一、实时分析需求场景正在增加
在金融交易风控、物流轨迹追踪、实时运营看板等场景中,数据分析的时效性滞后正成为企业核心痛点:
- 风险事件发生5分钟后才触发告警,损失已无法挽回
- 每日报表在T+1早晨生成,管理者错失当日决策黄金期
- 高并发查询导致系统卡顿,业务人员被迫等待响应
传统架构面临根本性局限:
- Hadoop批处理:分钟级延迟难以满足实时需求
- 单机数据库:扩展性天花板导致并发崩溃
- 流计算与数仓割裂:需维护两套系统,数据一致性难保障
MPP(大规模并行处理)架构- 凭借分布式基因脱颖而出:
- 列式存储+向量化引擎提升扫描效率 3-5倍
- 动态扩缩容能力支撑突发流量(如电商秒杀场景)
- 原生支持SQL降低开发门槛
二、优化实战:构建毫秒级响应体系
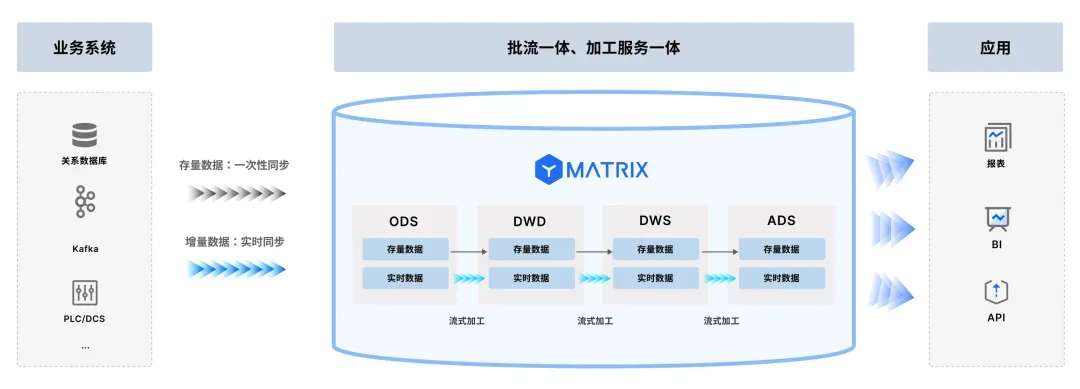
流式数据的高速通道
传统ODS层因ETL调度产生小时级延迟,现代方案通过变更数据捕获(CDC) 实现突破:
数据库日志直接实时接入MPP集群,替代中间缓冲层
结合内存优化缓冲技术,写入吞吐可达 百万条/秒(某物流企业轨迹追踪案例)
混合负载的智能治理
实时查询与批量任务资源冲突是常见瓶颈,需建立三级管控:
资源组隔离:为交易风控等关键业务分配独立计算队列
弹性扩缩容:云原生架构下,计算节点按负载自动伸缩(如促销期扩容200%)
优先级抢占:实时SQL自动中断长时批量任务
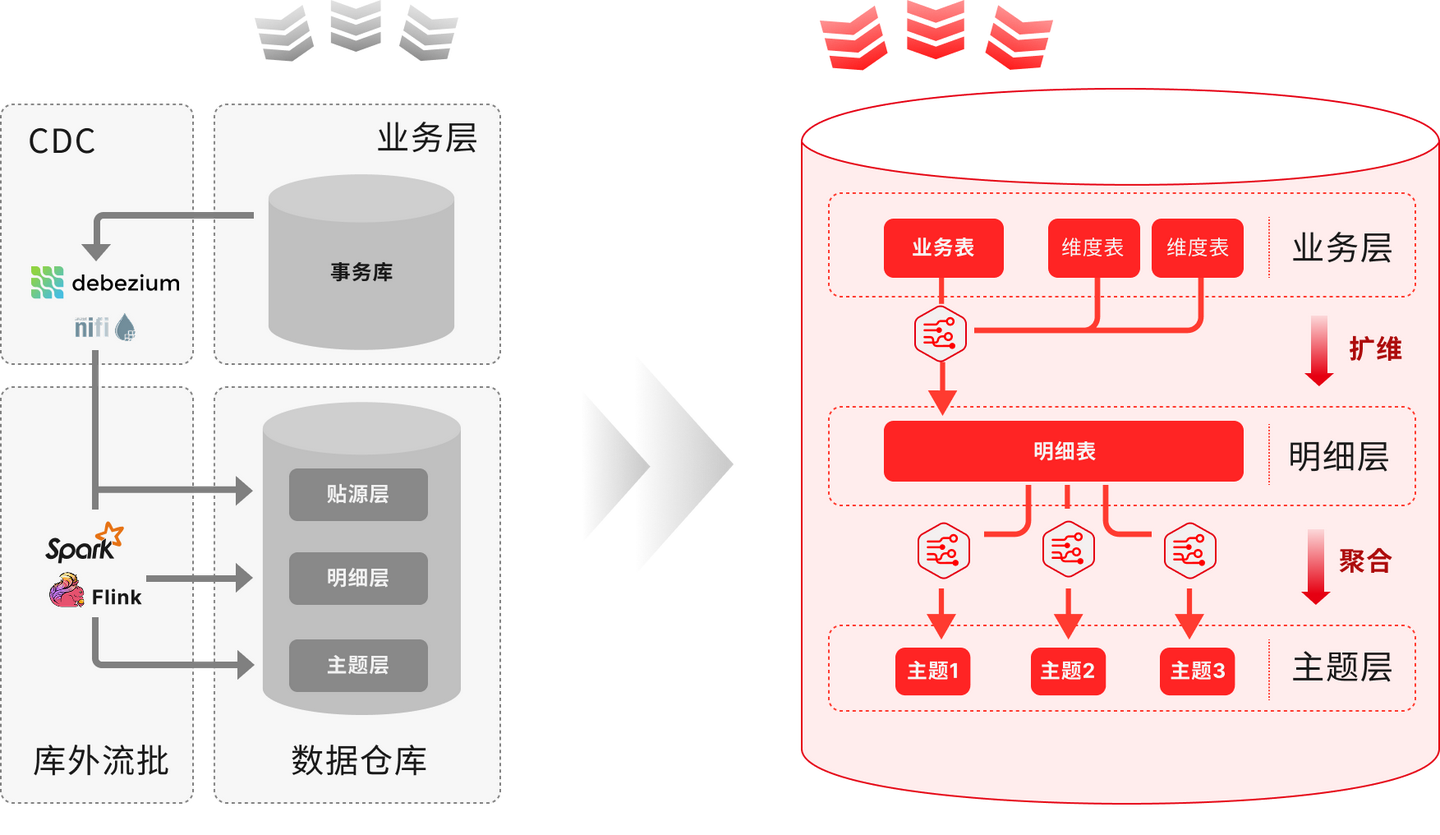
实时与历史数据的融合分析
用户行为分析等场景需同时处理实时流与历史数据,领先架构提供:
- 统一SQL接口:相同语法查询实时流(如Kafka)与历史数仓
- 增量物化视图:预计算高频指标(如每分钟GMV),查询提速百倍、
三、成本与性能的平衡
追求极致性能需警惕资源浪费,关键优化策略:
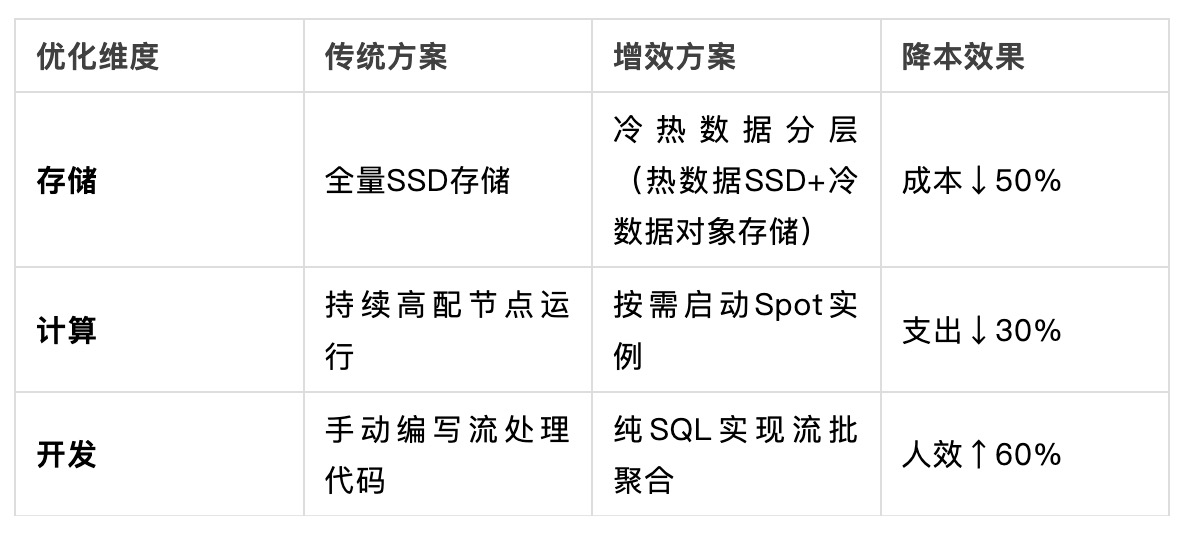
运维关键点:
- 自动化监控慢查询与数据倾斜(如自动识别热点分区)
- JIT编译技术加速高频算子,CPU利用率提升至80%+
四、企业落地路径指南
阶段1:场景化基准测试
- 选择典型实时场景建模(如风控规则匹配、实时大屏聚合)
- 压测关键指标:并发吞吐量、P99延迟、故障恢复时间
阶段2:渐进式优化四步走
- 数据接入层:用CDC替代定时ETL,延迟从小时级降至秒级
- 计算层:配置资源组隔离关键业务,避免批量任务阻塞
- 存储层:按访问频次设计冷热分区策略
- 查询层:创建增量物化视图预计算核心指标
阶段3:持续调优机制
- 通过执行计划分析定位Shuffle传输瓶颈
- 定期审查分区键避免数据倾斜(如将user_id改为user_id+时间戳)
避坑提醒:
- *避免过度分区(单分区<500MB为宜)
- 分布式事务配置选择最终一致性提升吞吐*
结语:从技术工具到业务引擎
MPP架构的实时分析优化本质是系统工程,需打通数据接入、计算调度、存储治理全链条。当技术架构具备:
✅ 流式数据秒级注入能力
✅ 混合负载智能管控
✅ 统一接口融合分析
企业才能真正将“实时数据”转化为“实时决策”,在业务竞争中赢得关键时间窗口。







