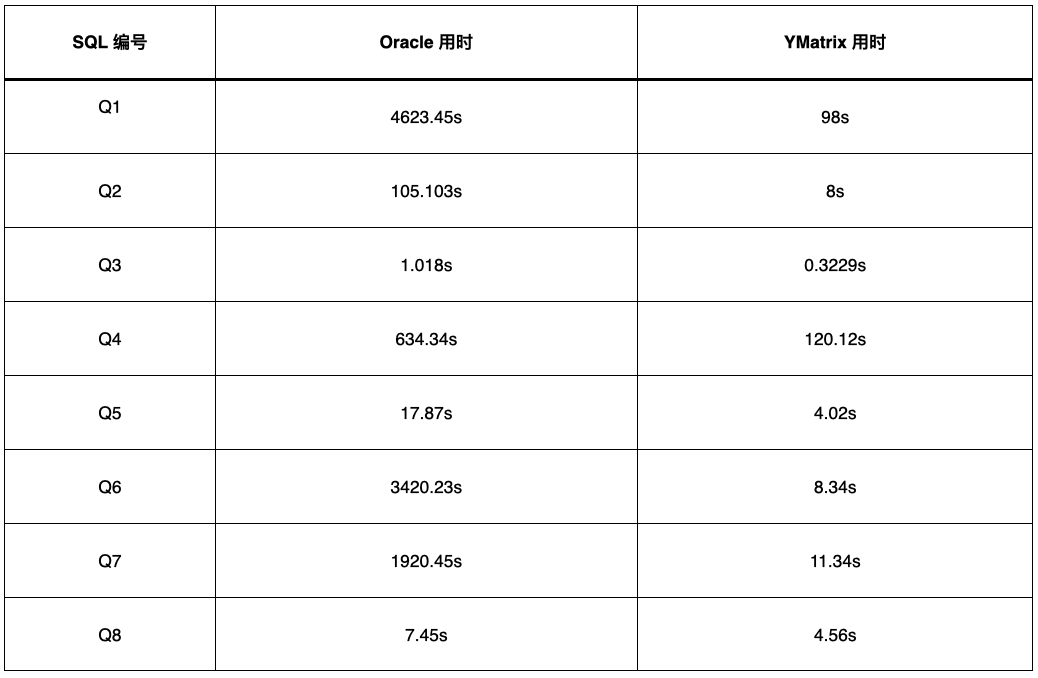
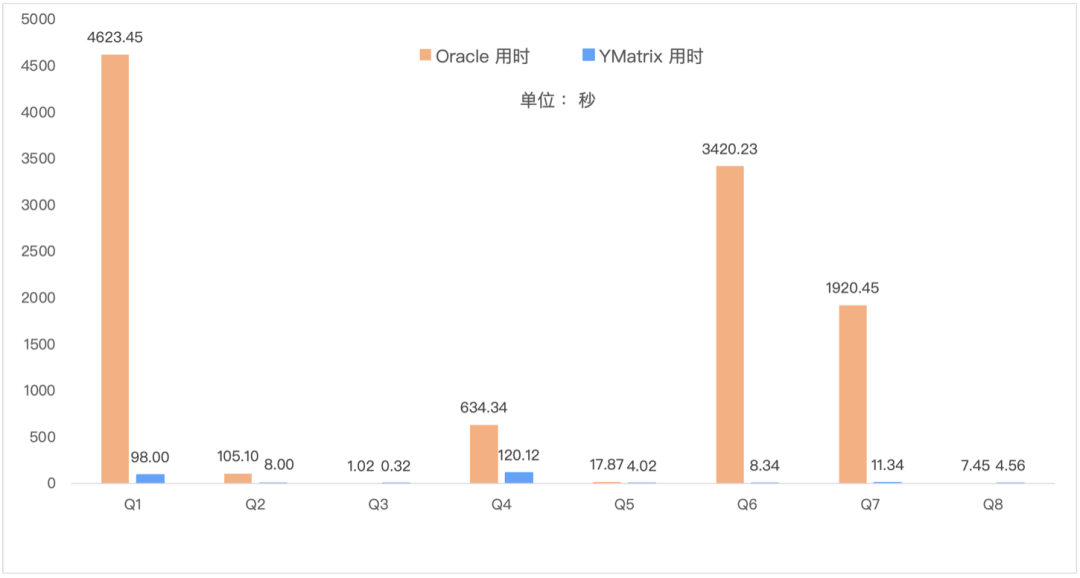
解决数据孤岛
YMatrix 超融合数据库支持时序场景、支持在线事务处理(OLTP)和在线分析处理(OLAP)的场景,一次性把 ERP、MES 等系统的数据同步到 YMatrix 中。YMatrix 具有较高的数据压缩比,节省大量硬件成本,同时使用并行的优势使计算速度更快,不再因来回搬数据而耽误业务处理的时间,影响业务的正确决策。
提高数据质量
在迁移 YMatrix 过程中解决了诸多的异常数据,数据的完整性提高,使查找数据更加准确。同时使用 YMatrix 的开发规范后,数据的保存更加合理规范,在使用数据时更加快捷高效。
节省运维成本
Oracle RAC 操作较复杂,需要多个人员共同维护。升级到 YMatrix 后具有完善的监控体系,并且数据库运维简单,一个人即可运维多套集群,极大地节省了运维成本。
完善生态兼容
YMatrix 有较完善的生态,全面支持标准 SQL,涵盖广泛的数据类型、标量表达式、查询表达式、字符集、数据分配规则、集合运算符等。支持 Java,Python、Golang、C/C++ 等语言。支持库内机器学习算法、空间数据引擎、数据联邦。
更多MARS2储存引擎介绍参考: https://ymatrix.cn/doc/5.0/reference/storage/intro
更多的压缩算法算法参考: https://ymatrix.cn/doc/5.0/reference/storage/compression
向量化执行引擎: https://ymatrix.cn/doc/5.0/reference/mxvector/overview.md






